Pre Layer Normalization
《On the Layer Normalization in the Transformer Architecture》
URL:https://arxiv.org/abs/2002.04745
会议:ICML 2020
单位:北京大学、微软亚洲研究院
Official Code:
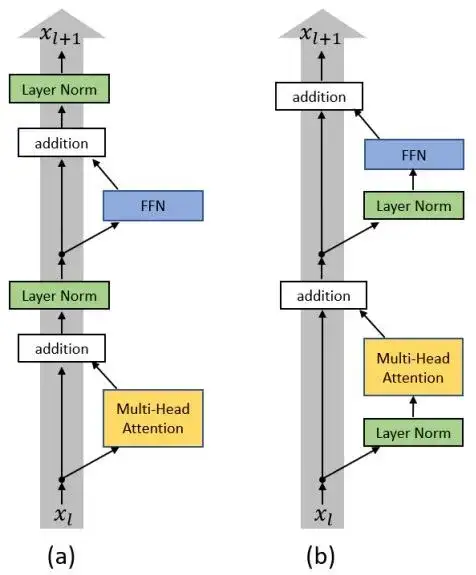
图片来源:On the Layer Normalization in the Transformer Architecture
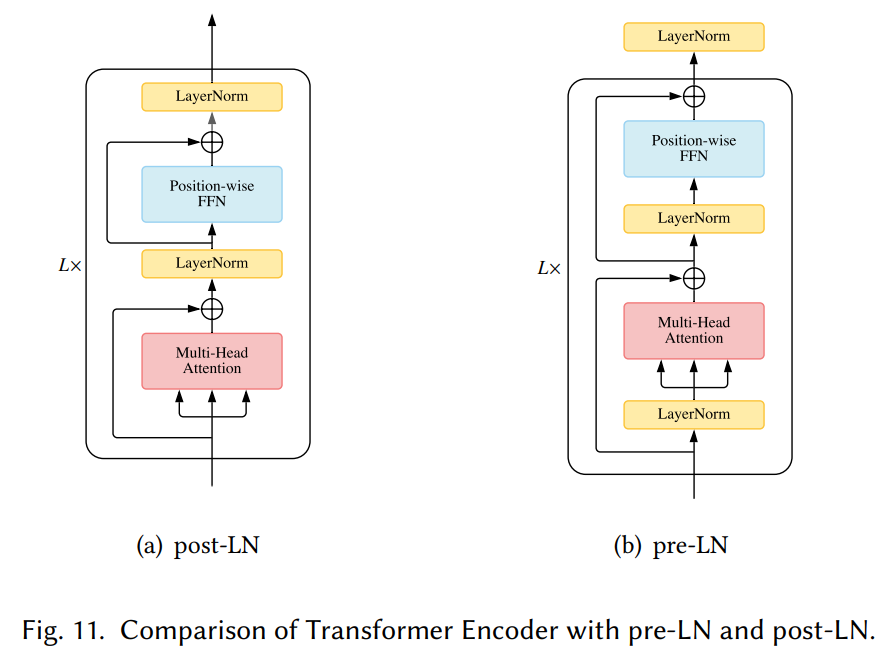
Pre Norm & Post Norm
Pre Norm 与 Post Norm 之间的对比是一个 “老生常谈” 的话题了,目前比较明确的结论是:同一设置之下,Pre Norm 结构往往更容易训练,但最终效果通常不如 Post Norm。
Pre Norm 更容易训练好理解,因为它的恒等路径更突出,但为什么它效果反而没那么好呢?
1)直观理解
Pre Norm 和 Post Norm 的式子如下所示:
\[\begin{align} \text{Pre Norm: } \quad \boldsymbol{x}_{t+1} = \boldsymbol{x}_t + F_t(\text{Norm}(\boldsymbol{x}_t))\\ \text{Post Norm: }\quad \boldsymbol{x}_{t+1} = \text{Norm}(\boldsymbol{x}_t + F_t(\boldsymbol{x}_t)) \end{align}\]其中,这里的 \(F_t(\cdot)\) 函数可以表示 Multi-head Attention 或者 FFN 操作;\(\text{Norm}(\cdot)\) 在 Transformer 中主要指 Layer Normalization,但在一般的模型中,也可以表示 Batch Normalization、Instance Normalization 等,相关结论本质上是通用的。
为什么 Pre Norm 的效果不如 Post Norm?知乎上 唐翔昊 给出的答案是:Pre Norm 的深度有 “水分”!也就是说,一个 \(L\) 层的 Pre Norm 模型,其实际等效层数不如 \(L\) 层的 Post Norm 模型,而层数少了导致效果变差了。
具体怎么理解呢?很简单,对于 Pre Norm 模型我们迭代得到 \(t+1\) 层的输出:
\[\begin{equation} \begin{aligned} \boldsymbol{x}_{t+1} =&\,\boldsymbol{x}_t + F_t(\text{Norm}(\boldsymbol{x}_t)) \\ =&\, \boldsymbol{x}_{t-1} + F_{t-1}(\text{Norm}(\boldsymbol{x}_{t-1})) + F_t(\text{Norm}(\boldsymbol{x}_t)) \\ =&\, \boldsymbol{x}_{t-2} + F_{t-2}(\text{Norm}(\boldsymbol{x}_{t-2})) + F_{t-1}(\text{Norm}(\boldsymbol{x}_{t-1})) + F_t(\text{Norm}(\boldsymbol{x}_t)) \\ =&\, \cdots \\ =&\, \boldsymbol{x}_0 + F_0 (\text{Norm}(\boldsymbol{x}_0)) + \cdots + F_{t-1}(\text{Norm}(\boldsymbol{x}_{t-1})) + F_t(\text{Norm}(\boldsymbol{x}_t)) \end{aligned} \end{equation}\]其中等式中的每一项都是 同一量级 的,即有 \(\boldsymbol{x}_{t+1}=\mathscr{O}(t+1)\)。也就是说,第 \(t+1\) 层输出与第 \(t\) 层输出的差别就相当于 \(t+1\) 与 \(t\) 之间的差别。当 \(t\) 比较大时,\(x_{t+1}\) 与 \(x_t\) 的相对差别是很小的,因此,\(F_{t+1}(\text{Norm}(\boldsymbol{x}_{t+1}))\) 与 \(F_{t+1}(\text{Norm}(\boldsymbol{x}_t))\) 很接近。
具体来说,有:
\[\begin{equation} \begin{aligned} &\,F_t(\text{Norm}(\boldsymbol{x}_t)) + \color{blue}{F_{t+1}(\text{Norm}(\boldsymbol{x}_{t+1}))} \\ \approx&\,F_t(\text{Norm}(\boldsymbol{x}_t)) + \color{blue}{F_{t+1}(\text{Norm}(\boldsymbol{x}_t))} \\ =&\, (F_t\oplus F_{t+1})(\text{Norm}(\boldsymbol{x}_t)) \end{aligned} \end{equation}\]因此,原来一个有 \(t\) 层的模型与第 \(t+1\) 层之和,近似等效于一个更宽的 \(t\) 层模型。也就是说,当模型层数不断加深时,Pre Norm 所增加的模型深度会被 “吸收” 为模型的宽度,所以在 Pre Norm 中多层叠加的结果更多是增加宽度而不是深度,层数越多,这个层就越 "虚"。
Pre Norm 结构 无形地增加了模型的宽度而降低了模型的深度,而我们知道 深度通常比宽度更重要,所以是无形之中的降低深度导致最终效果变差了。
而 Post Norm 刚刚相反,在 《浅谈Transformer的初始化、参数化与标准化》 中我们就分析过,它 每 Norm 一次就削弱一次恒等分支的权重,所以 Post Norm 反而是 更突出残差分支 的(因此梯度更加难以控制,比较难训练),因此 Post Norm 中的层数更加 “足秤”,一旦训练好之后效果更优。
2)相关工作:DeepNet
在苏剑林大佬找到的资料中,显示 Post Norm 优于 Pre Norm 的工作有两篇,一篇是 《Understanding the Difficulty of Training Transformers》,一篇是 《RealFormer: Transformer Likes Residual Attention》。另外,苏剑林大佬自己也做过对比实验,显示 Post Norm 的结构迁移性能更加好,也就是说在 Pretraining 中,Pre Norm 和 Post Norm 都能做到大致相同的结果,但是 Post Norm 的 Finetune 效果明显更好。
可能读者会反问 《On Layer Normalization in the Transformer Architecture》 不是显示 Pre Norm 要好于 Post Norm 吗?这是不是矛盾了?其实这篇文章比较的 是在完全相同的训练设置下 Pre Norm 的效果要优于 Post Norm,这只能显示出 Pre Norm 更容易训练,因为 Post Norm 要达到自己的最优效果,不能用跟 Pre Norm 一样的训练配置(比如 Pre Norm 可以不加 Warmup 但 Post Norm 通常要加),所以结论并不矛盾。
前段时间号称能训练 1000 层 Transformer 的 DeepNet 想必不少读者都听说过,在其论文 《DeepNet: Scaling Transformers to 1,000 Layers》 中对 Pre Norm 的描述是:
However, the gradients of Pre-LN at bottom layers tend to be larger than at top layers, leading to a degradation in performance compared with Post-LN.
