2023-04-21:论文速递
1、Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
Chameleon: 大型语言模型的即插即用组合推理
《Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models》
URL:https://arxiv.org/abs/2304.09842
Official Code:https://github.com/lupantech/chameleon-llm
项目主页:https://chameleon-llm.github.io/
单位:加州大学洛杉矶分校、微软
动机:大型语言模型 (LLM) 在自然语言处理的各种任务中取得了显著的进展,但仍面临 各种固有限制,如 无法访问最新信息、利用外部工具或进行精确的数学推理,本文旨在应对这些挑战。
方法:开发了一个 即插即用的组合推理框架:Chameleon(变色龙),有效利用大型语言模型来解决它们固有的限制,并应对各种推理任务。成功 组合 了 各种工具,包括 LLM 模型、现成的视觉模型、网络搜索引擎、Python 函数和基于规则的模块,以构建一个多功能、可自适应的人工智能系统 来回答现实世界的查询。
- 使用 GPT-4 作为底层的 LLM,并且通过实验表明:相比 ChatGPT 等其他的 LLM,GPT-4 的表现更好。
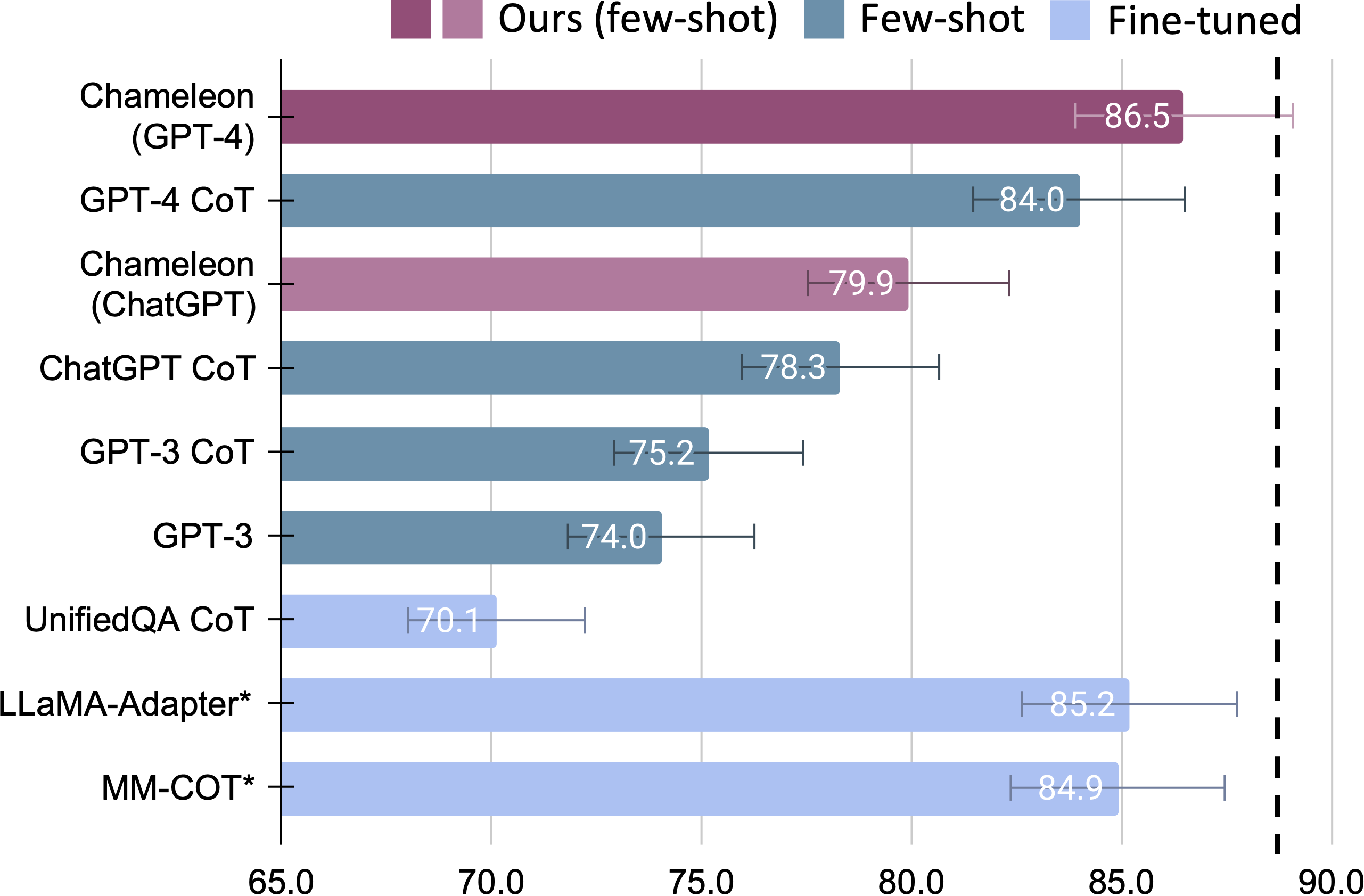
优势:在两个不同的基准测试中展示了该框架的自适应性和有效性,分别是 ScienceQA 和 TabMWP,显著提升了现有的少样本和最先进模型的准确性。Chameleon 展示了它在各种领域解决实际查询的潜力。
提出名为 “Chameleon” 的即插即用组合推理框架,可增强大型语言模型 (LLM) 以解决其固有限制,帮助应对各种推理任务。
Chameleon 能合成程序以组合各种工具,包括 LLM 模型、现成的视觉模型、网络搜索引擎、Python 函数和基于规则的模块,以满足用户的兴趣。
在 LLM 作为 自然语言规划器 的基础上构建,Chameleon 可以推断出 适当的工具组合序列 来生成最终的响应。
本研究在两个任务中展示了 Chameleon 的自适应性和有效性。
示例
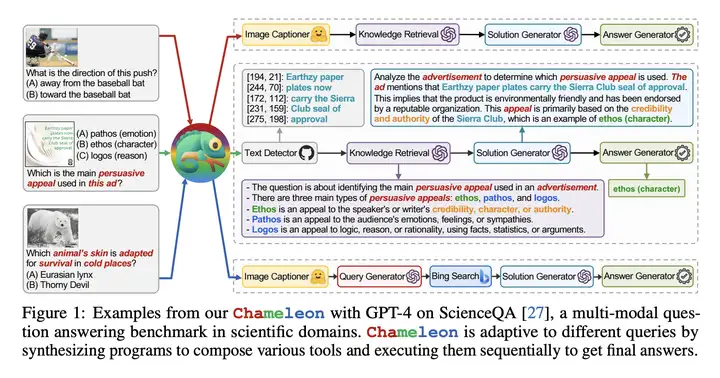
Language Planner 将 各种工具的描述、Queation to Modules 序列 的例子(Few-Shot)添加到 Prompt 中,从而激发 Language Planer 预测接下来的问题所需要使用的 Tool Modules 序列。
