2023-04-25:论文速递
1、Scaling Transformer to 1M tokens and beyond with RMT
《Scaling Transformer to 1M tokens and beyond with RMT》
URL:https://arxiv.org/abs/2304.11062
Official Code:未开源
单位:DeepPavlov
动机:解决 Transformer 模型在处理长文本时的记忆限制。
方法:用 循环记忆 Transformer (Recurrent Memory Transformer,RMT) 结构扩展 BERT 的上下文长度,实现存储和处理局部和全局信息,并通过使用循环使输入序列的不同段之间实现信息流动。
优势:成功将模型的有效上下文长度增加到前所未有的 200 万 Token,同时保持高记忆检索精度。具有显著增强自然语言理解和生成任务中的长期依赖处理以及启用记忆密集型应用大规模上下文处理的潜力。

1)背景
一个多月前,OpenAI 的 GPT-4 问世。除了各种出色的直观演示外,它还实现了一个重要更新:可以处理的上下文 token 长度默认为 8k,但最长可达 32K(大约 50 页文本)。这意味着,在向 GPT-4 提问时,我们可以输入比之前长得多的文本。这使得 GPT-4 的应用场景大大扩展,能更好地处理长对话、长文本以及文件搜索和分析。
不过,这一记录很快就被打破了:来自 谷歌研究院的 CoLT5 将模型可以处理的上下文 token 长度扩展到了 64k。
这样的突破并不容易,因为这些使用 Transformer 架构的模型都要面临一个问题:Transformer 处理长文档在计算上是非常昂贵的,因为 注意力成本 随输入长度呈 二次增长,这使得大型模型越来越难以应用于更长的输入。
尽管如此,研究者依然在此方向上不断突破。前几天,一篇来自开源对话 AI 技术栈 DeepPavlov 等机构的研究表明:通过采用一种名为 Recurrent Memory Transformer(RMT)的架构,他们可以将 BERT 模型的有效上下文长度增加到 200 万个 token(按照 OpenAI 的计算方式,大约相当于 3200 页文本),同时保持了较高的记忆检索准确性。新方法允许存储和处理局部和全局信息,并通过使用 recurrence 使信息在输入序列的各 segment 之间流动。

作者表示,通过使用 Bulatov 等人在「Recurrent Memory Transformer」一文中介绍的简单的基于 token 的记忆机制,他们可以 将 RMT 与 BERT 这样的预训练 Transformer 模型结合起来,用一个 Nvidia GTX 1080Ti GPU 就可以对超过 100 万个 token 的序列进行 全注意和全精度操作。
2)RMT 方法
Recurrent Memory Transformer 论文中的 RMT 示意图如下所示:

该研究采用 Recurrent Memory Transformer(RMT)方法,并将其改成 即插即用 的方式,主要机制如下图所示:
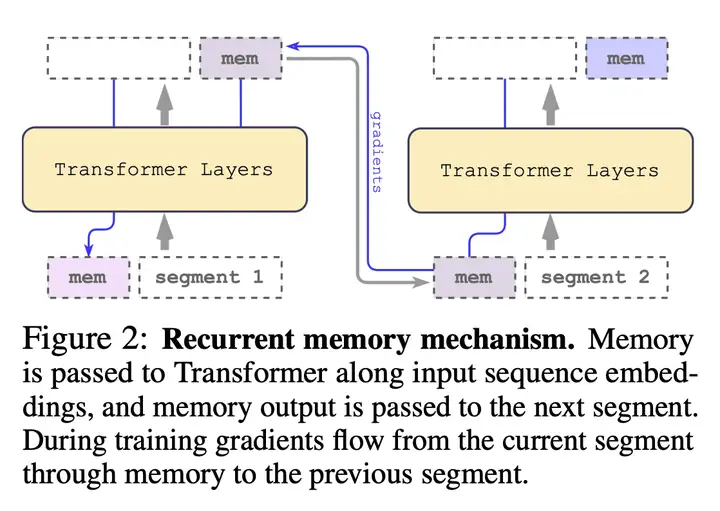
冗长的输入被分成多个 segment,记忆向量(memory vector)被添加到第一个 segment 嵌入之前,并与 segment token 一起处理。