然而,Pre-LN 在底层的梯度往往大于顶层,导致与 Post-LN 相比性能下降。
不少读者当时可能并不理解这段话的逻辑关系,但看了前一节内容的解释后,想必会有新的理解。
简单来说,所谓 “the gradients of Pre-LN at bottom layers tend to be larger than at top layers”,就是指 Pre Norm 结构会过度倾向于恒等分支(bottom layers),从而使得 Pre Norm 倾向于退化(degradation)为一个 “浅而宽” 的模型,最终不如同一深度的 Post Norm。这跟前面的直观理解本质上是一致的。
3)两层的对比:Pre Norm & Post Norm
对于 Post Norm,迭代模型层数(假设有 \(t+1\) 层),有:
\[\begin{equation} \begin{aligned} x_{t+1} &= \text{Norm}(x_t + F_t(x_t)) \\ &= \text{Norm}(\text{Norm}(x_{t-1}+F_{t-1}(x_{t-1})) + F_t(x_t)) \\ &= \cdots \end{aligned} \end{equation}\]当 \(t=1\) 时,模型包含 2 层。对于 Pre Norm,有:
\[x_2 = x_0 + F_0(\text{Norm}(x_0)) + F_1(\text{Norm}(x_1))\]对于 Post Norm,有:
\[x_2 = \text{Norm}(\text{Norm}(x_1+F_0(x_0)) + F_1(x_1))\]4)具体的计算方式
Post-Noem 与 Pre-Norm 具体的计算方式如下图所示:
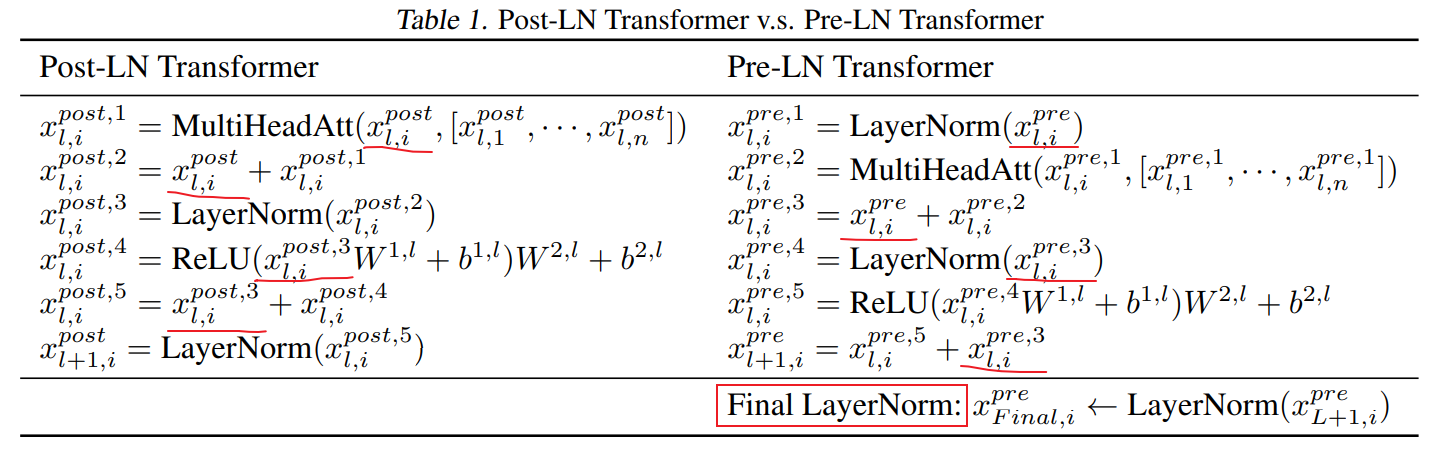
图片来源:On the Layer Normalization in the Transformer Architecture
需要注意的是:在 Pre-Norm 中,需要在最后一层之后的输出上,再加上一个 LayerNorm,即上图中的 Final LayerNorm!
完成
ActivityNet Captions 【OK】
Charades-STA 【数据处理完成,Dataset、Dataloader 还没完成】
DiDeMo 【No】
TACoS:使用 tall_c3d_features.hdf5 【OK】
的 Dataset 和 DataLoader
完成相关的模型配置文件的分离
tacos
train: 9790
val: 4436
test: 4001
有些视频已经 missing 了,无法下载到(因为是 Youtube 视频,有些下架了)
Charades-STA
PSVL 里面的 train=12523(大于数据集原始论文中的12404)test=3720(与原始相等)
由于是根据聚类算法随机采样的原因,因此 PSVL 中的 train 比原始论文的会多,也是正常的
Language-Free(VC-TVG)
【2411898】
- bs=512
- epoch=500
- Adam: lr=4e-4
- no warmup
- attention_loss=1.0
- drop_loss=0.7
- Position Embedding: 1D Cosin PE(绝对位置)
- 重新更改 LN, Conv1d, ReLU, ResNet 的位置,使用 Post Norm 形式,即 ReLU(LN(Conv1d(MSA(x)) + x)) or ReLU(LN(MSA(x) + x))(使用后者这种,没有 Conv1d)
- 添加 Non Local Block
- 将 text_feats 进行归一化(norm(dim=-1)),并且在训练阶段添加了一些高斯噪声(如 Language-Free 中所做的那样)
- Regression Head:(dim, dim) + ReLU() + (dim, 2) + ReLU() (train_lf_31.log) ing -> bad end 0.1->48; 0.3->27; 0.5->14.5; 0.7->7.2; mIoU->20;
【2611849】 重新尝试:
- 使用 Post Norm 的形式,即 LN(ReLU(MSA(x)) + x)
- Regression Linear Dropout=0.3
- Non Local Linear Dropout=0.3
- drop_loss=1 (train_lf_31.log) ing -> bad end(self-aattention 会出现梯度消失) 【3398644】 重新尝试:
- 使用 Post Norm 形式:LN(MSA(x) + x)
- Dropout 还是 0.1(取消 Regression Head 的 dropout)
- drop_loss=1 (train_lf_31.log) ing -> bad end epoch=132: 0.1->57.54; 0.3->36.42; 0.5->17.09; 0.7->; mIoU->24.15; 【508723】 重新尝试:
- 使用 Post Nrom 形式:LN(Conv1d(MSA(x)) + x)
- Non Local Dropout 还是 0.1(取消 Regression Head 的 dropout)
- drop_loss=1 (train_lf_31.log) ing -> bad end 《Convld weight 梯度为 0》 【835738】 重新尝试:
- Self Attention 和 Cross Attention 取消 LN、Conv1D、ReLU,只使用 ResNet
- 同时修改了 Cross Attention 的代码,ResNet 添加的是 video_feats,之前都是添加的 text_feats(也是看了 Languange-free 的复现代码)
- Non Local Dropout 还是 0.1(取消 Regression Head 的 dropout)
- drop_loss=1 (train_lf_31.log) ing -> bad end epoch=: 0.1->39; 0.3->22; 0.5->12.5; 0.7->6; mIoU->16; 【1060384】 重新尝试:
- 修改了 Cross Attention 和 Self Attention 的代码,将 Text Featas 进行 expand,从 (BS, dim) -> (BS, 1, dim) -> (BS, len, dim)
- 取消 Drop Loss(加快速度)
- 取消一切 Dropout,除了 GRU 的 dropout=0.5
- 取消 Non-Local (train_lf_31.log) ing -> bad end 出现梯度消失
CUDA_VISIBLE_DEVICES=0 nohup python train_lf.py > train_lf_31.log 2>&1 &
UNITER + Adapter + Soft Prompt(BERT)
- UNITER-base + BERT
- Charades-STA 数据集 (train_20.log) ing -> kill
Violet 实验总体设置
R-Drop Loss Trick
| 方法\结果 | train.log | Charades-STA | ActivityNet Captions | TACoS | DiDeMo |
|---|---|---|---|---|---|
| Hard Prompt + Fine Tune | 54 | ||||
| Soft Prompt + Fine Tune | |||||
| 方法\结果 | train.log | Charades-STA | ActivityNet Captions | TACoS | DiDeMo |
|---|---|---|---|---|---|
| Only Hard Prompt | 43、47 | ||||
| Hard Prompt + BitFit | 48 | ||||
| Hard Prompt + LoRA (\(W_q, W_v\)) | 49 | ||||
| Hard Prompt + LoRA (\(W_q, W_v\)) + BitFit | |||||
| Hard Prompt + LoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) | 51(r=8),52(r=4),53(r=2) | ||||
| Hard Prompt + LoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) + BitFit | |||||
| Hard Prompt + AdaLoRA (\(W_q, W_v\)) | 50 | ||||
| Hard Prompt + AdaLoRA (\(W_q, W_v\)) + BitFit | |||||
| Hard Prompt + AdaLoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) | |||||
| Hard Prompt + AdaLoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) + BitFit | |||||
| Only Soft Prompt | 44 | ||||
| Soft Prompt + BitFit | |||||
| Soft Prompt + LoRA (\(W_q, W_v\)) | |||||
| Soft Prompt + LoRA (\(W_q, W_v\)) + BitFit | |||||
| Soft Prompt + LoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) | |||||
| Soft Prompt + LoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) + BitFit | |||||
| Soft Prompt + AdaLoRA (\(W_q, W_v\)) | |||||
| Soft Prompt + AdaLoRA (\(W_q, W_v\)) + BitFit | |||||
| Soft Prompt + AdaLoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) | |||||
| Soft Prompt + AdaLoRA (\(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)) + BitFit |
Hard Prompt: VIOLET
脚本:train_hard_prompt_violet.py
Module: FtGPTVioletModel
Charades-STA
train_43.log
【2615938】
GPT-2 Medium
VIOLET Base
使用
Let's think step by step, the text of, starts at time and ends at time-
Regress Head
- Linear(dim, dim//2) + ReLU() + Linear(dim//2, 1) + ReLU()
-
AdamW
- LR:3e-4
- weight decay: 1e-3
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
- BS:128
- Epoch:200
ing -> bad end
Start Regression 出现梯度消失
train_43.log【2】
【2822531】
接上面 43 的设置,为了解决 Start Regression 从一开始就出现的梯度消失问题,使用 kaiming_normal_() 对 Linear.weight 进行初始化,Linear.bias 则初始化为 0:
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.Linear)):
# nn.init.xavier_uniform_(m.weight)
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# if isinstance(m, nn.Linear):
# nn.init.trunc_normal_(m.weight, std=.02)
# if isinstance(m, nn.Linear) and m.bias is not None:
# nn.init.constant_(m.bias, 0)
ing -> bad end
出现严重的过拟合现象
epoch = 53:
0.1 -> 61.38;
0.3 -> 48.8;
0.5 -> 33.98;
0.7 -> 15.78;
mIoU -> 32.56;
train_43.log【3】
【1994088】
为了解决过拟合现象,在原有的基础上:
- 在 Regression Head 中增加 Dropout,即
nn.Dropout(0.3)
ing -> bad end
仍然会出现严重的过拟合
epoch = 60:
0.1 -> 62.42;
0.3 -> 49.30;
0.5 -> 34.84;
0.7 -> 15.26;
mIoU -> 32.76;
train_43.log【4】
【3226406】
在原有的基础上,将 Dropout 调大到 nn.Dropout(0.5)
并且将 epoch 从 200 降为 100,优化器、学习率、warmup 设置不变 ==epoch=100==
ing -> bad end
epoch = 74:
0.1 -> 61.71;
0.3 -> 48.33;
0.5 -> 34.27;
0.7 -> 15.10;
mIoU -> 32.45;
train_43.log【5】
【256316】
- 将 Dropout 调大为
nn.Dropout(0.5) - 同时将 regression head 更改为:
Linear(dim, dim//4) + Dropout(0.5) + ReLU() + Linear(dim//4, 1) + ReLU() epoch=100
ing -> bad end
还是会出现《过拟合》现象
train_43.log【6】
【3667743】
epoch = 150
取消 Dropout
-
AdamW
- 降低初始学习率:从
3e-4到1e-4 - weight_decay: 从
1e-3到1e-2(默认)
- 降低初始学习率:从
-
batch size
- 从
128降为16
- 从
-
Regression Head ==取消 Dropout==
- 初始化:截断的正态分布
Linear(dim, dim//24) + ReLU() + Linear(dim//24, 1) + ReLU() # (768, 32) + (32, 1)
