2023-05-13:论文速递
1、InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
InstructBLIP:基于指令微调的通用视觉-语言模型
《InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning》
URL:https://arxiv.org/abs/2305.06500
Official Code:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
单位:Salesforce Research
动机:构建通用的视觉-语言模型是具有挑战性的,因为额外的视觉输入引入了任务差异,目前关于 视觉-语言指令微调 的研究相对较少。
方法:在 预训练的 BLIP-2 模型 基础上进行了系统全面的视觉-语言指令微调研究,提出了指令感知的视觉特征提取方法,使模型能够根据给定指令提取有信息量的特征。
优势:InstructBLIP 模型在多个任务上取得了最先进的零样本性能,并且在单个下游任务上的微调表现也领先于其他模型。
数据集
作者使用了下面多种任务的数据集,如下图所示:
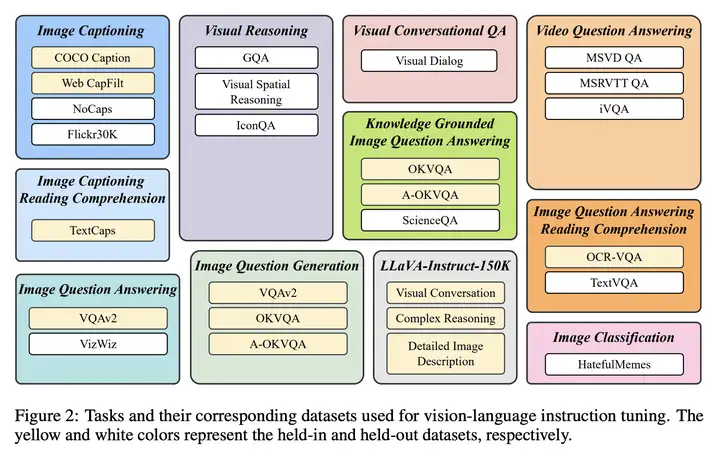
作者联合上面的数据集,为不同的任务设置了不同的 Instruction Template,如下图所示:

为了更好的验证性能,把验证集分割为两部分:
Help-in:训练中见过此类任务,但是没见过这个样本,用于测试在相同任务 unseen 数据的性能。
Help-out:训练集没见过此类任务,用于测试在 unseen task 的unseen sample 的 迁移能力。
如果涉及到文本-图像,增加 OCR token。
Dataset Balance
由于作者混合多个数据集,每个数据集的大小不同,如果采用均匀采样,可能会造成大数据集 underfitting,小数据集 overfitting。所以作者 对不同的数据集采取不同的 sample 比例。
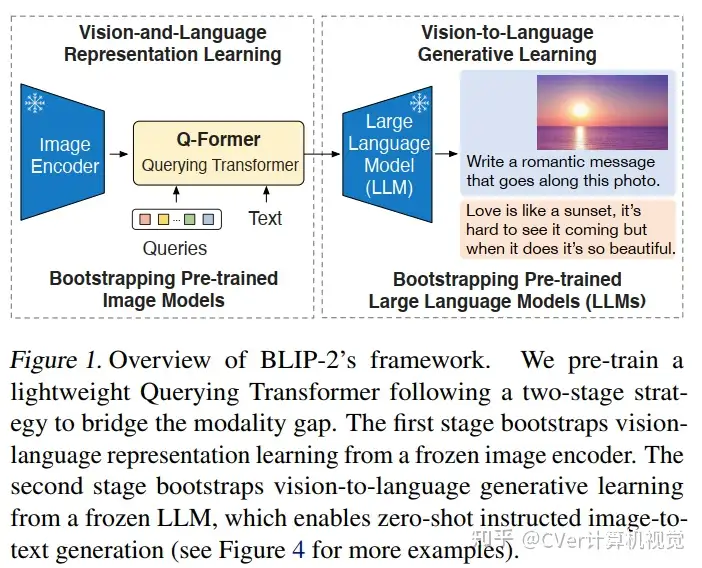
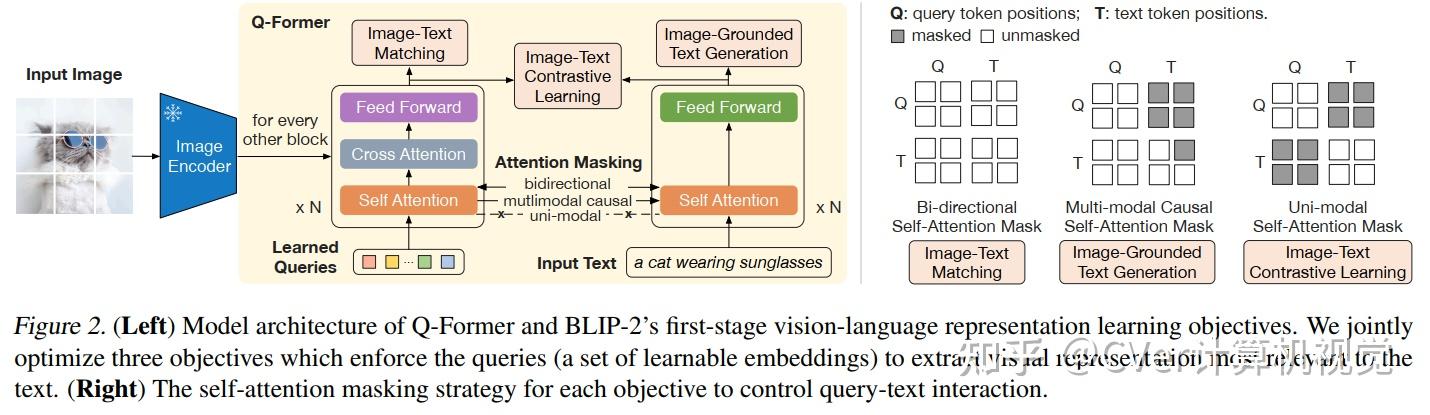
方法:Instruction-aware Visual Features
InstructBLIP 的架构图如下所示:
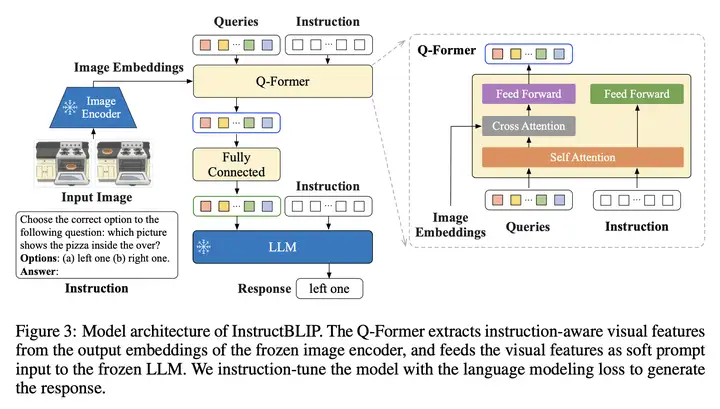
