2023-05-26:论文速递
1、VideoLLM: Modeling Video Sequence with Large Language Models
VideoLLM:用大型语言模型对视频序列进行建模
《VideoLLM: Modeling Video Sequence with Large Language Models》
URL:https://arxiv.org/abs/2305.13292
单位:Nanjing University & Shanghai AI Laboratory
Official Code:https://github.com/cg1177/VideoLLM(目前只有一个 README)
动机:由于视频数据的指数增长,迫切需要自动化技术来分析和理解视频内容。现有的视频理解模型通常是针对特定任务的,缺乏处理多样任务的综合能力。借鉴大型语言模型(LLM)如 GPT 在序列因果推理方面的成功,提出一种名为 VideoLLM 的新框架,利用自然语言处理中预训练 LLM 的序列推理能力进行视频序列理解。
方法:提出 VideoLLM 框架,包括经过精心设计的模态编码器和语义转换器,将来自不同模态的输入转换为统一的 Token 序列。然后,将该 Token 序列输入到 decoder-only 的 LLM 中。接下来,通过简单的任务头,VideoLLM 为不同类型的视频理解任务提供了一个有效的统一框架。
优势:VideoLLM 将 LLM 的理解和推理能力成功应用于视频理解任务,实现了基于语言的视频序列理解。通过与语言的对齐,VideoLLM 能够同时推理语言逻辑和现实世界状态的演变,提供了一种有效的解决方案。实验结果表明,VideoLLM 在多个视频理解任务上取得了与或优于任务特定模型相媲美的性能,同时参数量相当或更少。
简介
与自然语言相比,不存在可以无缝适应不同视频序列任务的可扩展视频序列模型。这主要归因于:
与大规模视频自我监督相关的挑战,这些挑战源于 昂贵的 时间密集型视觉注释
获取和处理大量视频的过程非常 耗时
因此,迫切需要一种有效的方法,可以为涉及视频序列理解的任务提供基本的建模能力。
VideoLLM 是一种新颖的在线视频推理系统,旨在通过 参数有效的迁移学习 将大规模预训练的大型语言模型应用于视频序列理解任务。它直接将 LLM 的序列建模能力借用到视频序列推理中,让视觉以语言的形式在自然的时间序列中流动。VideoLLM 方法对齐视频和语言序列并利用 LLM 的推理和理解能力。这种范式使视频能够通过语言媒介对现实世界的事件进行推理。
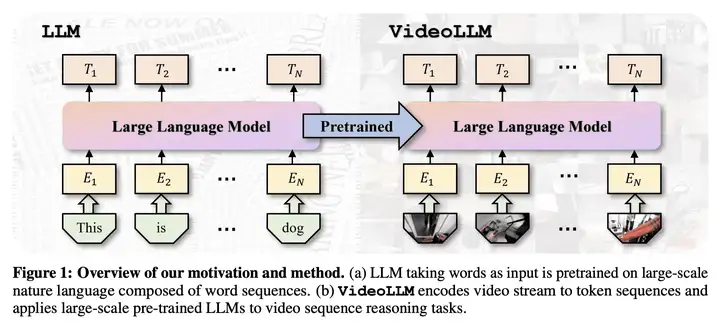
具体来说,它由三个核心组件组成:
一种对单位数据流进行编码的时间单位化方法(temporal-wise unitization method)
一个附加的语义翻译器(semantic translator),用于将视觉语义转换为语言语义
一个解码器 LLM 作为各种视频序列理解任务的通才视频序列推理器
VideoLLM
VideoLLM 的整体结构图如下所示,包含有:
Modality Encoder(模态编码器)
Semantic Translator(语义翻译器)
Decoder-only Reasoner(推理器)
simple task heads(任务头)
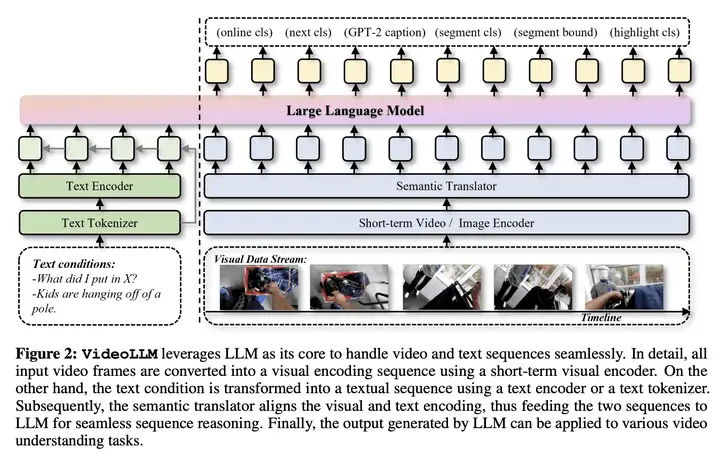
该设计允许无缝集成( seamlessly integrated)具有不同模态(例如视觉和文本)的序列任务,正如我们在实验中验证的仅视觉任务(例如时间动作检测和动作预期等)以及视觉语言任务(例如 temporal grounding 和 highlight detection 等)。
模态编码器
一个包含有 \(F\) 帧的视频序列 \(x\in R^{F\times H\times W\times C}\),其中 \(H、W、C\) 分别表示每个视频帧的 height、width 以及 通道数。作者使用短期视觉编码器 \(f_v\) 来对其进行编码,可以是成熟的图像编码器或者短期视频编码器。