ing -> bad end
(train_43.log)
train_43.log【7】
【198557】
- epoch = 150
- 取消 Dropout
- AdamW
- LR:
5e-4
- LR:
batch size:
32-
Regression Head ==取消 Dropout==
- 初始化:截断的正态分布
Linear(dim, dim//24) + ReLU() + Linear(dim//24, 1) + ReLU() # (768, 32) + (32, 1)
ing -> bad end
(train_43_7.log)
train_43.log【8】
【3168086】
- epoch = 100
- batch size:
16 - AdamW
- LR:
1e-4
- LR:
-
Regression Head ==取消 Dropout==
- 初始化:截断的正态分布
Linear(dim, 1) + ReLU()
ing -> bad end
(train_43_8.log)
train_43.log【9】
【1206225】
- epoch = 100
- batch size:
16 - AdamW
- LR:
1e-4
- LR:
-
Regression Head ==取消 Dropout== ==取消输出层的 ReLU==
- 初始化:截断的正态分布
Linear(768, 32) + ReLU() + Linear(32, 1)
ing -> bad end
(train_43_9.log)
train_43.log【10】
三层 MLP
【1586503】
- epoch = 100
- batch size:
16 - AdamW
- LR:
1e-4
- LR:
-
Regression Head ==取消 Dropout== ==三层 MLP==
- 初始化:截断的正态分布
Linear(768, 24) + ReLU() + Linear(24, 24) + ReLU() + Linear(24, 1) + ReLU()
ing -> bad end
(train_43_10.log)
train_43.log【11】
两层 MLP:继续缩小 MLP 的宽度
【1754840】
epoch = 100
GPT-2 Mediumbatch size:
16-
AdamW
- LR:
1e-4
- LR:
-
Regression Head ==两层 MLP== ==取消 Dropout==
-
初始化:截断的正态分布
Linear(dim, dim // 48) + ReLU() + Linear(dim // 48, 1) + ReLU() # (768, 16) + (16, 1)
-
ing -> bad end
(train_43_11.log)
train_43.log【12】
与 11 同样的配置,不同的是使用
BERT base模型来提取文本特征
【4118923】
- bs = 16
ing -> bad end
(train_43_12.log)
train_43.log【13】
与 11 同样的配置,不同的是使用
BERT Large模型来提取文本特征
【2703697】
- bs = 16
ing -> bad end
(train_43_13.log)
train_43.log【14】
与 12 一致,
bert-base;
- 取消了 warmup
- 将 cosin 衰减从
(1e-4, 0)变为(1e-4, 1e-5)
【33533】
- bs = 16
ing -> bad end
(train_43_14.log)
train_43.log【15】
与 13 一致,
bert-large;
- 取消了 warmup
- 将 cosin 衰减从
(1e-4, 0)变为(1e-4, 1e-5)
【54105】
- bs = 16
ing -> bad end
(train_43_15.log)
train_43.log【16】
与 11 同样的配置,不同的是使用
RoBERTa base模型来提取文本特征
【816048】
bs = 16
- AdamW
- cosin:
1e-4->0
- cosin:
- Warmup
- 2;
1e-8->1e-4
- 2;
ing -> bad end
(train_43_16.log)
train_43.log【17】
与 11 同样的配置,不同的是使用
RoBERTa Large模型来提取文本特征
【827494】
bs = 16
- AdamW
- cosin:
1e-4->0
- cosin:
- Warmup
- 2;
1e-8->1e-4
- 2;
ing -> bad end
(train_43_17.log)
train_43.log【19】
与 13 一致,
bert-large;
- with warmup:2;1e-8
- 将 cosin 衰减从
(1e-4, 0)- 修改 fusion encoder 的 Position Embedding 方式
- 从 sincos 位置编码更改为 BERT 的预先学习好的位置编码
【1117514】
bs = 16
- AdamW
- cosin:
1e-4->0
- cosin:
- Warmup
- 2;
1e-8->1e-4
- 2;
ing -> bad end
(train_43_19.log)
13 VS 19:
- Sincos Position Embedding > BERT’s Learnable Position Embedding
train_43.log【20】
与 13 一致,
bert-large;
- with warmup:2;1e-8
- 不使用学习率衰减 ==探究学习率的影响==
【2357708】
bs = 16
- AdamW
- constant:
1e-4 - 将调度器的
lr_min设置为1e-4
- constant:
- Warmup
- 2;
1e-8->1e-4
- 2;
ing -> bad end
(train_43_20.log)
train_43.log【21】
与 13 一致,
bert-large;
- with warmup:
5;1e-8 ==探究 warmup 对模型收敛的影响==
【3788801】
- bs =
16 - epoch = 100
- AdamW
-
1e-4->1e-5
-
- Warmup
- 5;
1e-8->1e-4 - 从
2到5
- 5;
ing ->
(train_43_21.log)
train_43.log【22】
与 13 一致,
bert-large;
- with warmup:
10;1e-8 ==探究 warmup 对模型收敛的影响==
【3798642】
- bs =
16 - epoch = 100
- AdamW
-
1e-4->1e-5
-
- Warmup
- 10;
1e-8->1e-4 - 从
2到10
- 10;
ing ->
(train_43_22.log)
train_43.log【23】
与 13 一致,
bert-large去掉了 Tokenizer 末尾的
[SEP],而仅仅包括开头的[CLS],即将 ==去掉 [SEP] Token==Let's think step by step. The text of "[Text]", starts at time [MASK] and ends at time [MASK].[SEP]改为
Let's think step by step. The text of "[Text]", starts at time [MASK] and ends at time [MASK].
【3979329】
- bs =
16 - epoch = 100
- AdamW
-
1e-4->1e-5
-
- Warmup
- 2;
1e-8->1e-4
- 2;
ing ->
(train_43_23.log)
train_43.log【24】
在 23 的基础上,添加 R-Drop Loss(MAE 度量函数)
no start now
train_45.log
【4142979】
接上面 43 的设置,为了解决 Start Regression 从一开始就出现的梯度消失问题,使用 截断的正态分布 来对 Linear.weight 进行初始化,Linear.bias 则初始化为 0:
for m in self.modules():
# if isinstance(m, (nn.Conv2d, nn.Linear)):
# nn.init.xavier_uniform_(m.weight)
# nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
# if isinstance(m, nn.Linear) and m.bias is not None:
# nn.init.constant_(m.bias, 0)
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
同时在 Regression Head 中添加了 Dropout,即
Linear(dim, dim//2) + Dropout(0.1) + ReLU() + Linear(dim//2, 1) + ReLU()
ing -> bad end
epoch = 122:
0.1 -> 63.96;
0.3 -> 50.23;
0.5 -> 36.22;
0.7 -> 17.78;
mIoU -> 34.43;
仍然会出现过拟合的情况
【1745443】
- 增大 Dropout 的比例,改为
nn.Dropout(0.3)==一个 Dropout==
ing -> bad end
epoch = 67:
0.1 -> 62.34;
0.3 -> 48.09;
0.5 -> 33.70;
0.7 -> 15.31;
mIoU -> 32.22;
仍然会出现过拟合的现象
【3255854】
- 继续增大 Dropout 的比例,改为
nn.Dropout(0.5) - 并且对于第二层的 Linear 也添加 Dropout(0.5),即
Linear(dim, dim//2) + Dropout(0.5) + ReLU() + Linear(dim//2, 1) + Dropout(0.5) + ReLU()==两个 Dropout== - 同时,将 epoch 调整为 100
ing -> bad end
epoch = 10:
0.1 -> 48.78;
0.3 -> 37.79;
0.5 -> 15.60;
0.7 -> 3.39;
mIoU -> 20.93;
训练极其不稳定
【884514】
- 适当减小第二层 Linear 的 Ropout 比例,将 Regression Head 改为:
Linear(dim, dim // 2),
Dropout(0.5),
ReLU(),
Linear(dim//2, 1)
Dropout(0.1)
ReLU()
- 其他保持不变
ing -> bad end
epoch = 85:
0.1 -> 57.45;
0.3 -> 42.39;
0.5 -> 26.80;
0.7 -> 10.34;
mIoU -> 27.61;
train_46.log
往 Prompt 中添加 Duration 信息,例如:
# Let's think step by step, the text of "I am walking in the room", starts at time 5 and ends at time 10 in duration 12 seconds video.
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}.
修改 charades_dataset.py 中的 CharadesDataset()
GPT-2 Medium
VIOLET Base
-
Regress Head
Linear(dim, dim//2) + Dropout(0.5) + ReLU() + Linear(dim//2, 1) + ReLU() ==一个 Dropout==
-
初始化
for m in self.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): # nn.init.xavier_uniform_(m.weight) nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu') if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) # if isinstance(m, nn.Linear): # nn.init.trunc_normal_(m.weight, std=.02) # if isinstance(m, nn.Linear) and m.bias is not None: # nn.init.constant_(m.bias, 0)
-
AdamW
- LR:3e-4
- weight decay: 1e-3
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
BS:128
Epoch:100
【3344286】
ing -> bad end
epoch = 81:
0.1 -> 64.79;
0.3 -> 48.56;
0.5 -> 34.06;
0.7 -> 14.56;
mIoU -> 32.69;
还是会出现《过拟合》
train_46.log【2】
AdamW
- LR:5e-5
- weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:5e-5 -> 0
- epoch = 200
Regress Head
- Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
-
(768, 128)->(128, 1)
no start now
train_47.log
【970892】
- epoch = 100
- GPT-2 Medium
- VIOLET Base
- AdamW
- LR:3e-4
- weight decay: 1e-3
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
BS: 128
- 将 Regression Head 改为:
Linear(dim, dim // 4), # (768, 192)
Dropout(0.5),
ReLU(),
Linear(dim//4, 1) # (192, 1)
Dropout(0.1)
ReLU()
- 使用 正态分布 进行初始化:
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
- Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}.