Language Planner 在 ScienceQA 数据集上具体使用的 Prompt 如下图所示:

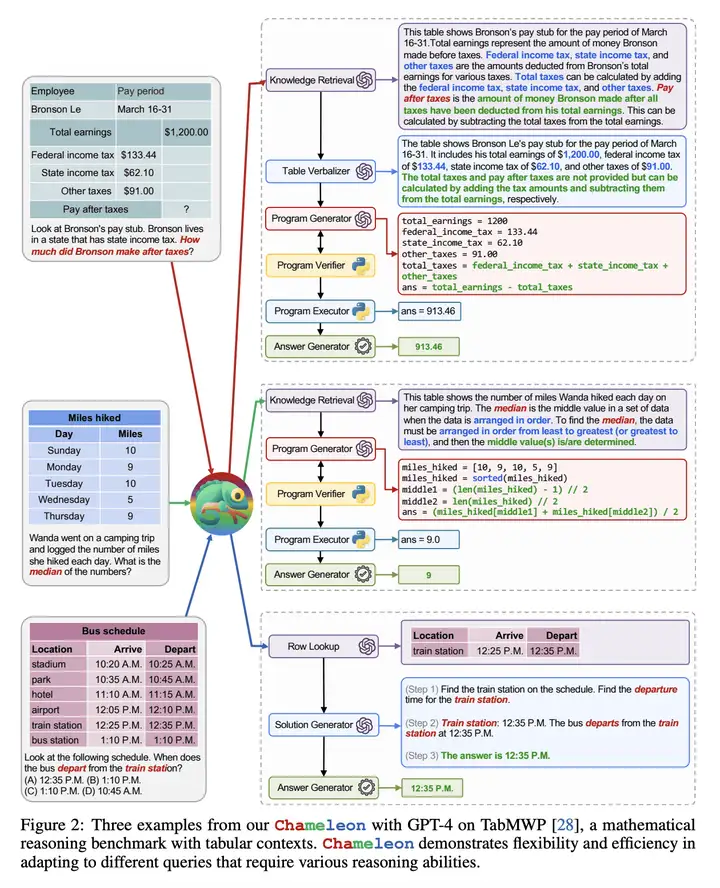
Language Planer 在 TabMWP 数据集上具体使用的 Prompt 如下图所示:

工具库
Chameleon 的工具库有非常多的工具,如下图所示:

而具体到 ScienceQA 和 TabMWP 这两个数据集,则主要使用了下面的一些工具(如下图所示):

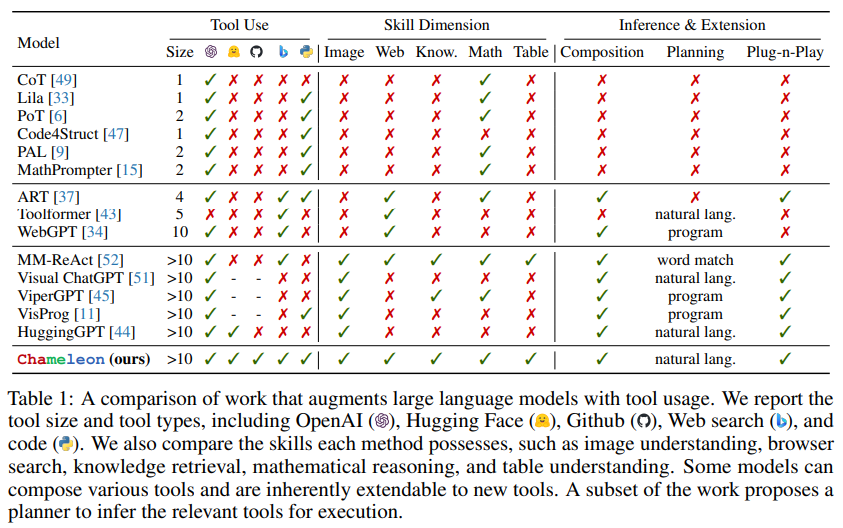
Chameleon 与其他工作(使用工具增强 LLM)的对比
实验结果
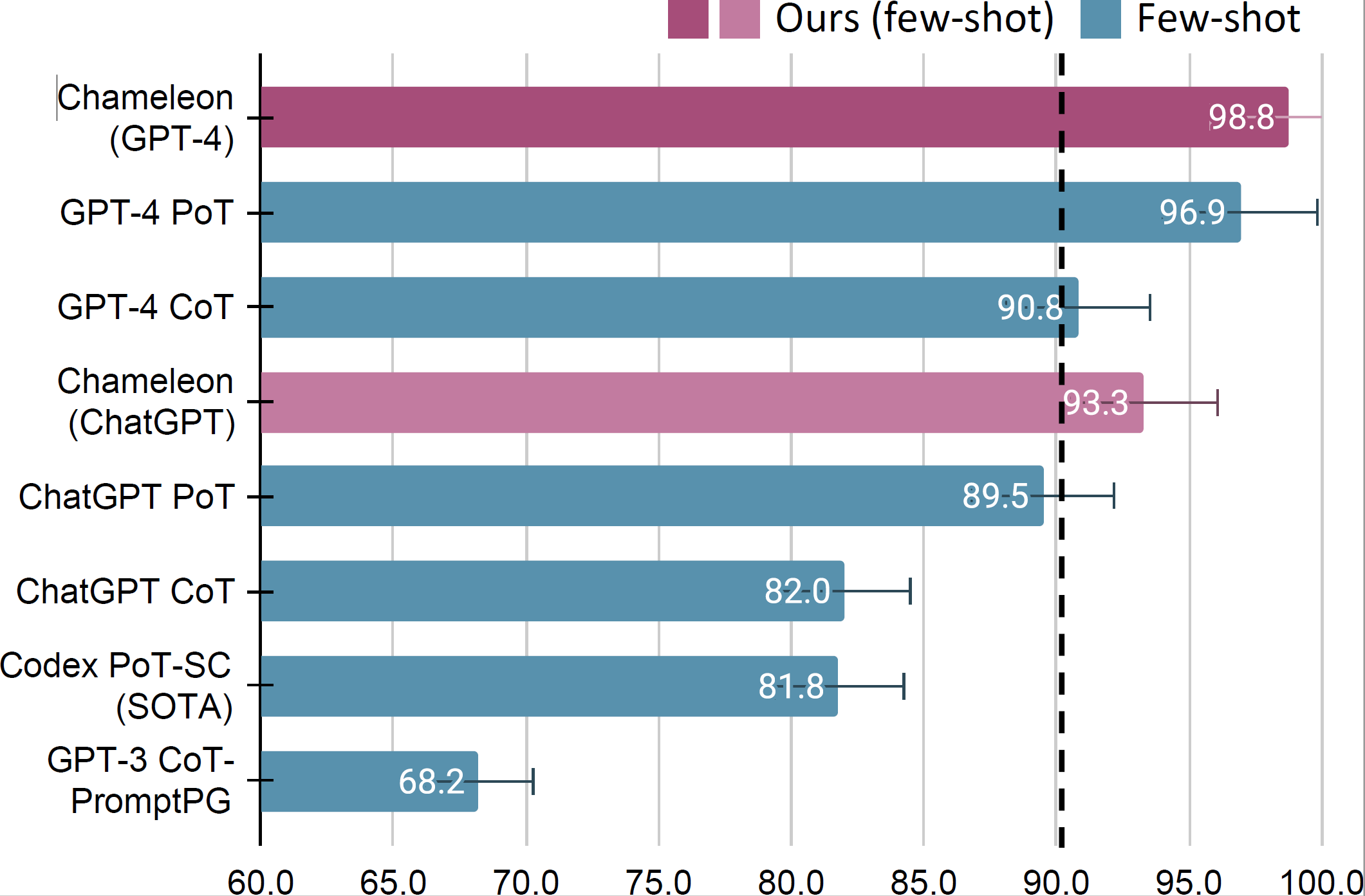
Chameleon 在 ScienceQA 数据集上的实验结果,如下图所示:
Chameleon 在 TabMWP 数据集上的实验结果,如下图所示:
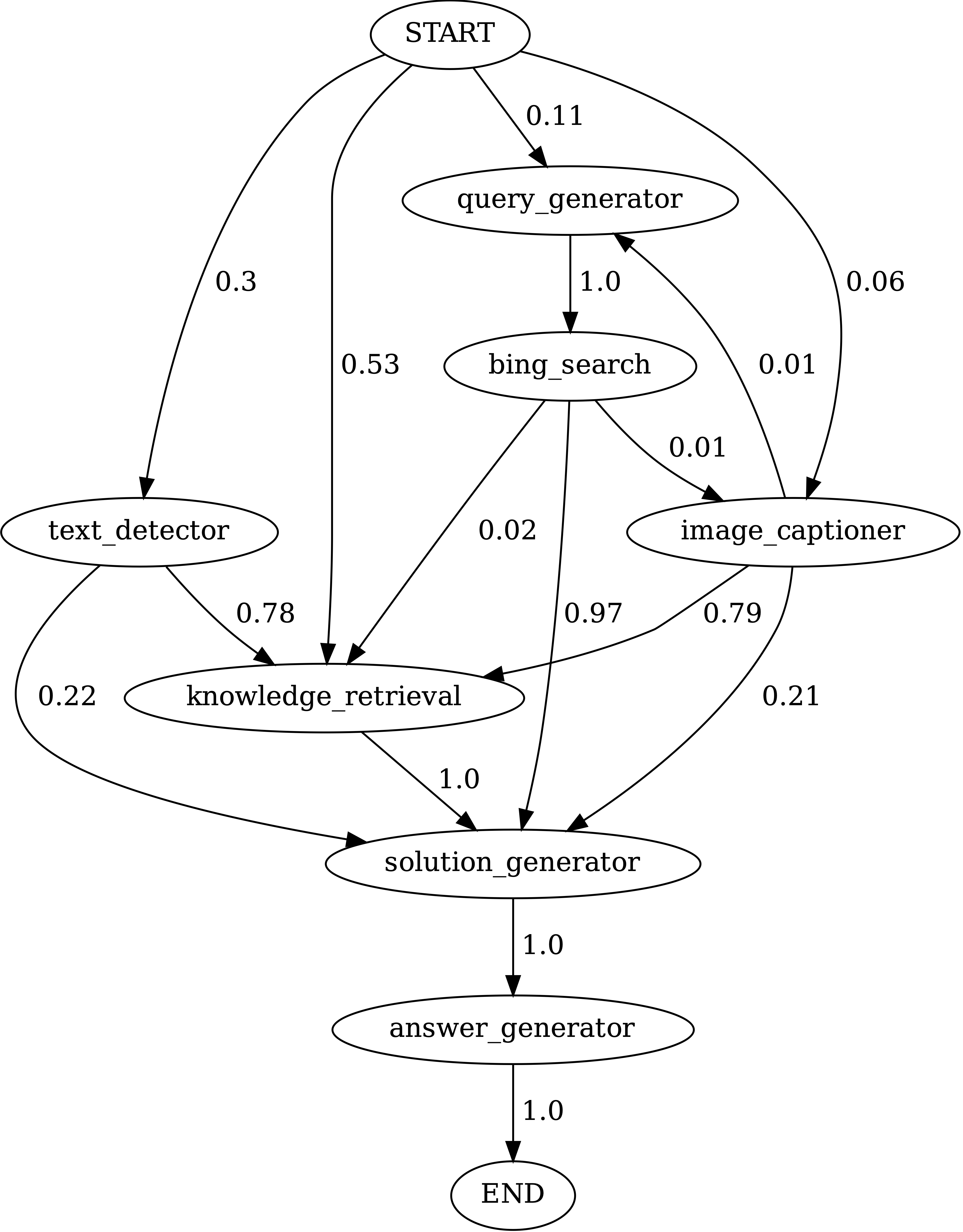
Chameleon 在 ScienceQA 数据集上各工具模块之间的状态转移图,如下所示:
Chameleon 在 TabMWP 数据集上各工具模块之间的状态转移图,如下所示:
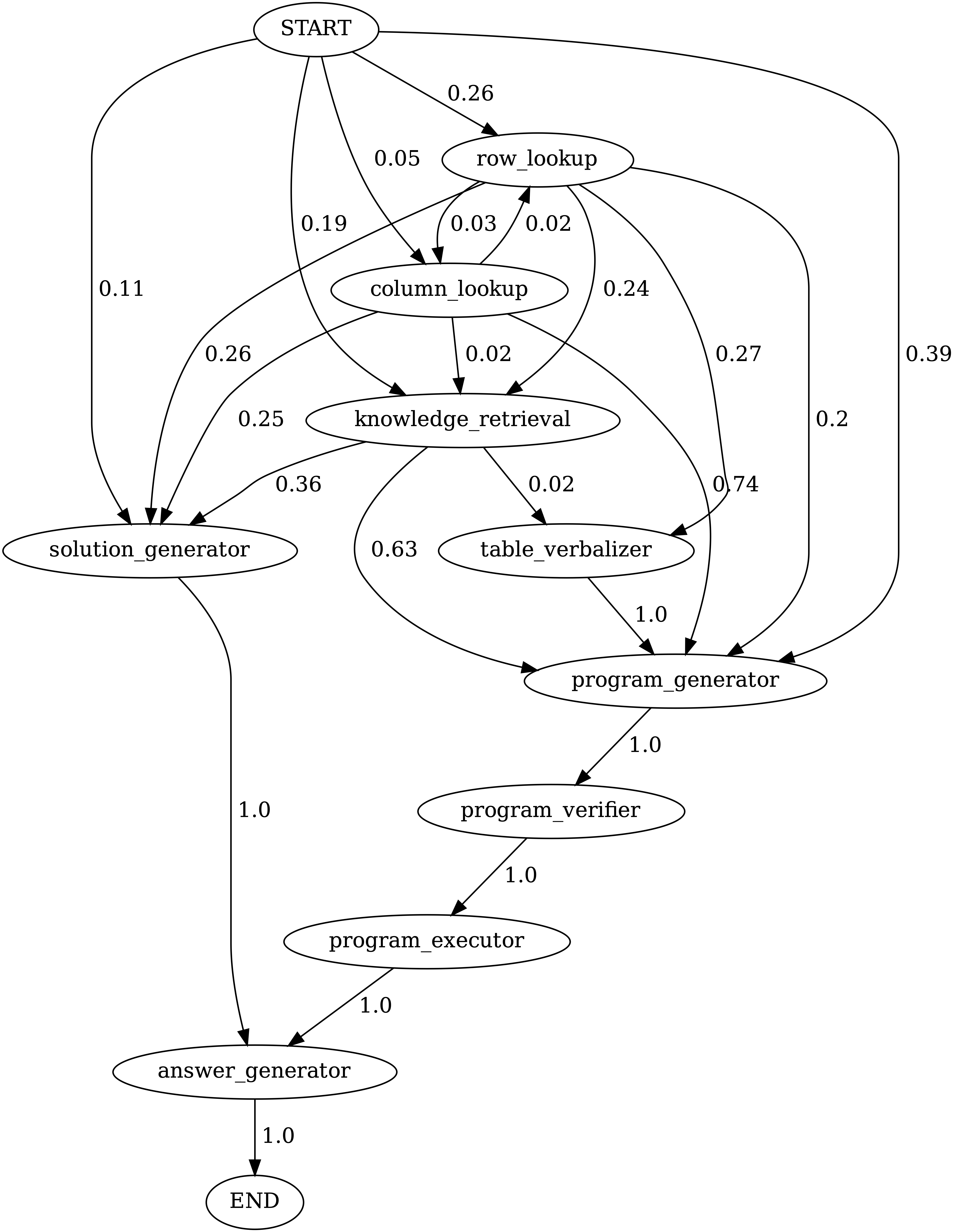
其中,START 是开始符号,END 是终结符号,其他都是非终结符号。