给定 \(F_s\) 表示一个短期剪辑(short-term clip)中的帧数,将所有帧划分为 \(N_v = \frac{F}{F_s}\) 个时空视觉单元,每个单元由 \(f_v\) 独立编码。
因此,\(f_v\) 输出一系列时空视觉单元:
\[x_v = f_v(x) \in R^{N_v\times \frac{F_s}{s_t} \times \frac{H}{s_h} \times \frac{W}{s_w} \times d} = \{x^1_v , x^2_v , ..., x^{N_v}_v\}\]其中,\(d\) 是表示维度,\(s_t\)、\(s_h\) 和 \(s_w\) 是 \(f_v\) 内时空维度的步长。
当出现包含叙述或问题的文本输入 \(y\) 时,我们支持两种编码方法。
第一种方法涉及将 \(y\) 分词 为 \(y_t\in R^{ N_t\times d}\) ,其中 \(d\) 表示分词器的输出维度。
另一种是使用语言编码器 \(f_t\) 进一步处理 \(y_t\),例如 BERT、T5 或 CLIP,以提取 文本特征 \(y_e\)。
随后,可以将 \(y_t\) 或 \(y_e\) 作为视频序列推理器的输入,以实现基于文本条件的控制。
语义翻译器
语言模型本质上是一个 盲人,可以接收语言输入,学习各种知识,但 它没有视觉,不能直接感知视觉世界。因此,我们需要 将视觉语义转化为语言模型可以解释的语言表示。
与 Perceiver、Flamingo 和 BLIP-2 类似,我们采用 附加子网络 来传输语义空间。在本文中,出于效率的考虑,作者采用了一种更简单的设计,即 冻结视觉编码器 并将最终的视觉特征转移到语言世界中。
具体来说,给定 \(x_v \in R^{N_v\times \frac{F_s}{s_t} \times \frac{H}{s_h} \times \frac{W}{s_w} \times d_v}\)
首先,通过一个 Pooling 操作,将 \(x_v\) 的每个视觉单元合并到时间标记中,得到 \(x_t\in R^{N_v\times d_v}\)
然后,通过 一层的线性投影层 \(\phi\) 学习从视觉语义翻译到语言语义,从而获得经过翻译之后的语义
\[s_v = \phi(x_t) \in R^{N_v\times d}\]
Decoder-Only 推理器
如表 2 中所述,我们的目标是使我们的 VideoLLM 能够适应广泛的视频序列理解任务。然而,这些任务固有的不同限制,包括他们各自的投入和产出,是实现这一目标的潜在障碍。
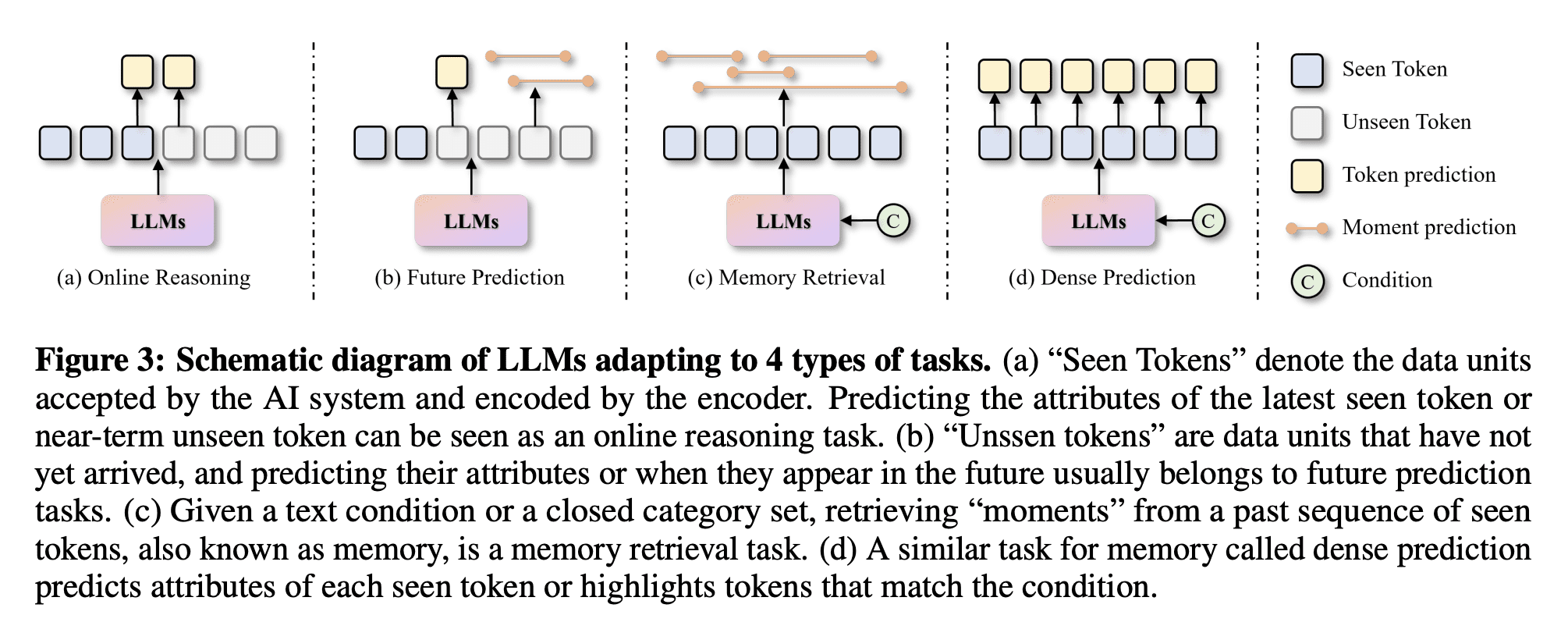
为了更好地理解这些任务的多面性,作者将它们分为四类,它们可能会出现一些重叠,如下图所示。
我们采用具有 Decoder-Only 的 LLM,表示为 \(M\),作为我们的视频序列推理器的关键组件,主要有下面三个原因:
首先,令人信服的证据表明,只有解码器的 LLM 特别擅长处理语言序列的因果推理任务
其次,当前领域中最先进和高性能的大型语言模型主要是仅解码器,并且需要研究界不断优化
第三,理想情况下,真实世界的视频处理器应该围绕单向视觉数据流进行设计,以最大限度地提高性能。这种设计理念与仅解码器语言模型的底层结构无缝结合
1)在线推理(Online Reasoning)
Online Reasoning 主要关注最近出现的数据单元的类别或标题的实时预测,在本文中它指的是一个新的短期视频剪辑。
给定正在播放的视频流和工作内存 \(m = \{s^{−t+1}_v, s^{−t+2}_v , ..., s^i_v , ..., s^0_v\}\),其中 \(t\) 是内存中看到的 token 数;\(s^0_v\) 是最新翻译的标记。
在训练阶段,将 \(m\) 输入到 \(M\) 构造因果序列 \(c=\{c^{-t+1},c^{-t+2},...,c^i,...,c^0\}\) 进行并行训练。我们使用 两个线性层 来预测每个标记 \(s^i_v\) 及其下一个标记 \(s^{i+1}_v\) 的类别。由于 decoder-only LLM 的因果结构,与双向编码器相比,我们在推理阶段接受新标记时不需要计算整个序列的上下文。