ing -> bad end
epoch = 81:
0.1 -> 62.19;
0.3 -> 47.19;
0.5 -> 30.60;
0.7 -> 10.76;
mIoU -> 30.38;
还是会出现《过拟合》
train_47.log【2】
【293633】
- 使用一个
Dropout(0.5),即 ==单个 Dropout==
Linear(dim, dim // 4), # (768, 192)
Dropout(0.5),
ReLU(),
Linear(dim//4, 1) # (192, 1)
ReLU()
- 降低学习率
- 从 3e-4 改为 5e-5
ing -> bad end
epoch = 86:
0.1 -> 61.77;
0.3 -> 45.49;
0.5 -> 30.08;
0.7 -> 11.59;
mIoU -> 30.14;
train_47.log【3】
【3459129】
- Adamw
- 初始学习率:
5e-5 - weight_decay:从
1e-3变为1e-2
- 初始学习率:
- epoch=200
ing -> bad end
epoch = 121:
0.1 -> 60.76;
0.3 -> 46.67;
0.5 -> 32.16;
0.7 -> 13.04;
mIoU -> 30.75;
train_47.log【4】
【3322580】
- Regression Head
- Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
-
(768, 128)->(128, 1)
ing -> bad end
epoch = 157:
0.1 -> 61.64;
0.3 -> 48.47;
0.5 -> 32.42;
0.7 -> 14.53;
mIoU -> 31.64;
仍然会出现《过拟合》的情况
train_47.log【5】
【743171】
在前面的基础上,增加 R-Drop Loss
-
AdanW
- 初始学习率:
3e-4
- 初始学习率:
epoch = 300
bs = 64(过大显存不够)
-
更改初始化方式:从正态分布改为 kaiming 初始化,再改为 pytorch 默认的初始化方式
- 正态分布初始化,会出现梯度消失的情况
for m in self.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): # nn.init.xavier_uniform_(m.weight) nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu') if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0)kaiming 初始化也会出现梯度消失
默认的初始化方法,也会出现梯度消失
train_48.log
hard prompt + BitFit
【817769】
- epoch = 300
- GPT-2 Medium
- VIOLET Base
- AdamW
- LR:3e-4
- weight decay: 1e-2
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
BS = 128
-
Regression Head
Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
(768, 128)->(128, 1)
-
Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0)
ing -> bad end
train_49.log
Hard Prompt + LoRA (query、value) + r = 8
【2319798】
- epoch = 300
- GPT-2 Medium
- VIOLET Base
- AdamW
- LR:3e-4
- weight decay: 1e-2
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
BS = 128
-
Regression Head
Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
(768, 128)->(128, 1)
-
Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
LoRA 配置:
peft_config = LoraConfig( inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.1, # 没有使用 Dropout # bias=None )
ing -> bad end
train_49.log【2】
【】
- batch size
- 从
128到32
- 从
-
AdamW
LR:
5e-4betas: 从
(0.9, 0.95)改为(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:5e-4 -> 0
-
Regression Head
Linear(dim, dim // 32) + ReLU() + Linear(dim // 32, 1) + ReLU() ==无需 Dropout==
(768, 24)->(24, 1)
-
LoRA 配置:==r = 8==
peft_config = LoraConfig( inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.1, # bias=None ) -
text prompt
Let's think step by step. The text of "{I am walking around the room}", starts at time {5} and ends at time {10}.
no start now
(train_49.log)
train_51.log
Hard Prompt + LoRA(\(W_q,W_k,W_v, W_o, W_{f_1}, W_{f_2}\))+ (r = 8)
【460110】
epoch = 300
-
AdamW
LR:3e-4
betas:
(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:3e-4 -> 0
BS = 80
-
Regression Head
Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
(768, 128)->(128, 1)
-
Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
LoRA 配置:
peft_config = LoraConfig( inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.1, target_modules=["query", "key", "value", "dense"], # 应用 LoRA 的目标模块 # bias=None )
ing -> bad end
【2093691】
- epoch = 200
ing -> bad end
(train_51.log【2】)
train_51.log【3】
【2905300】
epoch = 200
-
AdamW
- LR:1e-4
-
Regression Head
Linear(dim, dim // 16) + Dropout(0.5) + ReLU() + Linear(dim // 16, 1) + ReLU() ==一个 Dropout==
(768, 48)->(48, 1)
ing -> bad end
train_51.log【4】
【3728602】
epoch =
150-
AdamW
- LR:
5e-5
- LR:
-
Regression Head
Linear(dim, dim // 32) + Dropout(0.5) + ReLU() + Linear(dim // 32, 1) + ReLU() ==一个 Dropout==
(768, 24)->(24, 1)
-
text prompt
Let's think step by step. The text of "{I am walking around the room}", starts at time {5} and ends at time {10}.
ing -> bad end
(train_51.log)
train_51.log【5】
【2192342】
epoch =
150- batch size
- 从
80降为32
- 从
- LR:
5e-5 - Regression Head ==一个 Dropout==
ing -> bad end
train_52.log
Hard Prompt + LoRA(\(W_q,W_k,W_v, W_o, W_{f_1}, W_{f_2}\))+(r = 4)
【594491】
-
AdamW
LR:3e-4
betas:
(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:3e-4 -> 0
BS = 88
-
Regression Head
Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
(768, 128)->(128, 1)
-
Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
LoRA 配置:
peft_config = LoraConfig( inference_mode=False, r=4, lora_alpha=4, lora_dropout=0.1, target_modules=["query", "key", "value", "dense"], # 应用 LoRA 的目标模块 # bias=None )
ing -> bad end
【2097356】
- epoch = 200
ing -> bad end
(train_52.log【2】)
train_52.log【3】
【3375426】
-
AdamW
LR:1e-4
betas:
(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:1e-4 -> 0
BS = 88
-
Regression Head
Linear(dim, dim // 16) + Dropout(0.5) + ReLU() + Linear(dim // 16, 1) + ReLU() ==一个 Dropout==
(768, 48)->(48, 1)
ing -> bad end
(train_52_3.log)
train_52.log【4】
【4102308】
-
AdamW
LR:1e-4
betas:
(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:1e-4 -> 0
BS = 88
-
Regression Head
Linear(dim, dim // 32) + Dropout(0.5) + ReLU() + Linear(dim // 32, 1) + ReLU() ==一个 Dropout==
(768, 24)->(24, 1)
ing -> bad end
(train_52_4.log)
train_52.log【5】
【2197851】
epoch =
150- batch size
- 从
88降为32
- 从
- LR:
5e-5 - Regression Head ==一个 Dropout==
ing -> bad end
train_53.log
Hard Prompt + LoRA(\(W_q,W_k,W_v, W_o, W_{f_1}, W_{f_2}\))+(r = 2)
【363457】
- AdamW
LR:5e-5
betas:
(0.9, 0.999)weight decay: 1e-2
Warmup: 2; 1e-8
Cosin LR:5e-5 -> 0
BS = 92
epoch = 150
-
Regression Head
Linear(dim, dim // 32) + Dropout(0.5) + ReLU() + Linear(dim // 32, 1) + ReLU() ==一个 Dropout==
(768, 24)->(24, 1)
-
Text Prompt:
Let's think step by step. The text of "{I am walking around the room}", starts at time {5} and ends at time {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
LoRA 配置:
peft_config = LoraConfig( inference_mode=False, r=2, lora_alpha=2, lora_dropout=0.1, target_modules=["query", "key", "value", "dense"], # 应用 LoRA 的目标模块 # bias=None )
ing -> bad end
还是存在【过拟合】
train_53.log【2】
【1945167】
- 降低 batch size,以减缓 过拟合
- 从
92降到64
- 从
- epoch = 150
- AdamW
- LR:
1e-4
- LR:
no start now
train_53.log【3】
【3768846】
- batch size
- 从
64降为32
- 从
- AdamW
- LR:
5e-5
- LR:
ing ->
(train_53_3.log)
train_53.log【4】
【3771481】
- batch size
- 从
32降为16
- 从
- AdamW
- LR:
5e-5
- LR:
ing ->
(train_53_4.log)
train_53.log【5】
share start regression head and end regression head
【3175492】
-
共享 Start Regression Head 和 End Regression Head
regression_head = RegressionModule(self.cfg) self.start_regression = regression_head self.end_regression = regression_headLinear(dim, dim // 32) + Dropout(0.5) + ReLU() + Linear(dim // 32, 1) + ReLU() ==一个 Dropout==
(768, 24)->(24, 1)
batch size:
16-
AdamW
- LR:
5e-5
- LR:
epoch =
150
ing -> bad end
(train_53_5.log)
train_53.log【6】
Concat Start And End
【3219794】
-
拼接 Start、End,使用一个统一的 Regression Head
Linear(dim * 2, 48) + ReLU() + Linear(48, 2) + ReLU()1536 * 48 + 48 * 2 = 73824- 初始化方式:
- kiaming 初始化
- 初始化方式:
- batch size:
16 - AdamW
- LR:
5e-5
- LR:
- epoch =
150
ing -> bad end
(train_53_6.log)
train_53.log【7】
更改为 GPT-2 Base 模型
【3465166】
GPT2-basebatch size =
16- AdamW
- LR:
1e-4
- LR:
- epoch =
100
ing -> bad end
(train_53_7.log)
train_53.log【8】
在 7 的基础上,添加 R-Drop Loss(使用
KL 散度作为度量)
【3547627】
GPT2-basebatch size =
16- AdamW
- LR:
1e-4
- LR:
epoch =
100- ==R-Drop Loss==
- alpha: 4.0
ing -> bad end
(train_53_8.log)
train_53.log【9】
在 8 的基础上,添加 R-Drop Loss(使用
MSE/均方误差 作为度量)
【3970474】
GPT2-basebatch size =
16- AdamW
- LR:
1e-4
- LR:
epoch =
100-
==R-Drop Loss==
alpha: 1.0
-
MSE 度量函数
- Regression Head ==No Dropout==
-
(768, 24)->(24, 1)
-
- lora
- r = 2
- dropout = 0.1
- “all”
ing -> bad end
(train_53_9.log)
train_53.log【10】
在 8 的基础上,添加 R-Drop Loss(使用
MAE/平均绝对误差作为度量,alpha 为2.0),并且设置 LoRA Dropout 为0.3
【1365211】
GPT2-basebatch size =
16- AdamW
- LR:
1e-4 - warmup:2; 1e-8
- LR:
epoch =
150-
==R-Drop Loss==
alpha:
2.0-
MAE 度量函数
class RDropLoss_MAE(nn.Module): def __init__(self): super(RDropLoss_MAE, self).__init__() self.mae_loss = nn.L1Loss() def forward( self, model_output_1, model_output_2, ): loss = self.mae_loss(model_output_1, model_output_2) return loss.item()
- Regression Head ==No Dropout==
-
(768, 24)+ ReLU() +(24, 1)+ ReLU() - 初始化:截断的正态分布初始化
-
- lora
- r = 2
- alpha = 2
- dropout = 0.3
- “all”
ing -> bad end
(train_53_10.log)
train_50.log
Hard Prompt + AdaLoRA (query、value)
【2402443】
- epoch = 300
- GPT-2 Medium
- VIOLET Base
- AdamW
- LR:3e-4
- weight decay: 1e-2
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
BS = 120 ==128 会导致 32 GB 显存不足==
-
Regression Head
Linear(dim, dim//6) + Dropout(0.5) + ReLU() + Linear(dim//6, 1) + ReLU() ==一个 Dropout==
(768, 128)->(128, 1)
-
Text Prompt:
Let's think step by step. In a video that is {12.85} seconds long, the text "{I am walking around the room}" starts at moment {5} and ends at moment {10}. -
初始化方式:正态分布初始化
for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
AdaLoRA 配置:
adalora_config = AdaLoraConfig( inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.01, # 使用了 Dropout target_modules=["query", "value"] )
ing -> bad end
epoch = 148
0.1 -> 64.11
0.3 -> 50.46
0.5 -> 35.35
0.7 -> 18.31
mIoU -> 34.53
train_50.log【2】
【2033134】
epoch = 200
-
AdaLoRA 配置:
adalora_config = AdaLoraConfig( inference_mode=False, r=8, lora_alpha=8, lora_dropout=0.1, # 使用了 Dropout target_modules=["query", "value"] )
ing -> bad end
train_50.log【3】
【608349】
降低学习率:
3e-4->1e-4epoch = 200
-
Regression Head:
import torch.nn as nn nn.Sequential( nn.Linear(dim, dim // 8), # 768 * 96 nn.Dropout(0.5), nn.ReLU(True), nn.Linear(dim // 8, 1), # 96 * 1 nn.ReLU(True),
ing -> bad end
【还是会过拟合】
train_50.log【4】
【3905000】
epoch = 200
GPT-2 Medium
VIOLET Base
-
AdamW
- LR:1e-4
- weight decay: 1e-2
Warmup: 2; 1e-8
- Cosin LR:3e-4 -> 0
-
Regression Head:==No Dropout==
import torch.nn as nn nn.Sequential( nn.Linear(dim, dim // 24), # 768 * 32 nn.Dropout(0.5), nn.ReLU(True), nn.Linear(dim // 24, 1), # 32 * 1 nn.ReLU(True), )