从上面的状态转移图,可以看出:
The GPT-4 planner is capable of making good decisions on how to sequence tools in a few-shot setup.
For ScienceQA, GPT-4 often relies on either the knowledge retriever or Bing search, but rarely both.
- 通常依赖知识检索器或 Bing 搜索,但很少同时依赖两者
On TabMWP, there are two main modes observed: either going through the solution-executor module or via the program verifier and executor.
- 两种主要模式:1)通过解决方案执行器模块;2)通过程序验证器和执行器
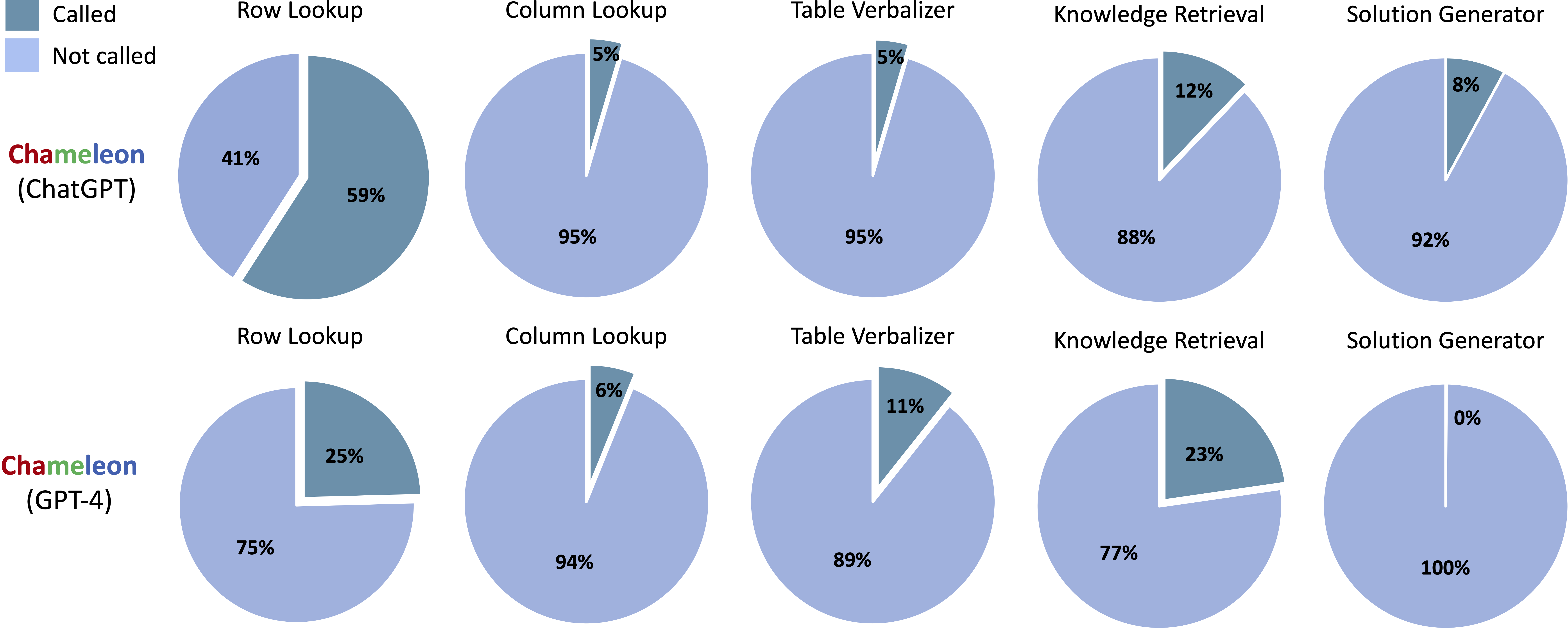
Chameleon 在 ScienceQA 数据集所使用到的工具的占比情况,如下图所示:

Chameleon 在 TabMWP 数据集所使用到的工具的占比情况,如下图所示:
另外,Chameleon 项目主页 提供了一些在线的示例,感兴趣的可以自行去玩一下。