InstructBLIP 是从一个预训练的 BLIP-2 模型初始化的,主要由一个图像编码器、一个 LLM 和一个连接两者的 Q-Former 组成。
在指令调优期间,我们 微调 Q-Former,同时保持图像编码器和 LLM 冻结。
首先是 数据 上的变化:
用相同的图像采取不同的 instruction
不同的图像采取相同的 instruction
这应该是增加泛化的一种方式。
然后是 结构 上的变化:Image Encoder、LLM 都被冻结,只微调 Q-former
与 BLIP-2 不同的是:作者在 Q-former 阶段与 LLM 阶段都输入了 Instruction
由于在 BLIP-2 预训练 Q-former 时,它就可以提取文本特征,然而到了推理阶段,就把这个 Instruction 放到了 LLM 侧
在 Q-former 阶段引入 Instruction 可以在计算 self-attention 的时候,learnable query 也考虑了 instruction 来抽取 image encoder 的特征
实验结果
InstructBLIP 的实验结果如下图所示:

作者也通过实验证明了 Dataset Balance 和 Instruction-aware Visual Features 的有效性,如下图所示:

例子

2、Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting
并非所有语言在 LLM 中都是平等的:通过 跨语言思维提示 来提高 LLM 模型的多语言能力
《Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting》
URL:https://arxiv.org/abs/2305.07004
单位:Microsoft Research Asia、Renmin University of China
动机:大型语言模型(LLM)在多语言环境下表现出令人印象深刻的多语能力,但它们在不同语言之间的性能差异很大。
方法:引入一种简单而有效的方法,称为 跨语言思维提示(cross-lingual-thought prompting,XLT),以系统地提升 LLM 的多语能力。XLT 是一个通用的模板提示,通过激发跨语言和逻辑推理能力,提高各种语言上的任务性能。
优势:XLT 显著提升了各种多语任务的性能,并在不同语言的每个任务的平均表现和最佳表现之间显著缩小了差距。尤其在算术推理和开放域问答任务中,XLT 带来了超过 10 个百分点的平均改进。
XLT 的总体框架图如下所示:

XLT 的 Prompt 模板如下所示:

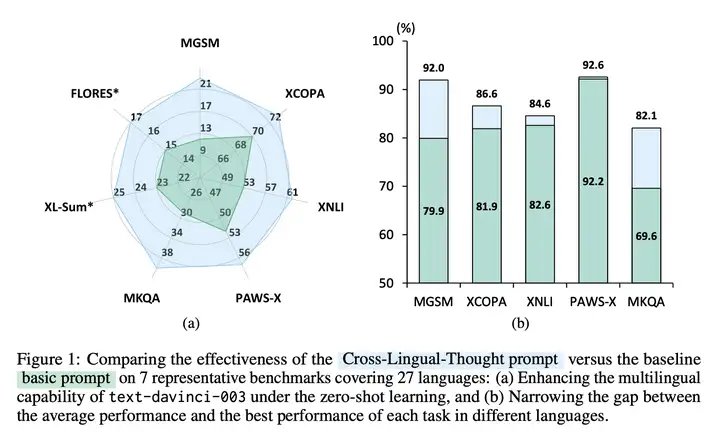
更多
1、Bot or Human? Detecting ChatGPT Imposters with A Single Question
机器人还是人类? 用一个问题检测 ChatGPT 机器人
《Bot or Human? Detecting ChatGPT Imposters with A Single Question》
URL:https://arxiv.org/abs/2305.06424
Official Code:https://github.com/hongwang600/FLAIR(检测数据集)
单位:University of California Santa Barbara、Xi’an Jiaotong University
动机:大型语言模型的出现在自然语言理解和生成方面展示了令人印象深刻的能力,但人们担心它们可能被用于恶意目的,因此需要开发方法来 检测对话中的机器人和人类。
方法:提出一个名为 FLAIR(Finding Large Language Model Authenticity via a Single Inquiry and Response)的检测框架,通过 单个询问和回答 来检测 在线对话 中的对话机器人。通过设计一系列特定的问题,利用机器人和人类处理和生成语言的差异来区分二者。
优势:FLAIR 检测框架有效地区分了人类用户和对话机器人,为在线服务提供商保护自己免受恶意活动的侵害,并确保为真实用户提供服务。
我们针对一个可以有效区分人类用户和机器人的 单一问题场景。这些问题可以分为两类:
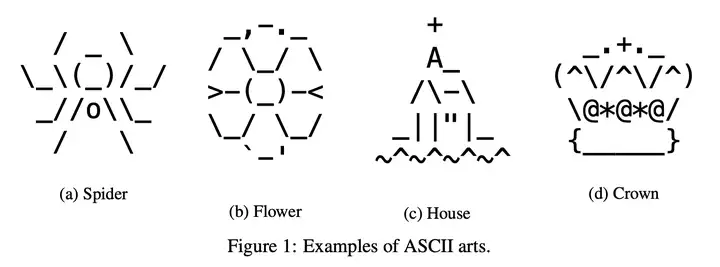
对人类来说容易但对机器人来说困难的问题:例如,计数(counting)、替换(substitution)、定位(positioning)、噪声过滤(noise filtering)和 ASCII 艺术(ASCII art)
对机器人来说容易但对人类来说困难的问题:例如,记忆(memorization)和计算(computation)
如下图所示:

FLAIR 数据集
来源:https://github.com/hongwang600/FLAIR
利用 LLM 的短板(不擅长)
counting:
[
# 字母计数
{
"question": "What is the number of i in iiijijjjiqqqqjqiqiqjqjjjiiqiji?",
"answer": "11"
},
...