我们只让 \(s^0_v\) 交叉关注历史上下文来计算新状态 \(c^0\)。
此外,我们使用每个 \(c^i\) 作为在线字幕(online caption)的隐藏状态,并输入到额外的生成语言模型 \(M_g\)(例如 GPT-2)中 自回归地生成文本。
2)未来预测(Future Prediction)
给定一系列 已见标记 \(m = \{s^{−t+1}_v , s^{−t+2}_v , ..., s^i_v , ..., s^0_v\}\) 作为工作记忆,模型需要预测后续 \(N_f\) 个标记或事件。在这种情况下,我们仍然利用因果结构,监督每个看到的标记来学习未来的表示。为了预测不同的 \(N_f\) 个未来状态,我们使用 \(N_f\) 个 归一化层 来分离 \(N_f\) 预期表示 \(a = \{a^1 , a^2 , ..., a^i , ..., a^{N_f}\}\)。
3)记忆检索(Memory Retrieval)
记忆检索通常是一项 离线任务,用于检测封闭类别集(closed category set)或者文本条件中的事件片段。在我们的在线系统中,该任务可以评估模型对视频中段级(segment-level)过渡和演变的理解。
给定一系列已见的 token \(m = \{s^{−t+1}_v , s^{−t+2}_v , ..., s^i_v , ..., s^0_v\}\) 作为工作记忆,以获取整个视频的上下文:
我们使用 最后一个 token \(s^0_v\) 来预测内存中的 segment
另一种选择是在 \(m\) 的末尾连接一个 可学习的 token \(s^q_v\) 或
<EOT>以学习记忆摘要
为了在内存中预测最多 \(N_m\) 个类别封闭的可能段,类似于未来预测,我们使用 \(N_m\) 个 归一化层 来分离 \(N_m\) 个 segment-level 内存表示 \(m_s = \{m^1_s , m^2_s , ..., m^i_s , .. ., m^{N_m}_s \}\)。
然后我们采用 两层的线性投影层 来预测每个片段的类别和边界。通过匈牙利匹配算法将片段与 ground truth 匹配以进行监督。对于基于文本条件的记忆检索,我们在 \(m\) 的末尾连接文本表示 \(y_t\) 或 \(y_e\),并将它们一起馈送到 \(M\)。因此,\(M\) 可以生成以文本为条件的因果序列以检索匹配时刻。
4)稠密预测(Dense Prediction)
总之,我们的实验目标是评估 \(M\) 在理解视频序列方面的内在能力。为实现这一目标,我们提出了上述方法所遵循的三个基本适应原则。
首先,我们完全依靠 \(M\) 的最终输出来监督任务,而不是像一些工作那样采用多阶段监督。
其次,我们避免将卷积层等先验运算符合并到 \(M\) 中。
最后,我们为每个任务使用 线性层,将 \(M\) 生成的隐藏状态转换为任务结果,从而避免使用复杂的任务特定头。
微调预训练的 LLM 模型
VideoLLM 的训练过程涉及三种训练模型的微调方法,包括:
Basic Tuning:当使用冻结的语言模型时,VideoLLM 的优化主要集中在 微调语义翻译层和输出层
- 在这种情况下,模型的性能完全依赖于语义翻译后 LLM 的能力
Partial Tuning:采用三种设置进行部分微调,包括:
优化所有偏置参数(all bias),也就是 BitFit
优化第一个块(first block)
优化最后一个块(last block)
PEFT Tuning:参数高效的微调技术,包括:
LoRA
Prompt Tuning
Prefix Tuning
实验
LLM、数据集和任务
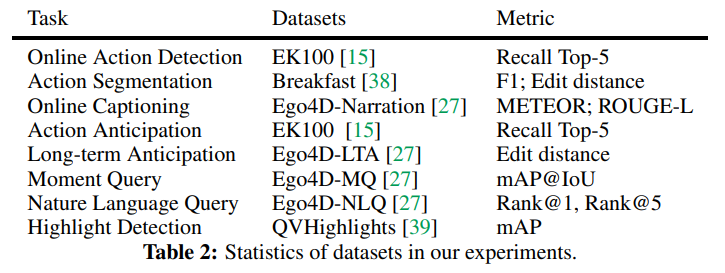
分析一:Which language model performs better?
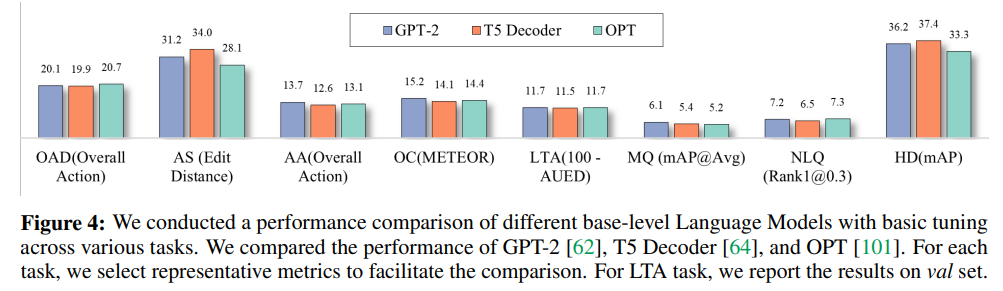
分析二:Which Tuning method performs better?