2、Progressive-Hint Prompting Improves Reasoning in Large Language Models
用 渐进提示 提高大语言模型推理能力
《Progressive-Hint Prompting Improves Reasoning in Large Language Models》
URL:https://arxiv.org/abs/2304.09797
Official Code:https://github.com/chuanyang-Zheng/Progressive-Hint
单位:香港中文大学、华为诺亚方舟实验室
类型:技术报告(Tech Report)
动机:旨在提高 LLM 在推理任务中的性能,通过 设计更加有效的提示方法 来指导模型的推理过程。
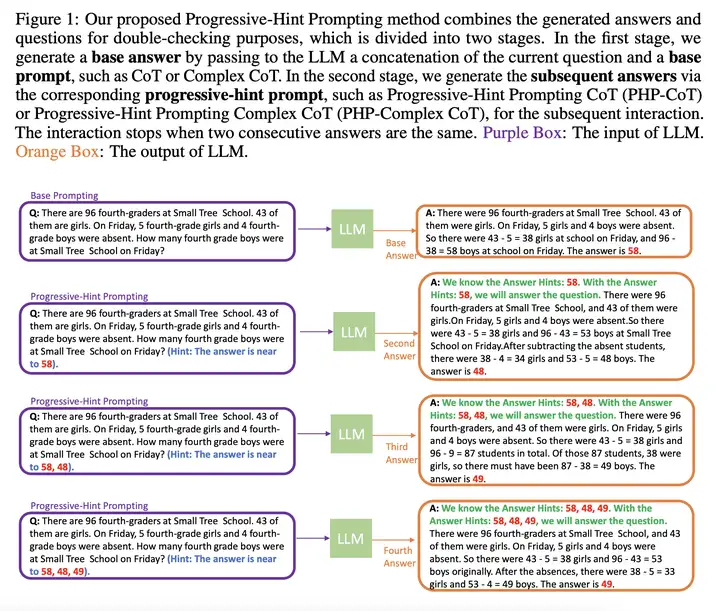
方法:提出一种新的提示方法 Progressive-Hint Prompting(PHP,渐进提示),通过利用 LLM 生成的答案作为提示来逐步引导用户获取正确答案,从而 提高 LLM 在推理任务中的性能。
优势:实验结果表明,PHP 可以显著提高 LLM 在 数学推理任务 中的准确性,并在多个推理基准测试中取得了新的最优结果。同时,PHP 可以与现有的 CoT 和自洽性方法结合使用,进一步提高性能。