ing -> bad end
train_54.log
脚本:train_ft_violet.py
模型:FtGPTVioletModel
Hard Prompt + Fine tuning
【3238796】
batch size = 16
epoch = 100
-
AdamW
LR:
1e-4Warmup:2;1e-8 -> 1e-4
Consin LR Decay
text prompt
-
Regression Head ==No Dropout==
import torch.nn as nn nn.Sequential( nn.Linear(dim, dim // 24), # 768 * 32 nn.ReLU(True), nn.Linear(dim // 24, 1), # 32 * 1 nn.ReLU(True), )- 初始化:
- Kainming 初始化 ==出现梯度消失==
- 截断的正态分布初始化
- 初始化:
GPT-2 base
VIOLET Base
ing -> bad end
(train_54.log)
注意:
由于之前的疏忽大意,在使用
CharadesNewDataset和CharadesEnsembleDataset时,将 Test Dataset 的 DataLoader 设置为shuffle=True、drop_last=True影响的有:==tmp_31_9==、==tmp_31_10==、==tmp_31_11==
从 ==tmp_31_10== 和 ==tmp_31_11== 开始,对代码进行了修改,
shuffle=False、drop_last=False
| 实验名\参数 | epoch & batch size | AdamW | Warmup | Regression Head | LoRA | AdaLoRA | 状态 | 结果 |
|---|---|---|---|---|---|---|---|---|
| tmp_0(Full Fine Tune) | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end | Finetune |
| tmp_0_1(Full Fine Tune) | 150, 64 | 2e-5 -> 1e-8 | 2 | ==(dim, dim//16)== + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | - | - | bad end | Finetune(Small Header) |
| tmp_0_2 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//16) + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | - | - | r-drop alpha = 1(MSE) bad end |
Finetune + ==R-Drop== |
| tmp_0_3 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//16) + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | - | - | r-drop alpha = 1(SmoothL1) bad end |
Finetune + ==R-Drop== |
| tmp_0_4 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//16) + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | - | - | r-drop alpha = 1(MAE) bad end |
Finetune + ==R-Drop== |
| ==tmp_0_5== |
150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end(效果不错) | Finetune + Prompt Ensemble |
| tmp_0_6 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//16) + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | - | - | bad end(效果差一点) | Finetune + Small Head + Prompt Ensemble |
| tmp_0_7 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//16) + dropout(0.1) + ReLU() + (dim//16, 1) + ReLU() | - | bad end(效果差一些,但比 0_6 好) | Finetune + Small Head + Prompt Ensemble | |
| tmp_0_8 |
300, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end(效果不错) | Finetune + Prompt Ensemble + Long Epoch |
| tmp_0_9 | 150, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.5) + ReLU() + (dim//8, 1) + ReLU() | - | - | bad end(运行了 137 个 epoch) | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_0_10 | 300, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.5) + ReLU() + (dim//8, 1) + ReLU() | - | - | no start now | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_0_11 | 150, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.3) + ReLU() + (dim//8, 1) + ReLU() | - | - | bad end | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_0_12 | 300, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.3) + ReLU() + (dim//8, 1) + ReLU() | - | - | no start now(只运行了 30 个 epoch) | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_0_13 | 150, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.1) + ReLU() + (dim//8, 1) + ReLU() | - | - | bad end | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_0_14 | 300, 64 | 2e-5 -> 1e-8 | 5 | (dim, dim//8) + dropout(0.1) + ReLU() + (dim//8, 1) + ReLU() | - | - | ing【886138】 | Finetune + Prompt Ensemble + Long Epoch + Big Head |
| tmp_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end | |
| tmp_1_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | ||
| tmp_2 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_q, W_v | - | bad end | LoRA |
| ==tmp_3== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all | - | bad end | LoRA |
| tmp_3_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all | - | bad end(运行了 110 个 epoch) | LoRA + Prompt Ensemble |
| tmp_4 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | lora_alpha=32, lora_dropout=0.1, W_q, W_v init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | |
| tmp_5 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | lora_alpha=32, lora_dropout=0.1, W_all, init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | |
| tmp_11 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_q, W_v | - | bad end(效果差于 alpha=16) | LoRA |
| tmp_12 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all | - | bad end(效果差于 alpha=16) | LoRA |
| tmp_12_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all | - | bad end | LoRA + Prompt Ensemble |
| tmp_12_2 | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all | - | ing【3444961】 | LoRA + Prompt Ensemble |
| tmp_12_3 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all | - | ing【】no start now | LoRA + Prompt Ensemble |
| tmp_12_4 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all, bias=all | - | no start now | LoRA + Prompt Ensemble |
| tmp_12_5 | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all, bias=all | - | no start now | LoRA + Prompt Ensemble |
| tmp_12_6 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all, bias=all | - | no start now | LoRA + Prompt Ensemble |
| tmp_13 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - |
lora_alpha=16, lora_dropout=0.1, W_q, W_v r=8, init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | AdaLoRA |
| tmp_14 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - |
lora_alpha=16, lora_dropout=0.1, r=8, W_all, init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | AdaLoRA |
| tmp_15 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=8; dropout=0.1; W_q, W_v | - | bad end | |
| tmp_16 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=8; dropout=0.1; W_all | - | bad end | LoRA |
| tmp_16_1 | ||||||||
| tmp_17 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - |
lora_alpha=8, lora_dropout=0.1, W_q, W_v r=8, init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | AdaLoRA |
| tmp_18 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - |
lora_alpha=8, lora_dropout=0.1, r=8, W_all, init_r=12, target_r=8, beta1=0.85, beta2=0.85, orth_reg_weight=0.5, tinit=200, tfinal=1000, deltaT=10, |
bad end | AdaLoRA |
| tmp_19 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=8; dropout=0.1; W_q, W_v | - | bad end | |
| tmp_20 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=8; dropout=0.1; W_all | - | bad end | |
| tmp_21 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | AdaLoRA | ||
| tmp_22 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | AdaLoRA | ||
| tmp_23 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=16; dropout=0.1; W_q, W_v | - | bad end | |
| tmp_24 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=16; dropout=0.1; W_all | - | bad end | |
| tmp_25 | AdaLoRA | |||||||
| tmp_26 | AdaLoRA | |||||||
| tmp_27 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=4; dropout=0.1; W_q, W_v | bad end | ||
| tmp_28 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=4; alpha=4; dropout=0.1; W_all | bad end | ||
| tmp_29 | AdaLoRA | |||||||
| tmp_30 | AdaLoRA | |||||||
| ==tmp_31== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA |
| ==tmp_31_1== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(运行了 100 个 epoch) | LoRA + R-Drop(SmoothL1,alpha=1) |
| ==tmp_31_2== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA + R-Drop(MSE,alpha=1)效果不好 |
| ==tmp_31_3== | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA(Long Step)效果不好 |
| ==tmp_31_4== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//16) + dropout(0.3) + ReLU() + (dim//16, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA(small header)效果很差 |
| ==tmp_31_5== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//16) + dropout(0.1) + ReLU() + (dim//16, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(没完全运行完) | LoRA(small header) |
| ==tmp_31_6== | 200, 64 | 4e-4 -> 1e-8 | 7 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(没完全运行完) | LoRA(Long Step) |
| ==tmp_31_7== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//16) + ReLU() + (dim//16, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(运行了 40 个 epoch) | LoRA(small header-no-dropout,MSE-2) |
| ==tmp_31_8== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.35) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA(0.35-dropout) |
| ==tmp_31_9== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end ==test dataloader 代码错误== | LoRA + R-Drop(MSE,alpha=2)使用预先计算好的text_features |
| ==tmp_31_10== |
150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果非常可以) | LoRA + Prompt Ensemble(增加了 3 倍) |
| tmp_31_11 | 150, 64 | 8e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果很差) | LoRA + Prompt Ensemble(增加了 3 倍、提高学习率) |
| tmp_31_12 | 150, 64 | 2e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果差一点) | LoRA + Prompt Ensemble(增加了 3 倍、降低学习率、num_worker=8) |
| tmp_31_13 | 150, 64 | 1e-3 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果很差) | LoRA + Prompt Ensemble(增加了 3 倍、提高学习率) |
| tmp_31_14 | 150, 64 | 5e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果很差) | LoRA + Prompt Ensemble(增加了 3 倍、提高学习率) |
| tmp_31_15 | 150,64 | 5e-5 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果比较差) | LoRA + Prompt Ensemble(增加了 3 倍、降低学习率) |
| ==tmp_31_16== | 150,64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果差一些) | LoRA + Prompt Ensemble(增加了 3 倍)+ R-Drop(MSE-2) |
| tmp_31_17 | 150,64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果很差) | LoRA + Prompt Ensemble(增加了 3 倍)+ R-Drop(MSE-1) |
| ==tmp_31_18== | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA + Prompt Ensemble(增加了 3 倍)+ Long Epoch |
| tmp_31_19 | 100, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end | LoRA + Prompt Ensemble(增加了 3 倍)+ Short Epoch |
| tmp_31_20 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(效果差一些) | LoRA + Prompt Ensemble(增加了 3 倍)+ Long Epoch |