]
substitution:
[
# 字母替换
{
"question": "Use s to substitute c, h to substitute r, o to substitute a, c to substitute s, k to substitute h, how to spell \"crash\" under this rule?",
"answer": "shock"
},
...
]
positioning:
[
# 定位某个字符在一个字符串中的位置
{
"question": "What is the 1-th character after the 1-th apperance of the character x in the string budouodkbmdkmubukyxmkymoyyzuuz?",
"answer": "m"
},
...
]
noise filtering:
[
# 过滤干扰词
{
"question": "WhatCAPRICIOUS-colorCANTALOUPE-isNONCHALANT-theINFINITY-sky?",
"answer": " Blue"
},
{
"question": "WhatDIAPHANOUS-doIRIDESCENT-youTENACIOUS-useMAGNANIMOUS-toSOLITUDE-writeWISTFUL-with?",
"answer": " Pen"
},
...
]
ASCII Art:
下图是 ASCII 艺术的几个例子,对于人类来说很容易做到,而对于机器人而言比较困难。
利用 LLM 的长处(擅长)
memorization:
[
# 对于知识的记忆
{
"question": "What is the surface area of Earth in square kilometers?",
"answer": "510072000"
},
...
]
computation:
[
# 四位数乘以四位数
{
"question": "What is the result of 8514 multiplied by 3978?",
"answer": "33868692"
},
...
]
实验结果
人类需要在 10 秒之内 回答相应的问题
作者对比了 GPT-3、ChatGPT、LLaMA、Alpaca 和 Vicuna 这五个 LLM 模型,实验结果如下图所示:

2、An Inverse Scaling Law for CLIP Training
预训练 CLIP 模型的 逆向缩放规律
《An Inverse Scaling Law for CLIP Training》
URL:https://arxiv.org/abs/2305.07017
Official Code:https://github.com/UCSC-VLAA/CLIPA
单位:UC Santa Cruz
文章类型:Technical report(技术报告)
动机:CLIP 模型在计算机视觉领域取得了突破性进展,但其训练成本较高,限制了其广泛应用。
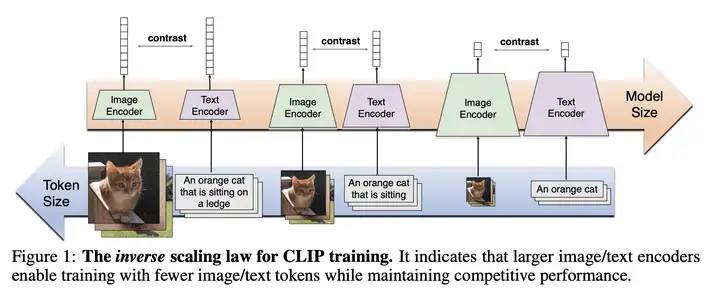
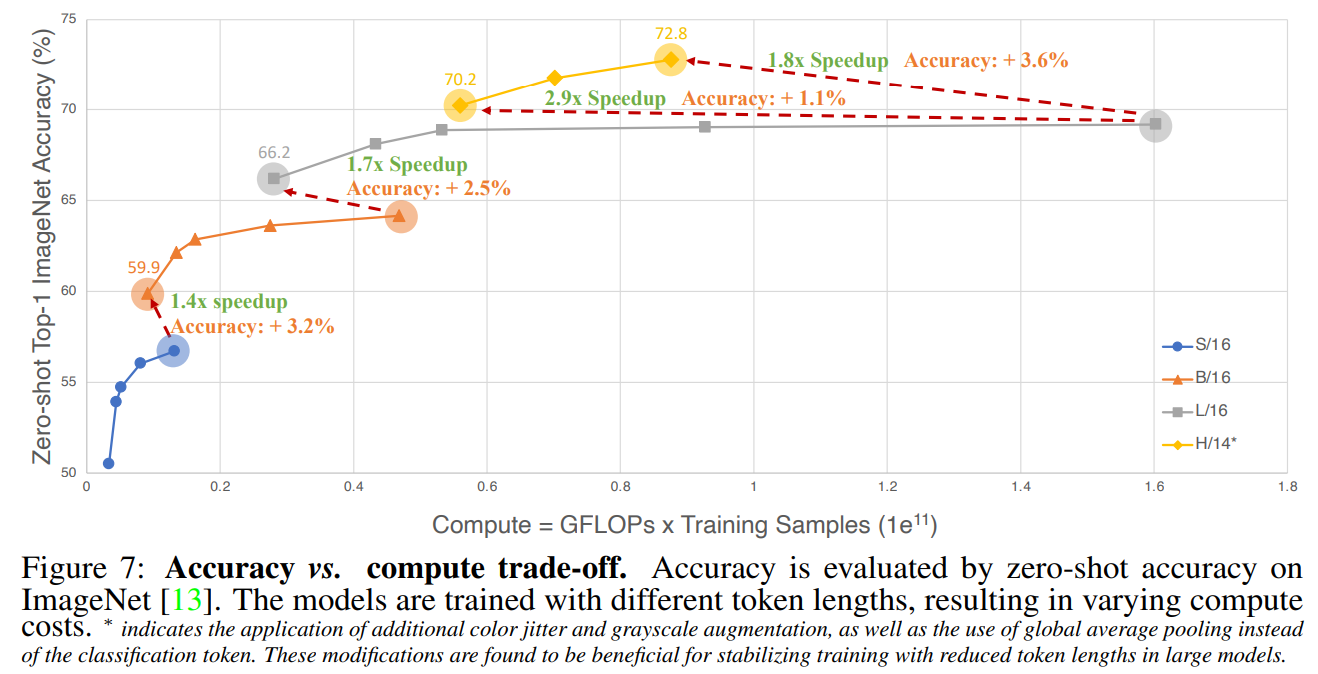
方法:发现 CLIP 训练的一个逆向缩放规律,即用较大的图像/文本编码器可以缩短训练中的图像/文本 Token 序列长度,同时保持性能。