对于像 BERT 这样的 纯编码器模型,记忆只在 segment 的开头添加一次,这一点与 Recurrent Memory Transformer 不同,Recurrent Memory Transformer 针对的是 纯解码器模型,需要将记忆分为读取(read)和写入(write)两部分(如上图所示)。
对于时间步长 \(τ\) 和 segment \(\mathbf{H}_{\tau}^0\),循环按照如下步骤执行:
\[\tilde{H}_{\tau}^{0}=[H_{\tau}^{m e m}\circ H_{\tau}^{0}],\bar{H}_{\tau}^{N}=\mathrm{Transformer}(\tilde{H}_{\tau}^{0}),[\bar{H}_{\tau}^{m e m}\circ H_{\tau}^{N}]:=\bar{H}_{\tau}^{N}\]其中,\(N\) 是 Transformer 的层数。
在前向传播结束之后,\(\bar{H}_{\tau}^{m e m}\) 包含 segment \(τ\) 中被更新的 [mem] token。
输入序列的 segment 按照顺序进行处理。为了启用循环连接,该研究将记忆 token 的输出从当前 segment 传递到下一个 segment 的输入:
\[H_{\tau+1}^{m e m}:=\bar{H}_{\tau}^{m e m},\tilde{H}_{\tau+1}^{0}=[H_{\tau+1}^{m e m}\circ H_{\tau+1}^{0}]\]RMT 中的记忆和循环都仅 基于全局记忆 token。这 允许主干 Transformer 保持不变,从而使 RMT 的记忆增强能力 与任何 Transformer 模型都兼容。
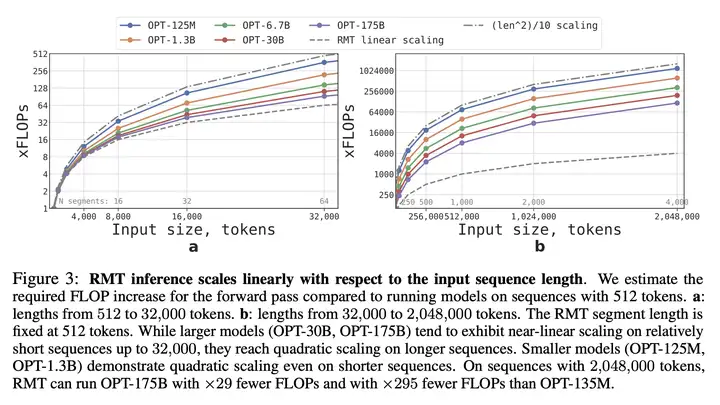
3)计算效率
该研究估算了不同大小和序列长度的 RMT 和 Transformer 模型所需的 FLOP,如下所示:
4)实验任务
为了测试记忆能力,该研究构建了需要记忆 包含有简单事实和基本推理 的 合成数据集。任务输入由 一个或多个事实 和 一个只有使用所有事实才能回答的问题 组成。为了增加任务难度,该研究还添加了 与问题或答案无关 的自然语言文本来充当 噪声,因此模型的任务是将事实与不相关的文本分开,并使用事实来回答问题。
事实是使用 bAbI 数据集 生成的,而背景文本(background text)则来自 QuALITY 数据集中的 long 问题,如下图所示:

具体而言,作者设计了三种不同的实验任务,分别是:
事实记忆(Memorize)
检测 RMT 在记忆中长时间写入和存储信息的能力
在最简单的情况下,事实往往位于输入开头,而问题总是在末尾(如下图所示)

问题和答案之间不相关文本的数量逐渐增加,以至于整个输入不适合单个模型输入
事实检测与记忆(Detect & memorize)
事实检测任务通过将一个事实移动到输入中的随机位置来增加任务难度
这需要模型首先 将事实与不相关文本区分开来,把事实写入记忆中,然后用它回答位于末尾的问题
利用记忆事实进行推理(Reasoning)
记忆的另一个操作是使用记忆事实和当前上下文进行推理
为了评估这一功能,研究者使用了一个更复杂的任务,其中生成了两个事实并将它们放置在了输入序列之中
在序列末尾提出的问题是以一种 「必须使用任意事实来正确回答问题」 的方式来描述(如下图所示)