| tmp_31_21 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | 效果不好 | LoRA + Prompt Ensemble + R-Drop(MSE-4) |
| tmp_31_22 |
150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(运行了 80 个 epoch) | LoRA + Prompt Ensemble + R-Drop(MSE-2) |
| tmp_31_23 |
300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(运行了 200 epoch) | LoRA + Prompt Ensemble + R-Drop(MSE-2)+ Long Epoch |
| tmp_31_24 |
300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + Dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“all” | - | bad end(运行了 80 epoch) | LoRA + Prompt Ensemble + R-Drop(MSE-1)+ Long Epoch |
| tmp_32 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_q, W_v;bias=“all” | - | bad end | LoRA |
| tmp_33 | AdaLoRA | |||||||
| tmp_34 | AdaLoRA | |||||||
| ==tmp_35== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_all;bias=“lora_only” | - | bad end | LoRA |
| tmp_36 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=16; dropout=0.1; W_q, W_v;bias=“lora_only” | - | bad end | LoRA |
| tmp_37 | AdaLoRA | |||||||
| tmp_38 | AdaLoRA | |||||||
| tmp_40 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end | BitFit |
| tmp_6 | 150, 64 | 4e-4 -> 1e-8 | 3 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | - | bad end | |
| tmp_7 | 150, 64 | 4e-4 -> 1e-8 | 3 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_q, W_v | - | ||
| tmp_8 | 150, 64 | 4e-4 -> 1e-8 | 3 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | r=8; alpha=32; dropout=0.1; W_all | - | ||
| tmp_9 | 150, 64 | 4e-4 -> 1e-8 | 3 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | |||
| tmp_10 | 150, 64 | 4e-4 -> 1e-8 | 3 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | - | |||
train_55.log【0】
与 【1】 配置一样,但是做 Full Fine Tuning
batch size =
64-
AdamW
- cosin LR:
4e-4->1e-8 - Warmup:5;
1e-8->4e-4
- cosin LR:
epoch =
150-
Regression Head:==49216, dropout=0.3==
Linear(dim, dim // 12), # (768, 64) Dropout(0.3), ReLU(), Linear(dim // 12, 1), ReLU()-
初始化:截断的正态分布
if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0)
-
-
Hard Prompt
Let's think step by step. The text of "[Text]", starts at time [MASK] and ends at time [MASK].[SEP]
ing -> bad end ==梯度消失==
(train_55_0.log)
train_loss = 0.08250
test_loss = 0.08300
【1975139】
重新尝试:
- AdamW
- cosin LR:
2e-5->1e-8 - Warmup:2;
1e-8->2e-5
- cosin LR:
- epoch =
150
ing ->
(train_55_0.log)
train_55.log【1】
模型:
FtGPTVioletModel脚本:
train_hard_prompt_violet.py
Hard prompt + Violet + BERT-large + regression head tuning
固定住 (dim, dim// 12),即
49216
【194699】
- batch size =
64 - AdamW
- cosin LR:
4e-4->1e-8 - Warmup:5;
1e-8->4e-4
- cosin LR:
epoch =
150-
Regression Head:==49216, dropout=0.3==
Linear(dim, dim // 12), # (768, 64) Dropout(0.3), ReLU(), Linear(dim // 12, 1), ReLU()-
初始化:截断的正态分布
if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0)
-
-
Hard Prompt
Let's think step by step. The text of "[Text]", starts at time [MASK] and ends at time [MASK].[SEP]
ing ->
(train_55.log)
train_55.log【2】
在 55【1】的基础上,添加 LoRA 微调 ==r=8, W_q, W_v==
【271783】
- LoRA 配置:
peft_config = LoraConfig(
# task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1
)
ing -> bad end
(train_55_2.log)
train_55.log【3】
在 55【1】的基础上,添加 LoRA 微调 ==r=8, W_q, W_k, W_v, W_o, W_f1, W_f2==
【398413】
- LoRA 配置:
peft_config = LoraConfig(
# task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1,
target_modules=["query", "key", "value", "dense"],
)
ing ->
(train_55_3.log)
train_55.log【4】
在 55【1】的基础上,添加 AdaLoRA 微调 ==r=8, W_q, W_v==
【447501】
-
AdaLoRA 配置:
adalora_config = AdaLoraConfig( inference_mode=False, # r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["query", "value"], init_r=12, target_r=8, beta1=0.85, beta2=0.85, tinit=200, tfinal=1000, deltaT=10, )
ing ->
(train_55_4.log)
train_55.log【5】
在 55【1】的基础上,添加 AdaLoRA 微调 ==r=8, W_q, W_k, W_v, W_o, W_f1, W_f2==
【2433581】
-
AdaLoRA 配置:
adalora_config = AdaLoraConfig( inference_mode=False, # r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["query", "key", "value", "dense"], init_r=12, target_r=8, beta1=0.85, beta2=0.85, tinit=200, tfinal=1000, deltaT=10, )
ing ->
(train_55_5.log)
train_55.log【6】
在 【1】 的基础上,减少 warmup 的步骤(从
5到3)
【1254840】
- warmup:
- 从
5-> 改为3 -
1e-8->4e-4
- 从
ing ->
(train_55_6.log)
train_55.log【11】
【2591248】
在 【2】 的基础上,将
lora_alpha从16->32
-
LoRA 配置:
peft_config = LoraConfig( # task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1 )
ing ->
(train_55_11.log)
train_55.log【12】
【2599539】
在 【3】 的基础上,将
lora_alpha从16->32
-
LoRA 配置:
peft_config = LoraConfig( # task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["query", "key", "value", "dense"], )
ing ->
(train_55_12.log)
P-Tuning V2
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
- URL:https://arxiv.org/abs/2110.07602
- Official Code:https://github.com/thudm/p-tuning-v2
使用 peft 的 prefix_tuning,并且使用了 ==Prompt Ensemble== 策略
NLP、NLU、NLG 的区别:什么是 NLP、NLU 和 NLG,您为什么要了解它们及其区别?
P-tuning v2 在实际上就是 Prefix-tuning,在 Prefix 部分,每一层 transformer 的 embedding 输入需要被 tuned。而 P-tuning v1 只有 transformer 第一层的 embedding 输入需要被 tuned。
假设 Prefix 部分由 50 个 token 组成,则 P-tuning v2 共有 \(50\times 12=600\) 个参数需要 tuned。
在 Prefix 部分,每一层 transformer 的输入不是从上一层输出,而是随机初始化的 embedding(需要 tuned)作为输入。
此外,P-Tuning v2 还包括以下改进:
- 移除了 Reparamerization 加速训练方式;
- 采用了多任务学习优化:基于多任务数据集的 Prompt 进行预训练,然后再适配的下游任务。
- 舍弃了词汇 Mapping 的Verbalizer 的使用,重新利用 [CLS] 和字符标签,跟传统 finetune一样利用 cls 或者 token 的输出做 NLU,以增强通用性,可以适配到序列标注任务。
P-Tuning v2 的原理是通过对已训练好的大型语言模型进行参数剪枝,得到一个更加小巧、效率更高的轻量级模型。具体地,P-Tuning v2 首先使用一种自适应的剪枝策略,对大型语言模型中的参数进行裁剪,去除其中不必要的冗余参数。然后,对于被剪枝的参数,P-Tuning v2 使用了一种特殊的压缩方法,能够更加有效地压缩参数大小,并显著减少模型微调的总参数量。
总的来说,P-Tuning v2 的核心思想是让模型变得更加轻便、更加高效,同时尽可能地保持模型的性能不受影响。这不仅可以加快模型的训练和推理速度,还可以减少模型在使用过程中的内存和计算资源消耗,让模型更适用于各种实际应用场景中。
参考:https://zhuanlan.zhihu.com/p/629327372
train_56.log
默认都是使用了 Prompt Ensemble
Charades-STA 数据集
| 实验名\参数 | epoch & batch size | AdamW | Warmup | Regression Head | num_virtual_tokens | 状态 | 结果 |
|---|---|---|---|---|---|---|---|
| tmp_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 20 | bad end | P-Tuning v2 |
| tmp_1_1 | 150, 64 | 4e-4 -> 1e-8 | 2 | ~ | 20 | bad end | P-Tuning v2 |
| tmp_1_2 | 150, 64 | 5e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 20 | bad end | P-Tuning v2 |
| tmp_1_3 | 150, 64 | ||||||
| tmp_2 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 10 | bad end(效果比 20 的差) | P-Tuning v2 |
| tmp_2_1 | 150, 64 | 4e-4 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 10 | bad end | P-Tuning v2 |
| tmp_2_2 | 150, 64 | 5e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 10 | bad end | P-Tuning v2 |
| tmp_2_3 | 150, 64 | 1e-4 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 10 | bad end | P-Tuning v2 |
| tmp_3 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 30 | bad end | P-Tuning v2 |
| tmp_4 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 40 | bad end | P-Tuning v2 |
| tmp_5 | 150, 64 | 2e-5 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 50 | ing【】 | P-Tuning v2 |
| tmp_5_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 50 | ing【】 | P-Tuning v2 |
| 60 | |||||||
| 70 | |||||||
| 80 | |||||||
| 90 | |||||||
| tmp_6 | 150, 64 | 1e-4 -> 1e-8 | 2 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_1 | 150, 64 | 1e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_2 | 100, 64 | 1e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_3 | 150, 64 | 2e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_4 | 150, 64 | 3e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| ==tmp_6_5== | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_6 | 150, 64 | 5e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_7 | 150, 64 | 1e-3 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| ==tmp_6_8== | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end(效果比 tmp_6_5 好) | P-Tuning v2 |
| ==tmp_6_9== | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end | P-Tuning v2 |
| tmp_6_10 | 500, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end(运行了 160 个 epoch) | P-Tuning v2 |
| tmp_6_11 | 250, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | ing【796732】 | P-Tuning v2 |
| tmp_6_15 | 200, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end(效果很差) | P-Tuning v2 & prefix_projection |
| tmp_6_16 | 200, 64 | 1e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | bad end(效果比较差) | P-Tuning v2 & prefix_projection |
| P-Tuning v2 & prefix_projection | |||||||
| P-Tuning v2 & prefix_projection | |||||||
| P-Tuning v2 & prefix_projection | |||||||
| P-Tuning v2 & prefix_projection | |||||||
| tmp_7_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 150 | bad end(效果不好) | P-Tuning v2 |
| tmp_8_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 200 | stop(跑了 250 个 epoch) | P-Tuning v2 |
| tmp_9_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 250 | ==0.5:44.68;0.7:27.96== | P-Tuning v2 |
| tmp_10_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | stop(跑了 200 个 epoch) | P-Tuning v2 |
| ==tmp_10_2==(重新跑 tmp_10_1) |
300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | bad end ==0.5:49.7; 0.7:34.27== | P-Tuning v2 |
| tmp_10_3 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | 效果不好 | P-Tuning v2 + BitFit |
| tmp_10_4(重新跑 tmp_10_2) | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | ing【18404】 结果与 tmp_10_2 一致 |
P-Tuning v2 |
| tmp_10_5 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | 效果不好 | P-Tuning v2 |
| tmp_10_6 | 500,64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 300 | bad end(运行了 210 个 epoch) | P-Tuning v2 |
| tmp_11_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 350 | 效果没有 300 的好 | P-Tuning v2 |
| tmp_12_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 400 | 效果没有 300 的好 | P-Tuning v2 |
| ==tmp_13_1== | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 450 | 效果差一些 | P-Tuning v2 |
| tmp_14_1 | 300, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 500 ==占用 30 GB 显存,不能再加了== | 效果不好 | P-Tuning v2 |
如果不在前面添加 “Let’s think step by step.”,效果又如何?