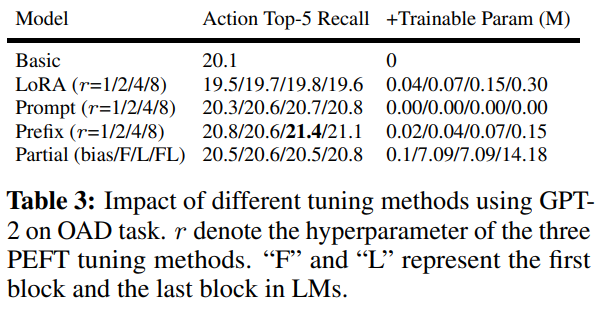
如表中所示,使用具有不同 \(r\) 的 LoRA 会导致性能下降。相反,其他调优方法在 Action Top-5 Recall 指标中表现出至少 0.2 点的性能改进。
尽管微调第一个或最后一个块可以提高性能,但与其他方法相比,它还需要大量的可训练参数。
值得注意的是,当使用 \(r = 4\) 的前缀调整时,该模型取得了最好的结果,获得了 21.4 的 Action Top-5 Recall,比基本调整方法高出 1.3 个百分点。
分析三:对比 SOTA 方法

分析四:扩展 LLM
我们还通过对 OAD 任务进行的实验,评估了利用 LLM 作为我们方法的视频序列推理器的可扩展性。
下图展示了通过使用具有不同总参数规模的 LLM 实现的 Action Top-5 Recall。在这些实验中,我们扩大了三个仅包含解码器的 LLM,即 GPT-2、T5 Decoder 和 OPT,并使用 basic tuning 方法单独微调了两个线性投影层,这确保了对这些 LLM 所拥有的 内在能力 进行全面的评估。
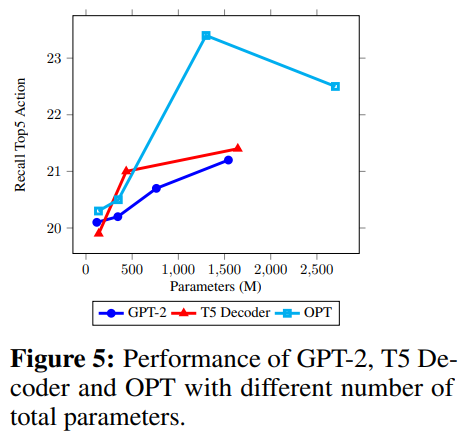
当使用参数小于 2B 的语言模型时,实验结果表明,更大的模型在视频序列推理方面产生了更大的改进。并且,OPT-1.3B 模型的提升效果最明显。
OPT > T5 Decoder > GPT-2
然而,对于更大的 LLM,他们的性能开始下降。对这种现象的一个合理解释是:线性投影层的维度扩展 导致模型 过拟合,因为提取的特征序列的维度通常小于 2048。
此外,我们还进一步将 OPT 和 T5 Decoder 扩展到 6.7B,并利用最新的 7B LLaMA 模型。如表 5 所示,T5 Decoder 和 OPT 的性能继续与图 5 中观察到的下降趋势保持一致。值得注意的是,LLaMA 的性能与 OPT 的性能非常接近。

分析五:Encoder VS Decoder
我们进行了实验来比较双向和单向序列推理器在三个任务上的性能:AS、HD 和 NLQ。对于双向序列推理器,我们使用了 T5 编码器,而单向序列推理器使用了 T5 解码器,实验结果如下表所示。
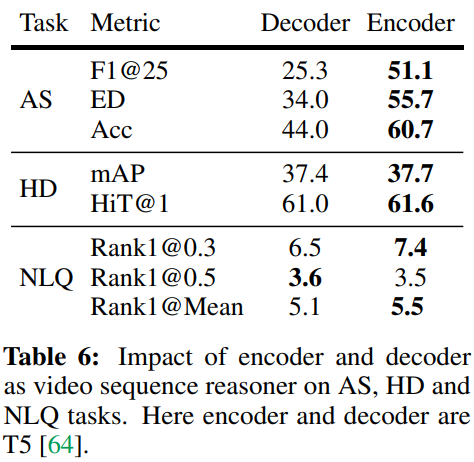
从表中可以明显看出,双向推理器(Encoder)在大多数情况下始终优于单向推理器(Decoder)。这种差异在 AS 任务中尤为突出,其中 Encoder 与 Decoder 相比表现出明显更高的性能水平。这可能归因于 双向注意力 在动作分割期间确认完整事件内的时间相关性和动作前后关系的重要性。
在视觉语言任务、HD 和 NLQ 的情况下,Encoder 也比 Decoder 略有优势。
同时,值得注意的是,如图 4 所示,OPT 在 NLQ 任务上获得的 Rank1@0.3 与 T5 编码器获得的 Rank1@0.3 相当(7.3 对 7.4)。这表明仅解码器的 Decoder 有可能实现与 Encoder 同等的性能。
2、Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Sophia: 面向语言模型高效预训练的 可扩展随机二阶优化器

《Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training》
URL:https://arxiv.org/abs/2305.14342
单位:Stanford University
Official Code:https://github.com/Liuhong99/Sophia
动机:减少语言模型预训练的时间和成本。
方法:提出一种名为 Sophia 的可扩展二阶优化器,使用轻量对角 Hessian 估计作为预条件器,并通过剪切机制控制最坏情况下的更新大小。
优势:与 Adam 相比,在 GPT-2 等语言模型的预训练中,Sophia 在步数、总计算量和挂钟(wall-clock)时间方面实现了 2 倍的加速。
简介
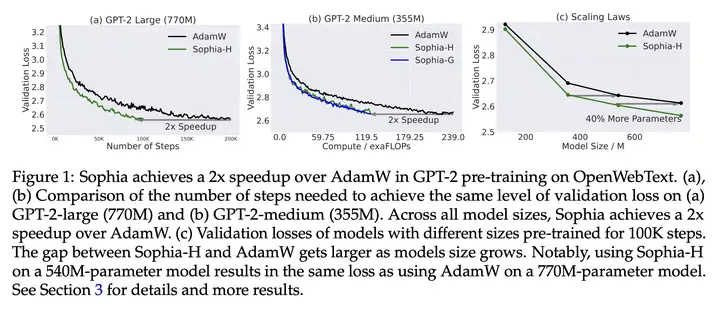