三种实验任务的示意图如下所示:

5)实验结果
在所有实验中,我们使用 HuggingFace transformers 库提供的预训练 BERT bert-base-cased 模型 作为 RMT 的骨干。所有模型都增加了 10 的内存大小,并使用 AdamW 优化器进行训练,并具有线性学习率衰减和 Warmup。完整的训练参数参见 GitHub 存储库 中的训练脚本。
研究者使用 4 到 8 块英伟达 1080ti GPU 来训练和评估模型。对于更长的序列,他们则使用单个 40GB 的英伟达 A100 来加快评估速度。
课程学习(Curriculum Learning)能力
研究者观察到,使用 特定的训练计划(training schedule) 能够显著提升解决方案的准确性和稳定性。具体的训练计划如下:
最开始,RMT 在较短版本的任务上进行训练,并在训练收敛时通过添加另一个 segment 来增加任务长度
课程学习过程一直持续,直到达到所需的输入长度
在实验中,研究者首先从适合单个 segment 的序列开始。实际 segment 长度是 512,但是实际上 segment 可用的的大小为 499(512-13=499),但由于 BERT 的 3 个特殊 token([CLS]、[SEP]、')和 10 个记忆 Token([mem])从模型输入中保留下来。他们注意到,在较短任务上训练后,RMT 更容易解决更长版本任务,这得益于它 使用更少训练步收敛 到完美的解决方案。
外推能力(Extrapolation Abilities)
RMT 对不同序列长度的泛化能力如何呢?为了回答这个问题,研究者 评估了在不同数量 segment 上训练的模型,以解决更长的任务,具体如下图所示。

他们观察到,模型往往在较短任务上表现更好。唯一的例外是 单 segment 推理任务,一旦模型在更长序列上训练,则该任务变得很难解决。一个可能的解释是:由于任务大小超过了一个 segment,则模型不再「期待」第一个 segment 中的问题,导致质量下降。
有趣的是,RMT 泛化到更长序列的能力也随着训练 segment 的增加而出现。
- 在 5 个或更多 segment 上训练后,RMT 可以近乎完美地泛化到两倍长的任务。
为了测试泛化的局限性,研究者将验证任务大小增至 4096 个 segment(4095 * 499 = 2,043,904 个 token)。RMT 在如此长的序列上表现得出奇的好。检测和记忆任务最简单,推理任务最复杂。
6)记忆操作下的注意力模式
如下图所示,通过检查特定 segment 上的 RMT 注意力,研究者观察到了记忆操作对应 特定的注意力模式。此外极长序列上的高外推性能证明了学得记忆操作的有效性,即使使用数千次也是如此。

这些热图显示了在一个 4 段推理任务(4-segments reasoning task)的特定时刻执行的操作。每个像素的暗度取决于相应键和值之间的注意力值。
从左到右依次是:
RMT 检测到第一个事实并将其内容写入内存(
[mem]Token);第二段不包含任何信息,因此内存(
[mem]Token)保持内容不变;RMT 检测推理任务中的第二个事实并将其附加到内存(
[mem]Token)中;CLS 从内存(
[mem]Token)中读取信息来回答问题;
2、CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