Prompt Tuning 论文:《The Power of Scale for Parameter-Efficient Prompt Tuning》 其中提到了 Prompt Ensembling 方法(使用多数表决):We use simple majority voting to compute predictions from the ensemble.
P-Tuning v2:《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》 是否使用 MLP Reparameter 技巧,取决于具体的数据集,对于某些数据集有提升,某些数据集则会降低性能 Prompt Length:取决于具体的任务和数据集,简单的 20,难的 100 左右
Prefix Tuning 测试与实现
ActivityNet Caption 生成
Full Tuning(Only fine tuning top 2 layer)(FT-TOP2)《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
train_57.log【P-Tuning v2 Ensemble】
ActivityNet:【P-Tuning v2】==Ensemble==
pin_memory = True、non_blocking = True
batch_size = 64
- 对于 ActivityNet,考虑将 batch_size 设置为 96,以便加速训练,而又不 OOM
CUDA_VISIBLE_DEVICES=5 nohup python -u train_hard_prompt_violet_activitynet.py > train_57_1_1.log 2>&1 &tmp_1_2:代码错误
File "/workspace/why/cpx/code/Prompt-TVG/train_hard_prompt_violet_activitynet.py", line 260, in <module> tmp_model_outputs = model_outputs["timestamps"].view(batch_size // 4, 4, 2) RuntimeError: shape '[16, 4, 2]' is invalid for input of size 8tmp_1_3:batch_size = 96
| 实验名\参数 | epoch & batch size | AdamW | Warmup | Regression Head | num_virtual_tokens | 状态 | 说明 |
|---|---|---|---|---|---|---|---|
| tmp_1_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() ==dim = 768== | 50 | kill 掉(10 个 epoch,12 小时) | P-Tuning v2 |
| tmp_1_2(与 tmp_1_1 相同) | 150,64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() ==dim = 768== | 50 | ing【6166】kill 掉 | 修改代码,测试部分也可以以 batch_size 大小进行,以便加速训练 |
| tmp_1_3(与 tmp_1_1 相同) | 150, 96 | 4e-4 -> 1e-8 | 5 | 50 | ing【6169】kill 掉 | 与 tmp_1_2 一样的代码,增大 batch_size | |
| tmp_2_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | 运行了 14 个 epoch,花了 14.22 小时 | P-Tuning v2 |
| tmp_2_2 | 150, 96 | 1e-3 -> 1e-8 | 5 | 100 | ing【7997】kill 掉 | 增大 batch_size,增大学习率 | |
| tmp_3_1 | 150 | ||||||
train_58.log【P-Tuning v2 No Ensemble】
ActivityNet:【P-Tuning v2】 ==不使用 prompt ensemble==
batch_size = 64
pin_memory = True、non_blocking = True
train_hard_prompt_violet_activitynet_simple.py脚本train_ft_violet_activitynet_simple.yaml配置文件一个 epoch:17 ~ 19 min
CUDA_VISIBLE_DEVICES=4 nohup python -u train_hard_prompt_violet_activitynet_simple.py > train_58_1_1.log 2>&1 &
| 实验名\参数 | epoch & batch size | AdamW | Warmup | Regression Head | num_virtual_tokens | 状态 | 说明 |
|---|---|---|---|---|---|---|---|
| tmp_1_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() ==dim = 768== | 50 | kill 掉 | P-Tuning v2 |
| tmp_2_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 100 | kill 掉(119 epoch) | P-Tuning v2 |
| tmp_2_2 | 150, 64 | 1e-4 -> 1e-8 | 5 | ~ | 100 | kill 掉(40 epoch) | no weight decay |
| tmp_3_1 | 150, 64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 150 | kill 掉(110 epoch) | P-Tuning v2 |
| tmp_4_1 | 150,64 | 4e-4 -> 1e-8 | 5 | (dim, dim//12) + dropout(0.3) + ReLU() + (dim//12, 1) + ReLU() | 200 | kill 掉(80 epoch) | P-Tuning v2 |
| tmp_4_2 | 150, 64 | 1e-3 -> 1e-8 | 5 | 200 | kill 掉(74 epoch) | 增大学习率 | |
| tmp_4_3 | 150, 96 | 1e-3 -> 1e-8 | 5 | 100 ==24.95GB 显存== | kill 掉(60 epoch) | 增大 batch_size、增大学习率 | |
| tmp_4_4 | 150, 96 | 1e-3 -> 1e-8 | 3 | 100 | kill 掉(60 epoch) | 增大 batch_size、增大学习率、缩小 warmup step | |
| tmp_4_5 | 150, 96 | 1e-3 -> 1e-8 | 0 | 100 | kill 掉(71 epoch) | 增大 batch_size、增大学习率、取消 warmup | |
| tmp_4_6 | 150, 96 | 1e-3 -> 1e-8 | 0 | 100 | kill 掉 | 与 tmp_4_5 一样,只是使用 torch.compile() 加速 | |
| tmp_4_7 | 150,64 | 1e-4 -> 1e-8 | 5 | 200 | no weight decay | ||
| tmp_4_8 | |||||||
| tmp_5_1 | 250 | ||||||
| tmp_6_1 | 150, 64 | 1e-4 -> 1e-8 | 3 | ~ | 300 ==24.8 显存== | kill 掉(71 epoch) | bs = 96 显存不够 |
| tmp_6_2 | 150, 64 | 2e-5 -> 1e-8 | 3 | ~ | 300 | kill 掉(41 epoch) | 降低 learning rate |
| tmp_6_3 | 150, 64 | 1e-4 -> 1e-8 | 3 | (768,64)(64,1)49216 | 300 | kill 掉(73 epoch) | 对 bias LN 设置 no weight decay |
| tmp_6_4 | 150, 64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | kill 掉(71 epoch) | 增加 learning rate,no weight decay |
| tmp_6_5 |
150, 64 | 1e-4 -> 1e-8 | 3 | (768,48)(48,1)36912 必须是 768 | 300 | kill 掉(80 epoch) | no weight decay,降低 Regression Head |
| tmp_6_6 |
150, 64 | 1e-4 -> 1e-8 | 3 | (768,32)(32,1)24576 | 300 | kill 掉(80 epoch) | no weight decay,降低 Regression Head |
| tmp_6_7 | 150, 64 | 1e-4 -> 1e-8 | 3 | (768,64)(64,1)49216 | 300 | kill 掉(73 epoch) | no weight decay,将 text_intermediate 和 video_encoder 这两个 Linear 也进行与 Regression Head 一样的初始化(正态初始化) |
| tmp_6_8 |
150, 64 | 4e-4 -> 1e-8 | 3 | (768,64)(64,1)49216 | 300 | 4卡 kill 掉(109 epoch) | 增大学习率,no weight,text & video Linear & Regression 正态初始化 |
| tmp_6_9 | 150, 64 | 4e-4 -> 1e-8 | 3 | (768,64)(64,1)49216 | 300 | kill 掉(64 epoch)==效果不好,没有 6_10 效果好== | 增大学习率,no weight,text & video Linear & Regression kaiming 初始化 kaiming_normal_
|
| tmp_6_10 |
150, 64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | (150 epoch)==>6_9, <6_8== | 增大学习率,no weight,text & video Linear & Regression xavier 初始化 xavier_uniform_
|
| tmp_6_11 | 150, 64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | ==dropout 后== kill 掉(60 epoch) | 增大学习率,no weight decay,text & video Linear 正态初始化,Regression kaiming 初始化 |
| tmp_6_12 | 150, 64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | kill 掉(与 tmp_6_8 一致) | 增大学习率,no weight,text & video Linear & Regression 正态初始化,dropout 放在 relu 后面 |
| tmp_6_13 |
150, 64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | kill 掉(105 epoch)==dropout 后== | 增大学习率,no weight decay,text & video Linear 正态初始化,Regression xavier 初始化 |
| tmp_6_14 | 150,64 | 4e-4 -> 1e-8 | 3 | ~ | 300 | ing【】 | tmp_6_9 基础上,dropout 放 ReLU 后面 |
| tmp_6_15 | 100, 64 | 4e-4 -> 1e-8 | 3 | ~ ==dropout 后== | 300 | (100 epoch) | tmp_6_8 基础上,缩短 epoch 数 |
| tmp_6_16 |
150, 64 | 4e-4 -> 1e-8 | 3 | (768,48)(48,1)36912 | 300 | ing【】 | 增大学习率,no weight decay,text & video Linear 正态初始化 |
| tmp_6_17 |
150, 64 | 4e-4 -> 1e-8 | 3 | (768,32)(32,1)24576 | 300 | ing【】 | 增大学习率,no weight decay,text & video Linear 正态初始化 |
| tmp_7_1 | 300 | no weight decay 将 |
|||||
train_59.log【LoRA】
ActivityNet ==No Ensemble==
CUDA_VISIBLE_DEVICES=4 nohup python -u train_hard_prompt_violet_activitynet_simple.py > train_58_1_1.log 2>&1 &
train_60.log【LoRA】
ActivityNet ==Ensemble==
Soft Prompt:VIOLET
脚本:train_prompt.py
Module:GPTVioletPromptModel
Charades-STA
train_44.log
Prefix Tuning(token number = 10)
【1775163】
GPT-2 Base
VIOLET Base
使用
Let's think step by step, the text of "", starts at time and ends at time对 soft prompt 进行初始化-
Regress Head
- Linear(dim, dim//2) + ReLU() + Linear(dim//2, 1) + ReLU()
-
Adam
- LR:4e-4
Warmup: 3; 1e-8
- Cosin LR:4e-4 -> 0
- BS:64
- Epoch:200
ing -> bad end
【训练不稳定,暂时先不考虑】
train_44.log【1】
【853232】
- GPT-2 Base
VIOLET Base
-
AdamW
- LR:
1e-4 - Warmup: 2; 1e-8
- LR:
BS = 16d
-
Regress Head
- Linear(dim, dim // 16) + ReLU() + Linear(dim // 16, 1) + ReLU()
(768, 48) + (48, 1) = 36864 + 48 = 36912
-
初始化:
-
截断的正态分布 ==start regression head 梯度消失==
if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0) -
尝试 kaiming 初始化
if isinstance(m, (nn.Conv2d, nn.Linear)): # nn.init.xavier_uniform_(m.weight) nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu') if isinstance(m, nn.Linear) and m.bias is not None: nn.init.constant_(m.bias, 0)
-
- Linear(dim, dim // 16) + ReLU() + Linear(dim // 16, 1) + ReLU()
epoch = 100
-
text prompt
[Learn]*10 [CLS] Let's think step by step. The text of "", starts at time [MASK] and ends at time [MASK].