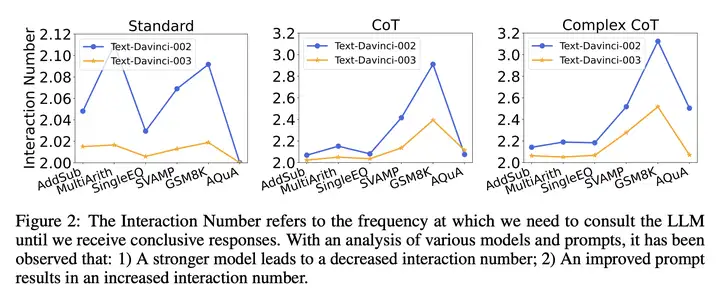
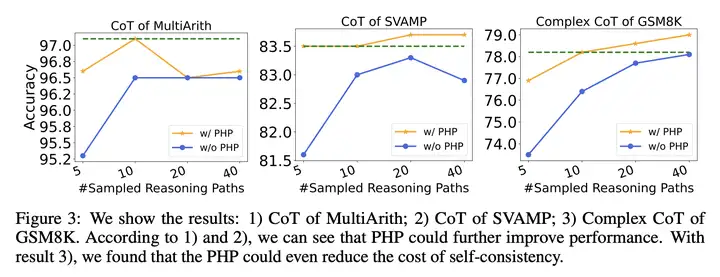
实验结果
更多
1、Evaluating Verifiability in Generative Search Engines
生成式搜索引擎 的可验证性评估
《Evaluating Verifiability in Generative Search Engines》
URL:https://arxiv.org/abs/2304.09848
Official Code:https://github.com/nelson-liu/evaluating-verifiability-in-generative-search-engines
单位:斯坦福大学
动机:
生成式搜索引擎直接生成用户查询的响应,以及内联引用。可信赖的生成式搜索引擎的先决条件是可验证性,即系统应全面引用(高引用召回率;所有语句都得到充分支持)并准确(高引用精度;每个引用都支持其相关语句)。
本研究旨在审计四个受欢迎的生成式搜索引擎的真实性,以及从不同来源(例如历史 Google 用户查询,Reddit 上动态收集的开放性问题等)的查询集合中进行多样化的查询。
方法:定义了引用召回率和引用精度的评价指标,并使用人工审核来审查四个流行的生成式搜索引擎的可验证性;发布了人工审核标注,以便进一步开发可信赖的生成式搜索引擎。