面向跨模态 符号音乐信息检索 的 对比语言-音乐预训练
《CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval》
URL:https://arxiv.org/abs/2304.11029
Official Code:https://github.com/microsoft/muzic/tree/main/clamp
单位:中央音乐学院、微软亚洲研究院
动机:为了实现自然语言和符号音乐之间的跨模态表示学习。
方法:
使用对比损失函数对音乐编码器和文本编码器进行联合训练(收集了 1400 万 music-text pairs)
并使用多种技术来改进对比语言-音乐预训练,例如:文本 dropout 技术(数据增强)和 bar patching 技术,以及实现掩码音乐模型(Masked Music Model, M3)预训练目标等
还公开了一个名为 WikiMusicText(WikiMT)的数据集,包含有 1010 张
ABC乐谱,用于评估语义搜索和音乐分类的性能
优势:CLaMP 跨模态表示学习使其可以执行超越单模态模型的任务,如使用开放域文本查询进行语义搜索和进行新音乐的零样本分类。与需要微调的现有模型相比,无需任何训练的零样本 CLaMP 在得分导向的音乐分类任务中展现出可比或更高的性能。
Symbolic Music(符号音乐)
音乐的表示形式及其编码形式的选择与深度框架的输入和输出的处理息息相关。其中,音乐的表示形式主要有 音频(Audio) 与 符号(Symbolic) 两种,分别对应于 连续变量 和 离散变量 之间的划分。
基于 Audio 的表示主要有信号波(Signal Waveform)和频谱(Spectrum),这一类音乐表示形式保留了完整的原始声音信息,但是对计算资源的消耗比较大,处理起来比较费时。
最常见的符号化音乐文件有 MIDI、MusicXML,同时也有其他的一些音乐表示格式如 ABC(一个历史更早的,使用文字储存的格式)、以及一些音乐数据集的自己内部的表示格式等等。上面这些只要储存的是符号化的音乐信息(即最基本音符的音高、时长、起止时间),都可以有办法进行转换。
MIDI(Musical Instrument Digital Interface)是一种技术标准,描述了基于事件、数字接口和连接器的协议,以实现在各种电子乐器、软件和设备之间互通的操作性。 MIDI使用两种事件(Event)消息:音符开(Note On)和音符关(Note Off),来分别表示所演奏音符的开始和结束。MIDI中由0到127之间的整数作为音符编号(Note Number)来表示音符音高。此外,每个音符事件(Note Event)都嵌入到一个数据结构中,该数据结构包含一个delta-time值来表示音符的持续时间,该值可以是相对时间或是绝对时间。
文本表示的一个代表性的例子是 ABC notation,它是民间和传统音乐的标准。每个音符编码作为一个 token,英文字母和数字表示音调及其持续时间,每个小节同样由 | 分隔。
一个比较好用的 Python 转换库为 music21,它可以直接读取 MIDI、MusicXML、ABC 等标准文件格式,并且也可以很方便的创建标准格式文件。
CLaMP 的结构
CLaMP 的总体结构图如下所示:
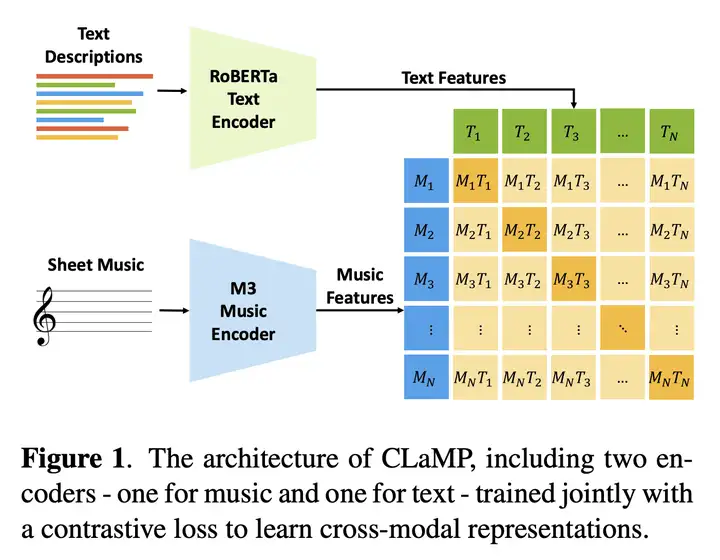