Sophia 优化器使用随机估计作为 Hessian 矩阵对角线的 pre-conditioner,并采用剪切(clipping)机制来控制最坏情况下的参数大小更新。在像 GPT-2 这样的预训练语言模型上,Sophia 与 Adam 相比,在减少了 50% step 数量的情况下实现了相同的验证预训练损失。
由于 Sophia 可以维持每个 step 内的的内存和所用时间,这相当于总计算量减少了 50%,wall-clock 时间减少了 50%(参见图 1 (a) 和 (b))。此外,根据扩展定律(从模型大小的角度),在 125M 到 770M 的模型上,Sophia 相对于 Adam 更具优势,并且随着模型大小的增加,Sophia 和 Adam 差距也在增加(在 100K step 内)(图 1(c))。特别的,在 540M 参数模型上(100K step),Sophia 和具有 770M 参数模型上的 Adam 实现了相同的验证损失。需要注意的是,后者需要多达 40% 的训练时间和 40% 的推理成本。
方法
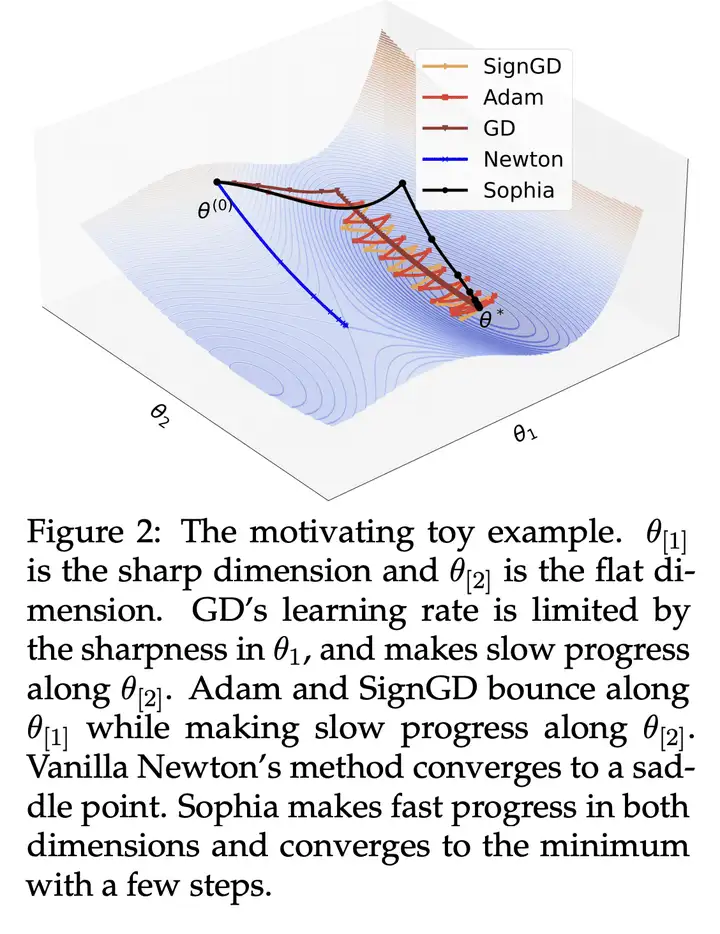
至于该研究的动机,作者表示 Adam 对于异构曲率(heterogeneous curvatures)的适应性不足。另一方面,vanilla Newton 方法在凸函数中具有最优的 pre-conditioner,但对于负曲率和 Hessian 的快速变化容易受到影响。基于这些见解,该研究设计了一种新的优化器 Sophia,它比 Adam 更适应异构曲率,比 Newton 方法更能抵抗非凸性和 Hessian 的快速变化,并且还使用了成本较低的 pre-conditioner。

实验
研究将使用 Hutchinson 估计器和 GNB 估计器的算法分别称为 Sophia-H 和 SophiaG。本文用 GPT-2 评估了 Sophia 的自回归语言建模,模型尺寸从 125M 到 770M 不等。结果表明,Sophia 在 step、总计算量和所有模型大小的 wall-clock 时间方面比 AdamW 和 Lion 快 2 倍。此外,扩展定律更有利于 Sophia 而不是 AdamW。



比较 wall-clock 时间与计算量。表 1 比较了每一个 step 的总计算量 (TFLOPs) 和 A100 GPU 上的 wall-clock 时间。本文报告了每个 step 的平均时间,Hessian 计算花费的时间的总计算。较小的批量大小,即每 10 个 step 以计算对角 Hessian 估计,Hessian 计算占总计算量的 6%,与 AdamW 相比,整体 wall-clock 时间开销小于 5%。在内存使用方面,优化器 m 和 h 两个状态,这导致了与 AdamW 相同的内存开销。

在 30M 模型上,执行网格搜索来测试 Sophia-H 对超参数的敏感性 (图 7 (c))。所有组合的性能相近,但 \(β_2 = 0.99\) 和 \(ρ = 0.1\) 的性能最好。此外,这种超参数选择可以跨模型大小迁移。对于 125M、355M 和 770M 的所有实验,都使用了 30M 模型上搜索超参数 \(ρ = 0.01, β_2 = 0.99\)。

训练稳定性。与 AdamW 和 Lion 相比,Sophia-H 在预训练中具有更好的稳定性。梯度裁剪 (by norm) 是语言模型预训练中的一项重要技术。在实践中,梯度裁剪触发的频率与训练的稳定性有关 —— 如果梯度被频繁裁剪,迭代可能处于非常不稳定的状态。图 7 (a) 比较了 GPT-2 (125M) 触发梯度裁剪的 step 比例。尽管所有方法都使用相同的裁剪阈值 1.0,但 Sophia-H 很少触发梯度裁剪,而 AdamW 和 Lion 在超过 10% 的 step 中触发梯度裁剪。
代码
参考:Sophia
import torch
from torch import nn
from sophia import SophiaG
# init model loss function and input data
model = Model()
data_loader = ...