优势:发布了人工审核注释,为进一步开发可信赖的生成式搜索引擎提供了数据支持;定义了引用召回率和引用精度的评价指标,以鼓励开发全面和正确引用的系统。

2、Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent
《Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent》
URL:https://arxiv.org/abs/2304.09542
Official Code:http://www.github.com/sunnweiwei/RankGPT
单位:山东大学、百度
动机:旨在研究LLM在信息检索中的相关性排名任务中的应用,以及提出一种新的精细模型的蒸馏方法。
方法:主要使用了大型语言模型 ChatGPT 和 GPT-4,提出了一种新的排列生成方法来探索 LLM 的能力。还提出了一种基于 ChatGPT 的排名能力的精细模型的蒸馏方法。
优势:实验结果表明,使用 ChatGPT和 GPT-4 进行相关性排名的效果比监督方法好,具有很好的性能表现。所提出的精细模型的蒸馏方法也取得了良好的效果。

3、To Compress or Not to Compress – Self-Supervised Learning and Information Theory: A Review
自监督学习与信息论综述
《To Compress or Not to Compress – Self-Supervised Learning and Information Theory: A Review》
URL:https://arxiv.org/abs/2304.09355
单位:纽约大学
动机:深度神经网络在监督学习任务中取得了显著的性能,但需要大量标记数据。自监督学习 提供了一种另类范式,使模型能够在没有显式标签的情况下从数据中学习。信息论对于理解和优化深度神经网络至关重要。
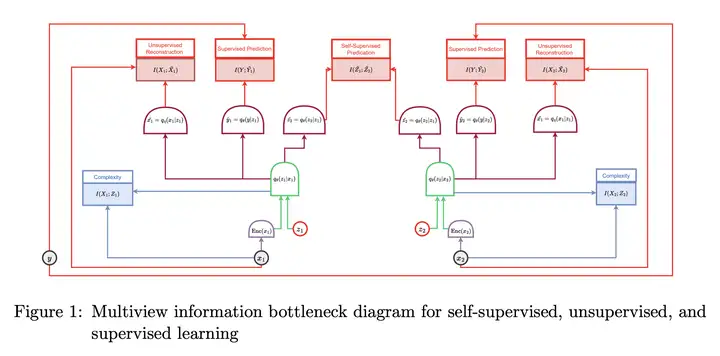
方法:从信息论的角度 探讨自监督学习中的最优表示概念,回顾了各种方法,并提出了一个统一框架,探讨了信息论量的实证测量和估算方法。
优势:信息论提供了一个灵活的方法,适用于各种学习模型,并有助于理解数据和模型优化的隐含和显式假设。本文综述了信息论、自监督学习和深度神经网络之间的交叉点,为研究提供了机会和挑战。
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-04-21-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)