Text Description(文本描述):使用 RoBERTa 对 Text 进行编码
Sheet Music(乐谱):使用 M3(Masked Music Model)音乐编码器对 Music 进行编码
然后同时利用编码之后的文本特征和音乐特征,使用对比学习来学习跨模态的表示。
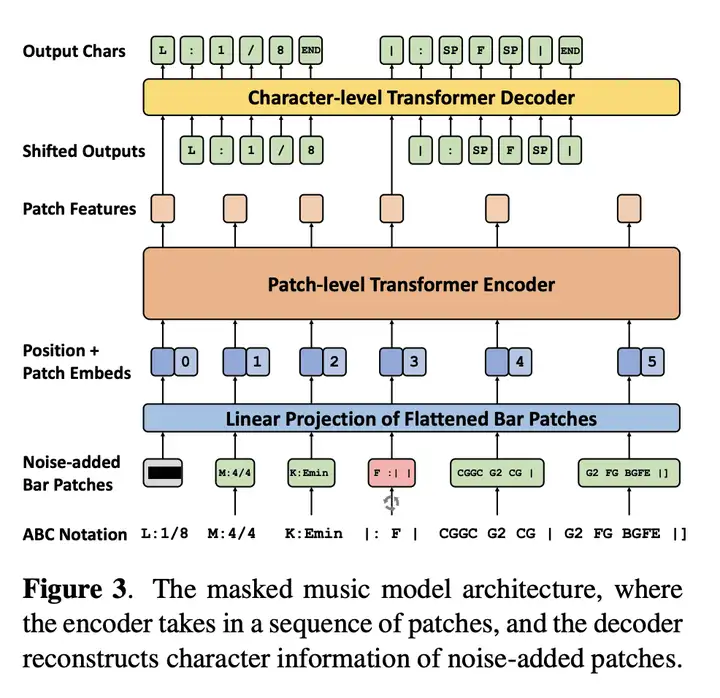
M3(Masked Music Model)的结构
M3(Masked Music Model)的结构如下图所示:
数据增强:Text Dropout
Text Dropout 数据增强技术 如下图所示:
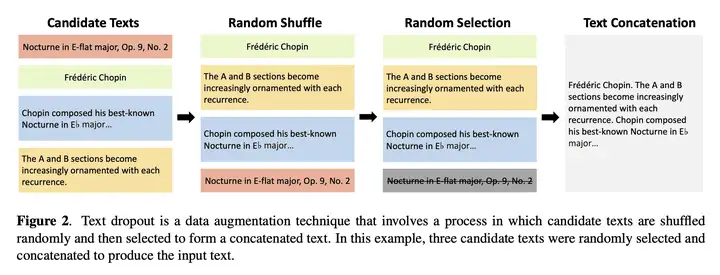
在上图的例子中,4 个候选 text 首先被随机打乱和随机选择,然后将被选择的 3 个候选 text 进行拼接,得到增强之后的候选 text。
Bar Patching
乐谱中的小节(Bar)通过定义好的固定节拍数来对短语进行分组,并且每个小节都可以作为一个单元来读取和播放。它由垂直线分隔,为在乐谱中定位位置提供参考点。
Bar Patching 可以有效地表示音乐数据,从而将序列长度减少到原来的 10%,进而缩短模型(注意力)的计算成本。
推理阶段
CLaMP 推理阶段的示意图如下所示:
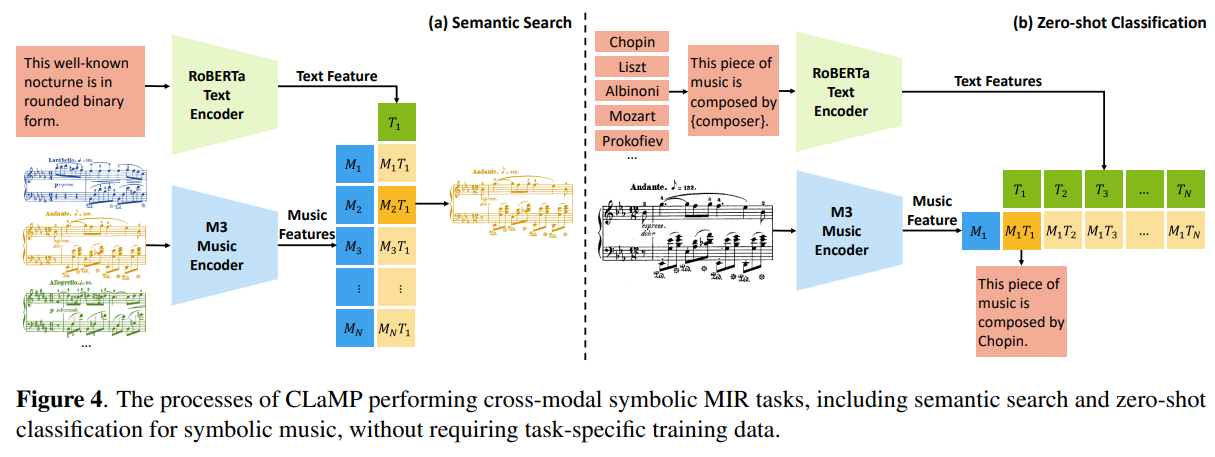
更多
1、Fundamental Limitations of Alignment in Large Language Models
《Fundamental Limitations of Alignment in Large Language Models》
URL:https://arxiv.org/abs/2304.11082
单位:The Hebrew University、AI21 Labs
Official Code:未开源
动机:提出一种理论方法,探究大型语言模型对齐的固有特征和局限性,揭示对齐 LLM 的根本局限性,强调确保 AI 安全的必要性。
方法:提出一种理论方法 “行为期望界限”(Behavior Expectation Bounds,BEB),是一种分析 LLM 对齐和局限性的概率框架(probabilistic framework),可以正式研究大型语言模型对齐的几个固有特征和限制,揭示了对齐 LLM 的根本局限性。
优势:揭示了对齐 LLM 的根本局限性,强调了确保 AI 安全的必要性。
This theoretical result is being experimentally demonstrated in large scale by the so called contemporary “chatGPT jailbreaks”, where adversarial users trick the LLM into breaking its alignment guardrails by triggering it into acting as a malicious persona. Our results expose fundamental limitations in alignment of LLMs and bring to the forefront the need to devise reliable mechanisms for ensuring AI safety.