# init the optimizer
optimizer = SophiaG(model.parameters(), lr=2e-4, betas=(0.965, 0.99), rho = 0.01, weight_decay=1e-1)
k = 10 # 每 10 个 step 更新一次 hessian
iter_num = 0
# training loop
for epoch in range(epochs):
for X,Y in data_loader:
# 不更新 hessian
if iter_num % k != k - 1:
# standard training code
logits, loss = model(X, Y) # 获取模型的输出和 loss
loss.backward()
optimizer.step(bs=4096)
optimizer.zero_grad(set_to_none=True)
iter_num += 1
else:
# standard training code
logits, loss = model(X, Y)
loss.backward()
optimizer.step(bs=4096)
optimizer.zero_grad(set_to_none=True)
iter_num += 1
# update hessian EMA
logits = model(X, None) # 获取模型的输出
samp_dist = torch.distributions.Categorical(logits=logits)
y_sample = samp_dist.sample()
loss_sampled = cross_entropy(logits, y_sample)
loss_sampled.backward()
optimizer.update_hessian()
optimizer.zero_grad(set_to_none=True)
3、Gorilla: Large Language Model Connected with Massive APIs
Gorilla: 与大量 API 相连的大型语言模型
《Gorilla: Large Language Model Connected with Massive APIs》
网站:gorilla.cs.berkeley.edu
URL:https://arxiv.org/abs/2305.15334
Official Code:https://github.com/ShishirPatil/gorilla/
Gorilla Spotlight Waitlist:https://t.co/rvmk13Mhrx
Discord Community:https://discord.gg/pWeBheVY7n
单位:UC Berkeley & Microsoft Research

动机:解决大型语言模型(LLM)在使用 API 调用时存在的问题,包括无法生成准确的输入参数和错误使用 API 调用的倾向。
方法:使用自我指导的微调和检索技术,使 LLM 能准确选择大规模、重叠且不断变化的API工具集,并构建了包含 HuggingFace、TorchHub 和 TensorHub API 的综合数据集 APIBench。
优势:Gorilla 模型在 API 功能准确性和减少错误的幻觉方面明显优于 GPT-4,同时通过与文档检索系统的集成,能够适应 API 文档的变化,提高 LLM 与工具的可靠性和适用性。

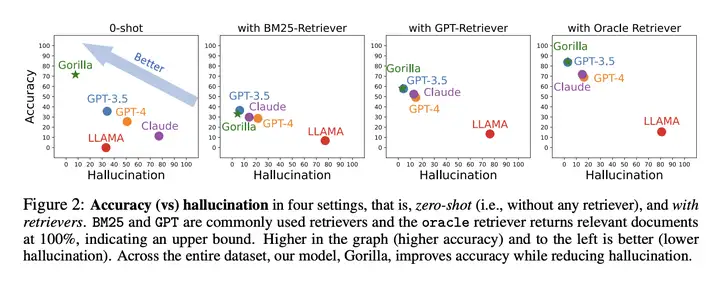
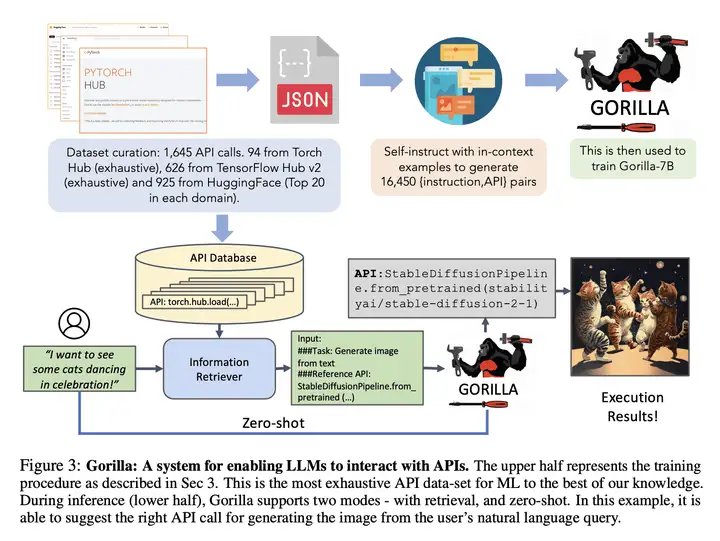
上图中,
上半部分是训练过程。研究者表示这是目前最详尽的机器学习 API 数据集。
下半部分是推理过程;Gorilla 支持两种模式:使用检索和零样本(无检索)。
- 在这个具体示例中,用户查询的是基于自然语言生成图像,模型能够建议出合适的 API。
用于评估 API 调用的 AST 子树匹配示意图如下所示:

更多
1、Aligning Large Language Models through Synthetic Feedback
基于合成反馈的大型语言模型对齐
《Aligning Large Language Models through Synthetic Feedback》
