2023-05-04:论文速递
Unlimiformer: Long-Range Transformers with Unlimited Length Input
《Unlimiformer: Long-Range Transformers with Unlimited Length Input》
URL:https://arxiv.org/abs/2305.01625
Official Code:https://github.com/abertsch72/unlimiformer
单位:Carnegie Mellon University
动机:现有的 transformer 模型由于需要考虑每 输入 Token,因此通常对其 输入长度有限制,但实际应用中需要能够处理任意长度的输入。
方法:提出一种名为 Unlimiformer 的方法,可以扩展现有的预训练编-解码器 Transformer 模型,使其在测试时能够接受任意长度的输入,而 无需修改模型代码或添加学习的权重。Unlimiformer 通过构建一个数据存储库(datastore),将所有输入符号的隐藏状态储存起来,并使用一种新的 k-近邻索引技术,将注意力计算分散在所有层上。
优势:Unlimiformer 可以应用于多个基础模型,例如 BART 或 PRIMERA,而不需要添加权重或重新训练。在多个长文档和多文档摘要基准测试上,Unlimiformer 的性能优于其他强大的长程 Transformer 模型,并且随着输入 Token 长度的增加,Unlimiformer 的推理时间呈 亚线性(sublinearly)增长。
相比于现有的接收长输入 Token 序列的 Transformer(例如最近的 Transformer 模型能够处理 200W 的 Token 序列),Unlimiformer 这种方式在工程上更加容易实施,并且可以利用现有的、可以利用的 Transformer 模型,而不需修改 Transfomrer 模型代码或者重新训练一个 Transformer 模型。
前言
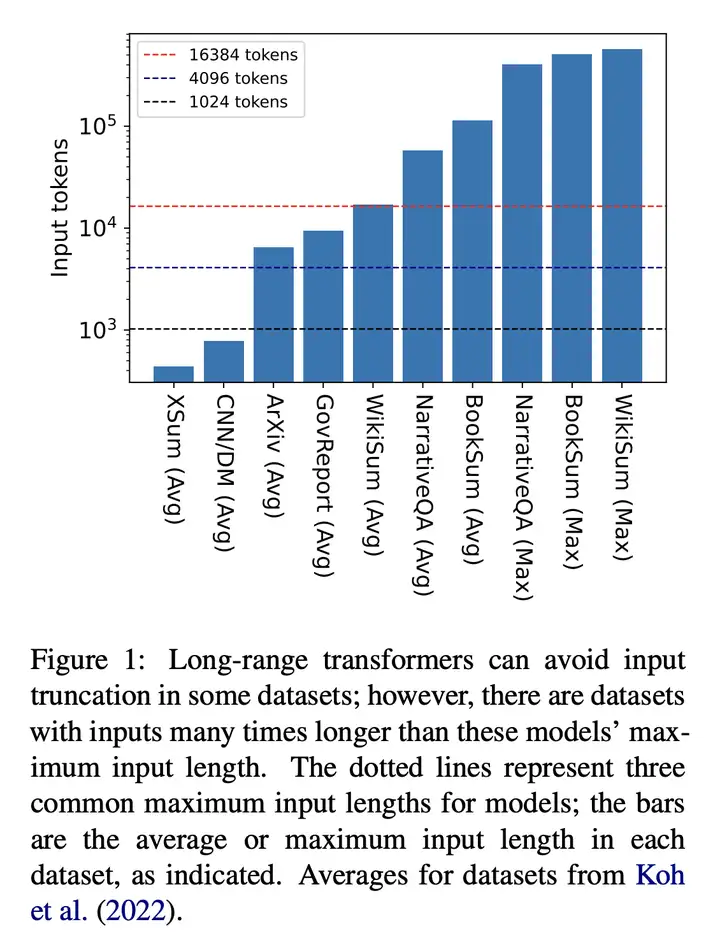
现有的大型数据集,如下图所示:
Unlimiformer 框架
Unlimiformer 的框架图如下所示:
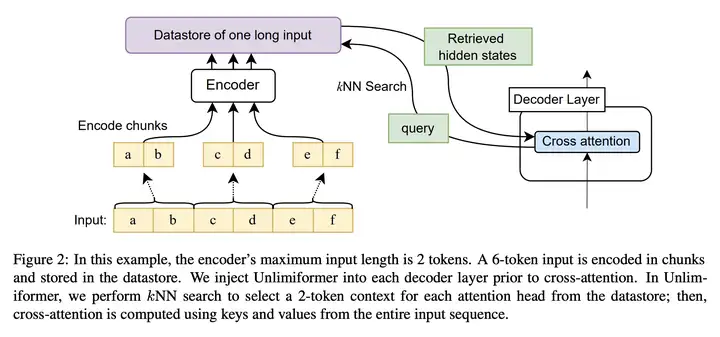
图中已输入 6 个 Token 序列为例,假设 Transformer 模型最多只能处理 2 个 Token 的序列。
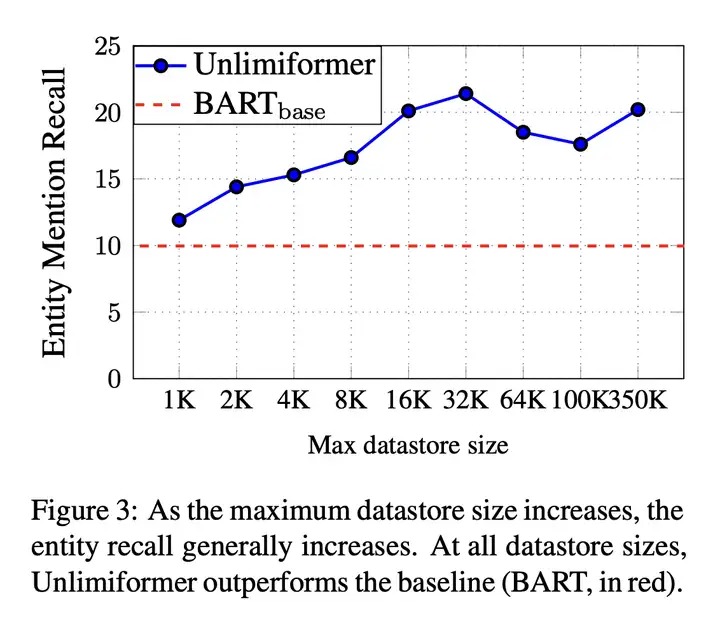
随着最大数据存储大小的增加,实体召回通常会增加。在所有数据存储大小下,Unlimiformer 都优于 BART 基线(红色虚线)。
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-05-04-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)