优势:通过发现的逆向缩放规律,成功地利用公开可用的、开源的 LAION-400M 数据集 训练(6.4 个 epochs)了一个 CLIP 模型——CLIPA,显著降低了计算难度。
作者发现了预训练 CLIP 模型的逆向缩放规律,即:使用的图像/文本编码器规模越大,用于训练的图像/文本标记的序列长度可以变得更短,而保证 CLIP 模型的性能不下降。此外,我们展示了减少图像/文本标记长度的策略在确定该缩放定律的质量方面起着至关重要的作用。如下图所示:
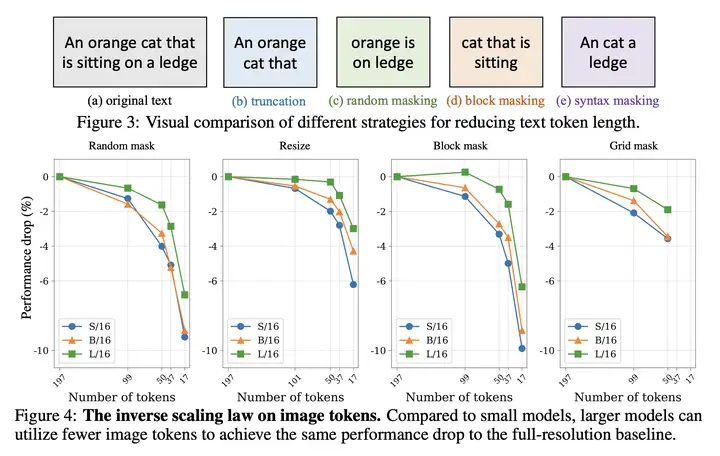
对于图像 Token 序列,作者尝试了下面几种不同的策略,来减少图像 Token 序列的长度:
Original Image
Random Masking
Grid Masking
Block Masking
Resizing
具体的示意图如下所示:

对于文本 Token 序列,作者尝试了下面几种不同的策略,来减少文本 Token 序列的长度:
original text
truncation(截断)
random masking
block masking
syntax masking
具体的示意图如下所示:
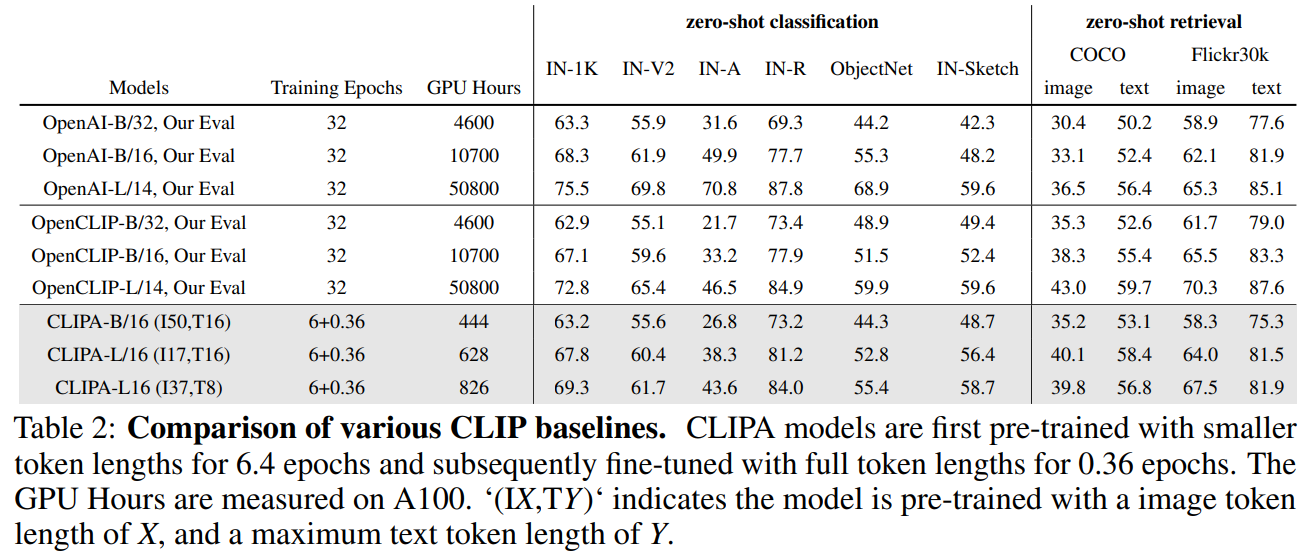
CLIPA 与 OpenAI CLIP、OpenCLIP 的实验结果如下图所示:
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-05-13-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)