URL:https://arxiv.org/abs/2305.13735
Official Code:None
单位:NAVER Cloud
动机:解决将大型语言模型(LLM)与人类价值观对齐的问题,避免其产生有害行为,并减少对人类示范和反馈的依赖。
方法:通过引入合成反馈,构建高质量的比较和示范数据集,训练一个对齐的策略,并使用强化学习来进一步优化模型,得到一个对齐的 LLM 模型:Aligned Language Model with Synthetic Training dataset (ALMoST)。
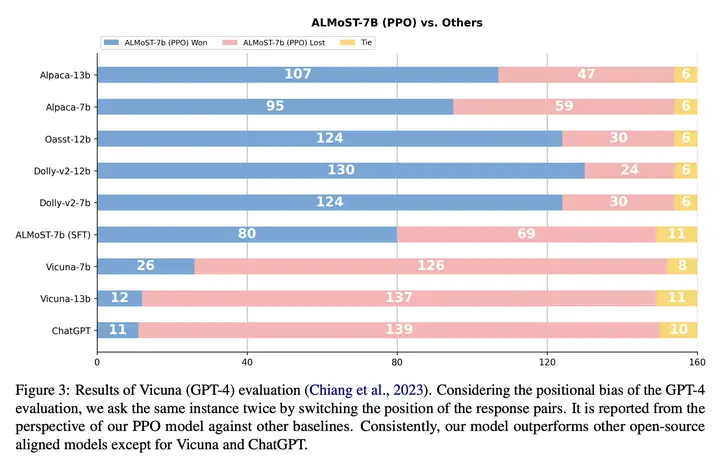
优势:提出了一种 新的对齐学习框架,几乎不需要人类劳力,并且不依赖预先对齐的 LLM。所提出的模型在各种评估中表现出与人类价值观良好对齐的行为,并在对齐基准测试中 超过了现有的开源模型。
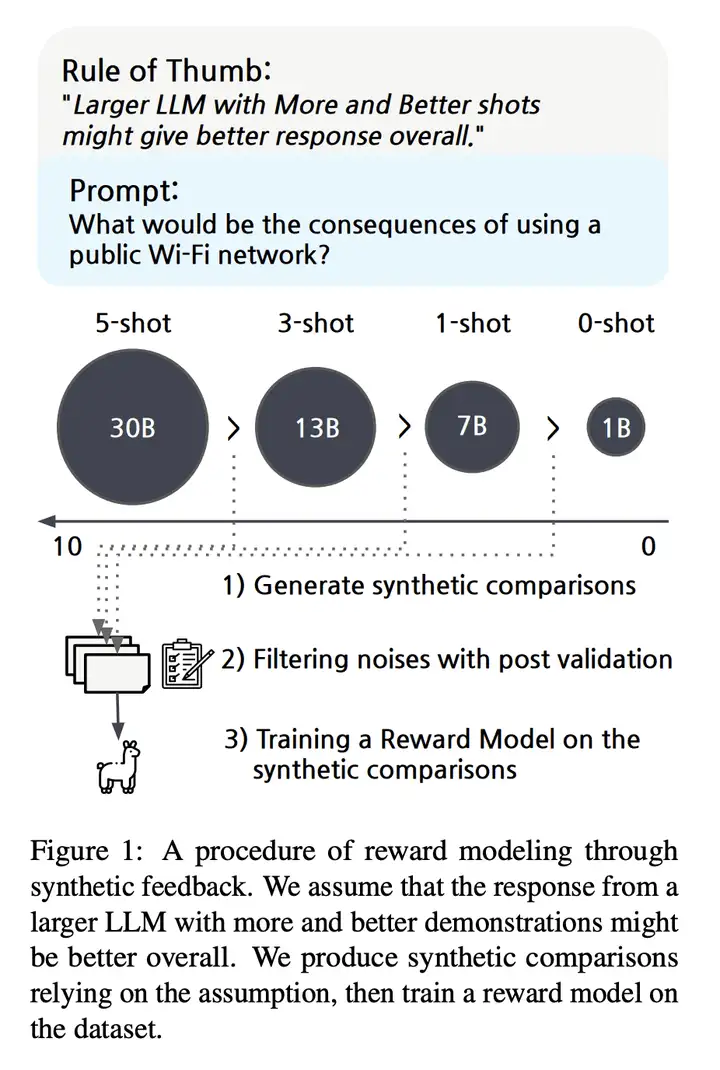
经验法则(rule of thumb):来自具有 更多更好 示例(demonstrations)的 更大 LLM 的响应总体上可能更好
根据这个经验法则,使用不同规模的模型来生成 “排序好” 的响应结果,从而指导模型与 “人类对齐”。
我们提出的 LLM 对齐学习的框架图如下所示:
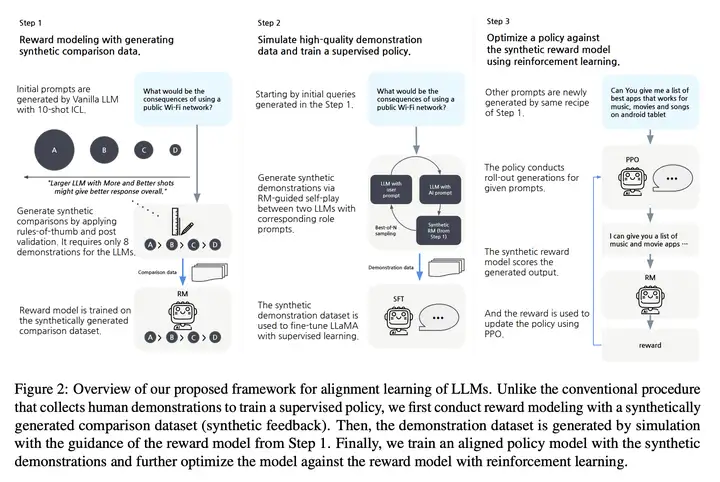
与收集人类示范以训练监督政策的传统程序不同,我们首先使用综合生成的比较数据集(综合反馈)进行奖励建模。
然后,在步骤 1 的奖励模型的指导下,通过仿真生成演示数据集。
最后,我们使用综合示例训练了一个对齐的策略模型,并通过强化学习针对奖励模型来进一步优化模型。
2、A PhD Student’s Perspective on Research in NLP in the Era of Very Large Language Models
在大语言模型时代,博士生的 NLP 研究建议
《A PhD Student’s Perspective on Research in NLP in the Era of Very Large Language Models》
URL:https://arxiv.org/abs/2305.12544
Official Code:https://bit.ly/nlp-era-llm
单位:密歇根大学
动机:解决当前关于自然语言处理(NLP)研究领域的误解和困惑,避免将整个 NLP 领域仅仅局限于大型语言模型(LLM)。
方法:通过编译一份梳理 NLP 研究方向的文档,汇集来自不同背景的博士生的意见和建议,探索那些丰富的研究方向。
优势:为正在从事 NLP 研究的人提供了广泛的研究领域选择,避免将研究局限于 LLM。
3、”According to …” Prompting Language Models Improves Quoting from Pre-Training Data
《”According to …” Prompting Language Models Improves Quoting from Pre-Training Data》
URL:https://arxiv.org/abs/2305.13252
Official Code:https://github.com/JHU-CLSP/according-to(目前只有一个 README)
单位:约翰霍普金斯大学
动机:解决大型语言模型产生错误信息和幻觉的问题,通过引入 “according-to prompting” 方法,使模型的回应与之前观察到的文本进行对接。
方法:使用 “according-to prompting” 方法 引导语言模型生成更为基于事实的信息,并引入 新的评估指标 QUIP-Score 来衡量模型生成的答案在底层文本语料中的相关性。
优势:该方法简单且有效,能够改善大型语言模型生成更为基于事实的信息,提供了衡量生成结果相关性的新指标。
“according to” prompt 的示意图如下所示:
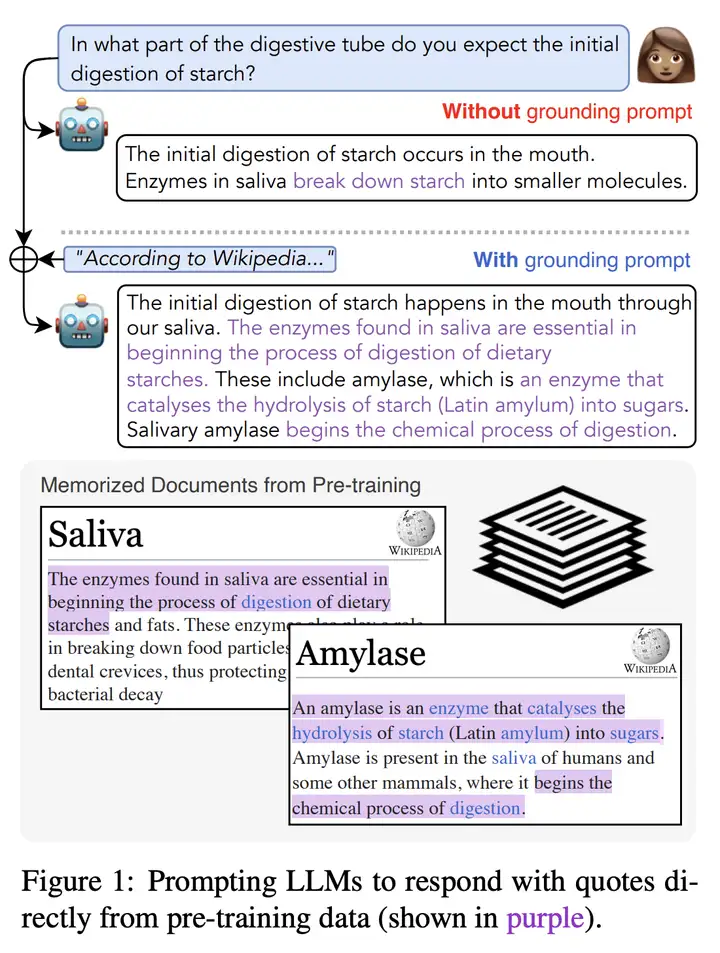
In what part of the digestive tube do you expect the initial digestion of starch?