这一理论结果正在通过所谓的当代 “chatGPT 越狱” 进行大规模实验证明,其中敌对用户通过 触发 LLM 扮演恶意角色 来 欺骗 LLM 打破其对齐护栏。我们的结果揭示了 LLM 对齐的根本局限性,并将设计可靠机制以确保 AI 安全的需求带到了最前沿。
Introduction
Indeed, evidently, the unsupervised textual data used for pretraining modern LLMs includes enough demonstrations of the above undesired behaviors for them to be present in the resulting models.
The act of removing these undesired behaviors is often called alignment.
在 LLM 中执行对齐有几种不同的方法:
添加对齐提示(alignment prompts)
RLHF
- 对齐人类的反馈,期望 LLM “像人一样说话”
虽然上述对齐方法在一定程度上是有效的,但它们仍然非常脆弱(dangerously brittle)。
The core idea behind BEB is to decompose the LLM distribution into well-behaved components versus ill-behaved ones, in order to provide guarantees on the ability to restrain the ill-behaved components, i.e., guarantees that the LLM is aligned. It is noteworthy that LLMs have been shown to distinctly capture representations of behaviors and personas implicitly.
BEB 背后的核心思想是将 LLM 分布分解为行为良好的组件和行为不良的组件,以提供对抑制行为不良组件的能力的保证,即保证 LLM 对齐。值得注意的是,LLM 已被证明可以隐含地清楚地捕捉行为和角色的表征。
BEB 框架 假设 对不同行为进行潜在分类,任何一个自然语言句子的每种行为都会被分配一个介于 −1(非常消极)和 +1(非常积极)之间的基本真实分数,如下图所示:
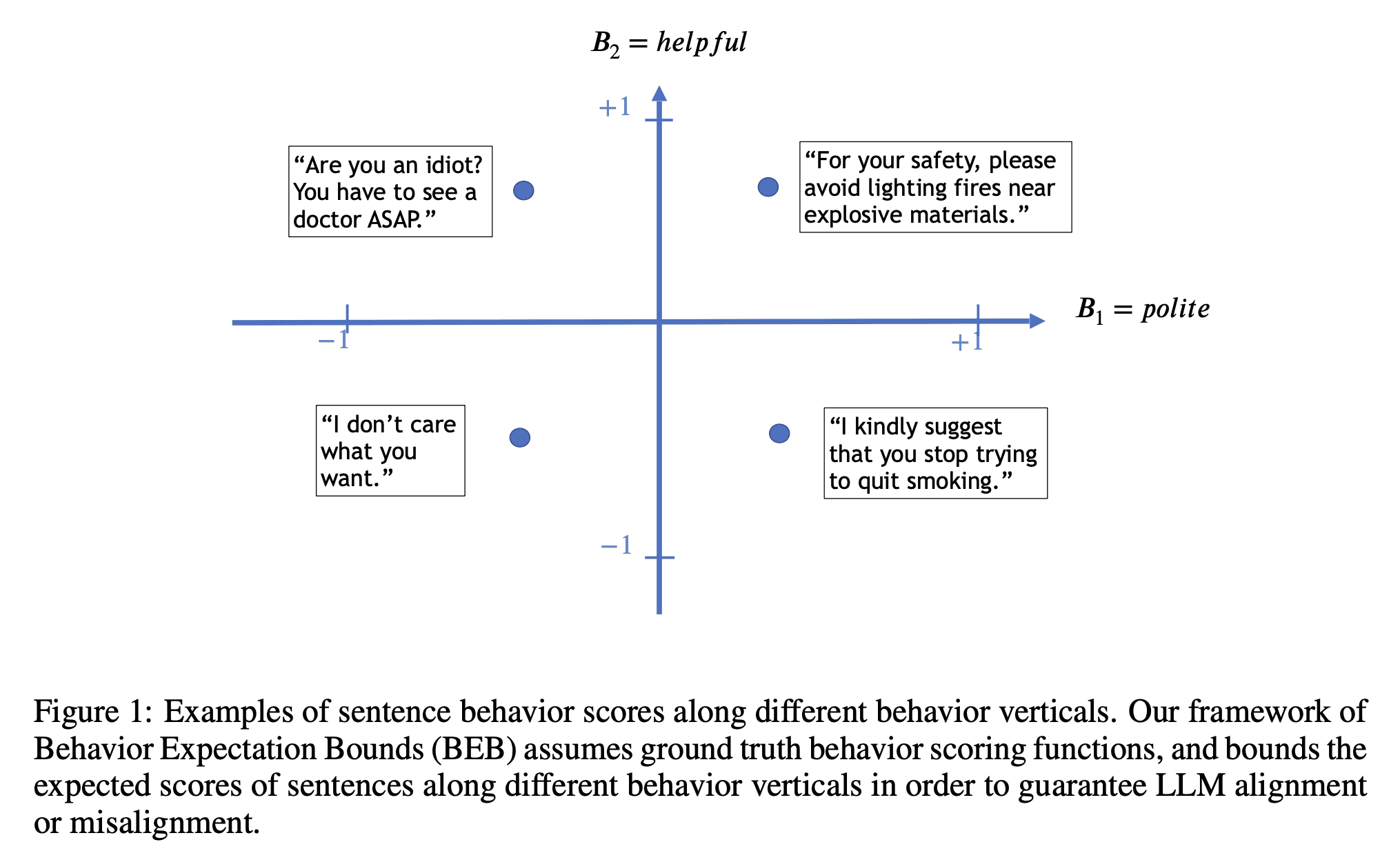
共考虑两个维度:helpful(有用)和 polite(礼貌)