ing -> bad end ==100 个 epoch 之后,还未收敛==
(train_44.log)
LoRA: VIOLET
位于 train_lora.py 脚本
从 train_31 开始
Bert:
VioletTrainModelGPT:
GPTVioletTrainModel
CUDA_VISIBLE_DEVICES=0 nohup python train_lora.py > train_31.log 2>&1 &
【1187003】 《VIOLET + LoRA + GPT-medium》
- 数据集:Charades-STA
- LoRA:
- r = 16
- lora_alpha = 1
- lora_dropout = 0.1
- BS = 100
- epoch = 50
- AdamW:
- Cosin LR Schedule
- lr = 1e-3
- lr_min = 0
- Warmup
- t = 3
- lr_init = 1e-8
- Regress
- (dim, dim // 2) + ReLU() + (dim // 2, 1) + ReLU()
- classifier
- (dim, dim) + ReLU() + (dim, 2)
- Text interdiment: Linear()
- Video Interdiment: Linear() (train_31.log) ing -> bad end (结果参见
VIOLET-LoRA-GPT2-medium-soft-prompt.png) 结果:0.1->63; 0.3->45; 0.5->27; 0.7->10; mIoU->30; 《Match Loss Loss 还未收敛》
【1734418】 重新尝试:
- 上面错误的使用了
CharadesPromptDataset,现在改为CharadesDataset类 - BS = 120
- epoch = 100
- Warmup
- t = 5
- lr_init = 1e-8
- Cosin LR Schedule
- 其他与上面一样 ing -> bad end (train_31.log) epoch=53: 0.1->59.62; 0.3->40.59; 0.5->25.45; 0.7->9.27; mIoU->27.35; 《Match Loss Loss 还未收敛》
【4032074】 重新尝试:
- BS = 120
- epoch = 200
- Warmup
- t = 5
- lr_init = 1e-8
- Cosin LR Schedule
- Regress:(dim, dim) + ReLU() + (dim, 1) + ReLU()
- Classifier:(dim, dim) + ReLU() + (dim, 2)
- Regression Loss(With Duration)No Match Loss
- Violet 添加 Position Embedding 和 Token Type Embedding
- LoRA:
- r = 8
- lora_alpha = 8
- lora_dropout = 0 (train_31.log) ing ->
【】
重新尝试:
-
由于之前考虑了 Match Loss,因此 batch 中有一半的样本是 False sample。
- 上面的实验没有去掉 False Sample,因此实际上一个 batch 只有一半会参与训练
- 经过一个 epoch 之后,数据集中只有一半会参与训练
- 因此,现在去掉 False Sample 的设置
(train_31.log)
no start now
Fine-tune: GPT-2 + Violet
位于 train_ft_violet.py 脚本
Prompt Learning + Violet:Only Regression Loss(With Duration Information)
【2120710】
数据集:Charades-STA
ckpt_violet_pretrained.ptBS = 120
epoch = 100
- AdamW:
- Cosin LR Schedule
- lr = 1e-3
- lr_min = 0
- Warmup
- t = 5
- lr_init = 1e-8
- Regress
- (dim, dim // 2) + GELU() + (dim // 2, 1) + GELU()
- classifier
- (dim, dim) + ReLU() + (dim, 2)
Text interdiment: Linear()
Video Interdiment: Linear()
只有 Regression Loss ing -> bad end (train_41.log) epoch=86: 0.1->65.67; 0.3->52.58; 0.5->36.47; 0.7->17.23; mIoU->34.91; 【3219593】
重新尝试:
epoch = 200
- Regress:
- (dim, dim) + LeakyReLU(1e-2) + (dim, 1) + LeakyReLU(1e-2) (train_41.log) ing -> bad end epoch=42: 0.1->67.26; 0.3->49.33; 0.5->31.34; 0.7->13.32; mIoU->32.35; 【3981505】 重新尝试:
维持上面不变
增加 Position Embedding + Token Type Embedding
- Regress:
- (dim, dim) + ReLU() + (dim, 1) + LeakyReLU(1e-3) (train_41.log) ing -> bad end epoch=32: 0.1->64.49; 0.3->50.27; 0.5->33.68; 0.7->15.73; mIoU->32.49; 【177677】 重新尝试:
-
由于之前考虑了 Match Loss,因此 batch 中有一半的样本是 False sample
上面的实验没有去掉 False Sample,因此实际上一个 batch 只有一半会参与训练
经过一个 epoch 之后,数据集中只有一半会参与训练
因此,现在去掉 False Sample 的设置 (train_41.log) ing -> bad end epoch=167: 0.1->64.43; 0.3->49.51; 0.5->35.08; 0.7->15.21; mIoU->33.43; 【2231585】 重新尝试:
将 epoch 从 200 提高到 500
其他不变 (train_41.log) ing -> bad end(运行了 200 个 epoch) epoch=116: 0.1->64.16; 0.3->49.94; 0.5->34.78; 0.7->16.42; mIoU->33.47; 【462973】
- Regression Head:
- Linear(idim, 512) + ReLU() + Linear(512, 1) + ReLU()
对添加了 Position Embedding 和 Type Embedding 的输入进行 LayerNorm 和 Dropout
其他保持不变 (train_43.log) ing -> bad end epoch=56: 0.1->65.70; 0.3->51.72; 0.5->36.13; 0.7->17.61; mIoU->34.71; (运行了 62 个 epoch) 【3275106】 重新尝试:
train_ft_violet.pygpt2-base替换原来的gpt2-mediumBS = 128
epoch = 200
- 改变 Regress Loss
- 不再有duration 感知了,即 GT 是 timestamp / Duration,而不再是原来的 Duration
- 修改模型训练过程的前向代码
- 错误的使用了 False Video Mask
- 改为了 Video Mask
- Regression Head:
- Linear(idim, idim) + ReLU() + Linear(idim, 1) + ReLU()
-
Adam:
- Cosin LR Schedule
- lr = 4e-4
- lr_min = 0
- Warmup
t = 3
-
lr_init = 1e-8
(train_43.log) ing -> bad end 《过拟合》
【3376645】 重新尝试:
-
train_prompt.py、prompt_tuning.py - 保持 43 的设置不变
- No warmup
- BS = 64
- 使用 Soft Prompt
- 使用
Let's think step by step, the text of, starts at time and ends at time对 Prompt 进行初始化 - 使用
gpt2-baseTokenizer、Model (train_44.log) ing -> bad end epoch = 136: 0.1->47.35: 0.3->26.32; 0.5->14.45; 0.7->5.21; mIoU->19.00; 【1265974】 重新尝试: - BS = 64
- Regression Head:
- Linear(idim, idim // 2) + ReLU() + Linear(idim // 2, 1) + ReLU()
- Warmup
- t = 3
- lr_init = 1e-8 (train_44.log)
ing -> 暂时停止
0.1->46; 0.3->; 0.5->; 0.7->; mIoU->;
【614445】
- BS = 120
- epoch = 500
- Charades-STA 数据集
- AdamW:
- Cosin LR Schedule
- lr = 1e-3
- lr_min = 0
- Warmup
- t = 5
- lr_init = 1e-8
- Regression Head:
- Linear(idim, 512) + ReLU() + Linear(512, 1) + ReLU()
- Text interdiment: Linear()
- Video Interdiment: Linear()
- 只有 Regression Loss
- 对添加了 Position Embedding 和 Type Embedding 的输入进行 LayerNorm 和 Dropout
- 改为使用 UniVL 模型,替换掉上面使用的 Violet 模型 (train_44.log) ing -> bad end epoch=127: 0.1->;65.16 0.3->50.35; 0.5->34.57; 0.7->17.77; mIoU->34.09; 【3667586】 重新尝试:
train_prompt.py- 保持上面的配置
- BS = 64
- 改变 Regress Loss
- 不再有duration 感知了,即 GT 是 timestamp / Duration,而不再是原来的 Duration
- 修改模型训练过程的前向代码
- 错误的使用了 False Video Mask
- 改为了 Video Mask
- 使用 Soft Prompt Tuning
(train_44.log) ing -> bad end
在 44 的基础上,对 UniVL 模型也进行微调
- Charades-STA 数据集
- BS = 64
- epoch=500
- AdamW:
- Cosin LR Schedule
- lr = 5e-4
- lr_min = 0
- Warmup
- t = 5
- lr_init = 1e-8
- Regress Head
- Linear(idim, 512) + nn.ReLU(True), + Linear(512, 1) 【3410196】 重新修改:
- 对 UniVL 不进行微调
- AdamW:
- Cosin LR Schedule
- lr = 1e-4
- lr_min = 0
- Warmup
- t = 3
- lr_init = 1e-8
- BS = 256
- epoch = 200
- 修改模型训练过程的前向代码
- 错误的使用了 False Video Mask
- 改为了 Video Mask
- Regress Loss
- 不再有duration 感知了,即 GT 是 timestamp / Duration,而不再是原来的 Duration
- Regress Head
- Linear(idim, idim) + nn.ReLU(True) + Linear(idim, 1) + nn.ReLU(True) (train_45.log) ing -> bad end
PLPNet:https://github.com/sizhelee/PLPNet
Charades-STA:
Linear(idim, 512) + ReLU() + Linear(512, 2) + ReLU()
ActivityNet Captions:
Linear(idim, 512) + ReLU() + Linear(512, 2) + Sigmoid()
使用 nn.SmoothL1Loss() 作为 Regression Loss
【3349707】
- 使用
ckpt_violet_msrvtt-retrieval.pt模型,在 MSRVTT 数据集上进行 Retrieval 微调- 替代上面
train_41.log中使用的ckpt_violet_pretrained.pt
- 替代上面
- 其他不变 (train_42.log) ing -> bad end epoch=32: 0.1->63.49; 0.3->49.78; 0.5->33.44; 0.7->14.35; mIoU->32.62; 【3838756】 重新尝试:
- 在 Violet 上添加 Position Embedding 和 Toekn Type Embedding
- 其他不变
(train_42.log) ing -> bad end epoch=161:0.1->64.03; 0.3->50.24; 0.5->34.56; 0.7->15.89; mIoU->33.39;
【2062002】 重新尝试:
-
由于之前考虑了 Match Loss,因此 batch 中有一半的样本是 False sample。
上面的实验没有去掉 False Sample,因此实际上一个 batch 只有一半会参与训练
经过一个 epoch 之后,数据集中只有一半会参与训练
因此,现在去掉 False Sample 的设置
(train_42.log)
ing -> bad end
epoch=107: 0.1->; 0.3->; 0.5->; 0.7->; mIoU->;
【】
ckpt_violet_pretrained.pt- Prompt Tuning
- 使用 MLP 预测时刻值而非 [0, 1] 的范围值
- Charades-STA 数据集
- BS = 120
- Epoch = 500
- AdamW
- lr = 1e-3
- 没有衰减
- Warmup
- t = 5
- init_lr = 1e-8
- Regression Head:
- Linear(idim, 512) + ReLU() + Linear(512, 1) + ReLU()
- 增加 Position Embedding + Token Type Embedding
(train_43.log)
no start now
参考
- 论文:
- 知乎:
-
苏剑林博客:
- 知乎回答:唐翔昊
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-04-28-pre-norm-and-post-norm/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)