您预计淀粉会在消化管的哪个部分进行初始消化?
The initial digestion of starch occurs in the mouth. Enzymes in saliva break down starch into smaller molecules.
淀粉的初始消化发生在口腔中。唾液中的酶将淀粉分解成更小的分子
The initial digestion of starch happens in the mouth through our saliva. The enzymes found in saliva are essential in beginning the process of digestion of dietary starches. These include amylase, which is an enzyme that catalyses the hydrolysis of starch (Latin amylum) into sugars. Salivary amylase begins the chemical process of digestion.
淀粉的初始消化通过我们的唾液在口腔中发生。唾液中的酶对于启动膳食淀粉的消化过程至关重要。其中包括淀粉酶,它是一种催化淀粉(拉丁淀粉)水解成糖的酶。唾液淀粉酶开始消化的化学过程。
其中,紫色表示的是:相应的文本在预训练的 Wikipedia 数据中出现过。也就是说,模型给出的结果参考了多少预训练的数据。
Null Prompt、According-to Prompt(Grounding Prompt) 以及 anti-Grounding Prompt(反提示,negative prompt) 的实验结果如下图所示:
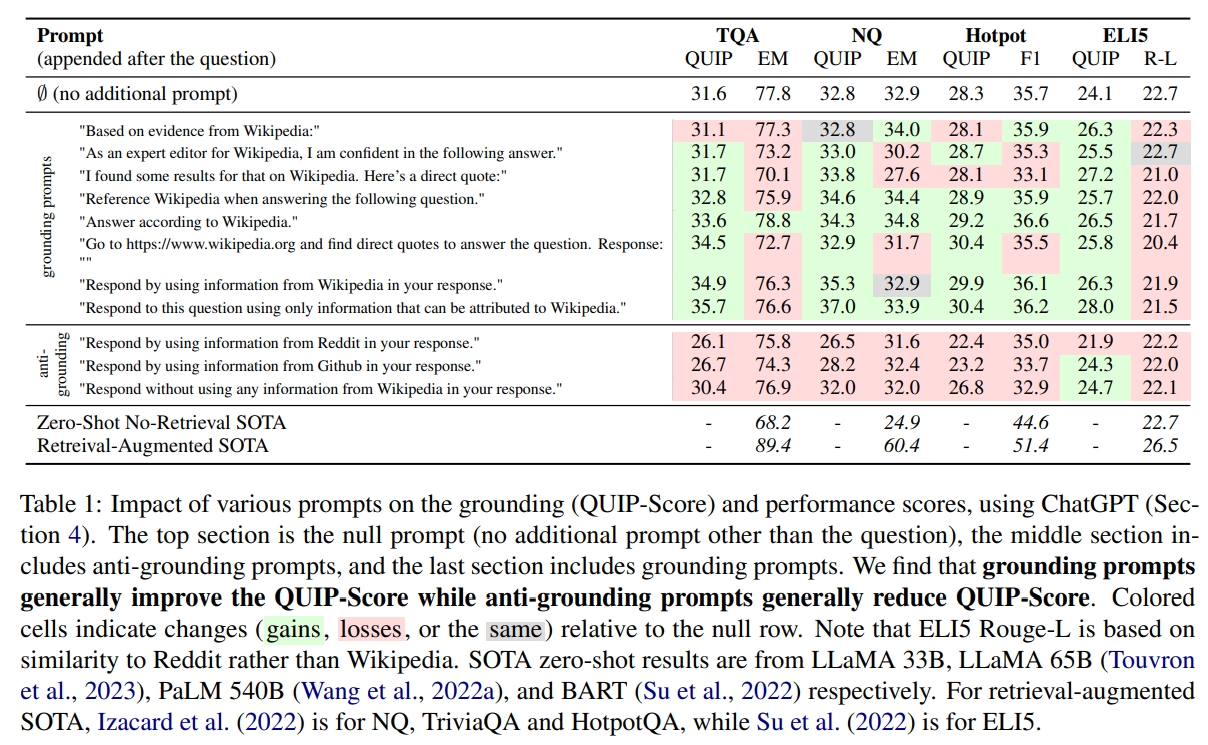
其中,绿色表示相较于 NUll Prompt 的性能有提升,而红色则表示(相较于 Null Prompt)性能下降。
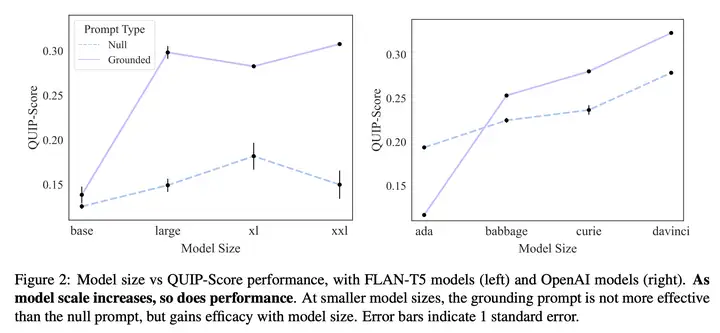
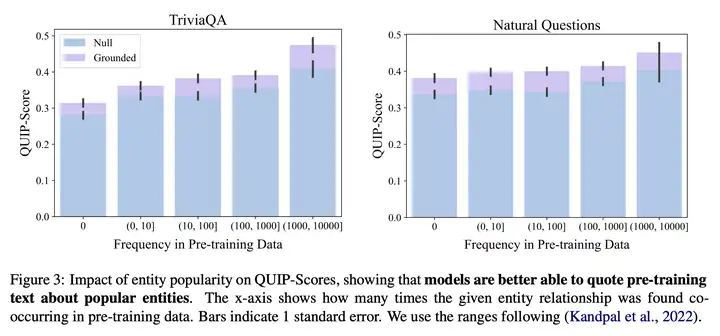
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-05-26-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)