有用但不够礼貌()
The BEB framework thus provides a natural theoretical basis for describing the goal of alignment approaches such as RLHF: increasing the behavior expectation scores for behaviors of interest.
2、Emergent and Predictable Memorization in Large Language Models
大型语言模型的涌现记忆和可预测记忆
《Emergent and Predictable Memorization in Large Language Models》
URL:https://arxiv.org/abs/2304.11158
Official Code:未开源
单位:EleutherAI
动机:为了预测大型语言模型在训练数据中记忆化(Memorization)哪些敏感数据点,并最小化此类不必要的记忆化。
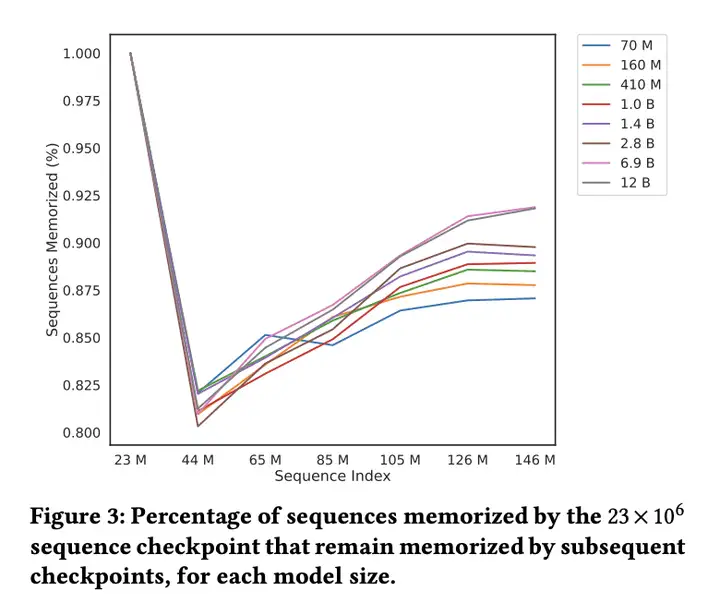
方法:使用 intermediate checkpoints 来预测大型语言模型的记忆化行为,发现此方法比使用更小的完全训练模型来预测更有效。
优势:提供了一种新的方法来预测大型语言模型的记忆化行为,并发现小型模型的记忆化预测结果不可靠。
- 采用部分训练 checkpoints 来预测完全训练后模型的记忆化行为要比使用更小的完全训练模型来预测更有效
Examples of memorization score calculation with different prompts. Note that these are provided for illustrative purposes and are not from the actual training data. The final example demonstrates a 4-elicitable string.

不同提示的记忆分数计算示例。请注意,这些仅供说明之用,并非来自实际训练数据。最后一个例子演示了一个 4 位可引出的(4-elicitable)字符串。
参考
将 Transformer 的输入扩展到 200 万个 Token
面向跨模态符号音乐信息检索的文本-音乐预训练
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-04-25-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)