2023-04-20:论文速递
1、Hyperbolic Image-Text Representations
双曲图像-文本表示
《Hyperbolic Image-Text Representations》
URL:https://arxiv.org/abs/2304.09172
Official Code:未开源
单位:Meta AI
类型:技术报告(Technical report)
动机:目前的大规模视觉和语言模型没有明确地捕捉图像和文本的层次结构,即文本概念 “狗” 包含所有包含狗的图像。
方法:提出一种名为 MERU 的 对比模型,使用 超几何表示法 来嵌入树状数据,更好地捕捉多模态数据中的视觉-语义层次结构。
优势:MERU 学习到 高度可解释 和 结构化 的表示空间,且在图像分类和图像-文本检索等标准多模态任务中表现出与 CLIP 相当的性能。
一句话总结:
提出了一种名为 MERU 的模型,使用超几何空间来构建图像和文本的层次关系,从而更好地捕捉多模态数据中的视觉-语义层次结构。
CLIP 是将图像和文本嵌入到一个欧几里得空间(Euclidean Space)中,而 MERU 则将图像和文本嵌入到一个双曲空间(Hyperbolic Space)中,如下图所示:

hypersphere(超球体)
Lorentzian hyperboloid(洛伦兹双曲面)
exponential map(指数图)
Lorentzian distance(洛伦兹距离)
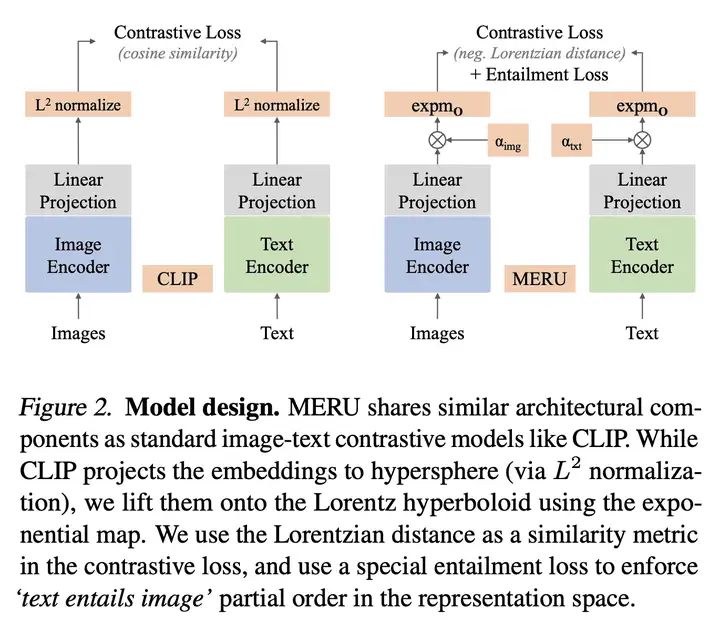
除了对比损失之外,我们还采用了 蕴含损失 来加强成对文本和图像之间的 偏序关系。Entailment(蕴含)损失如下图所示:
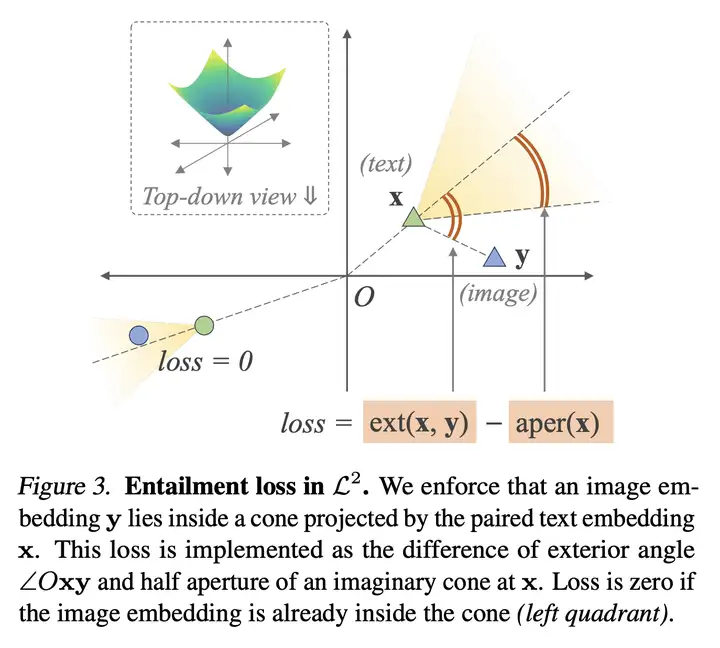
当图像 Embedding \(y\) 位于文本 Embedding \(x\) 的圆锥范围内,此时的 Entailment Loss 为 \(0\)。
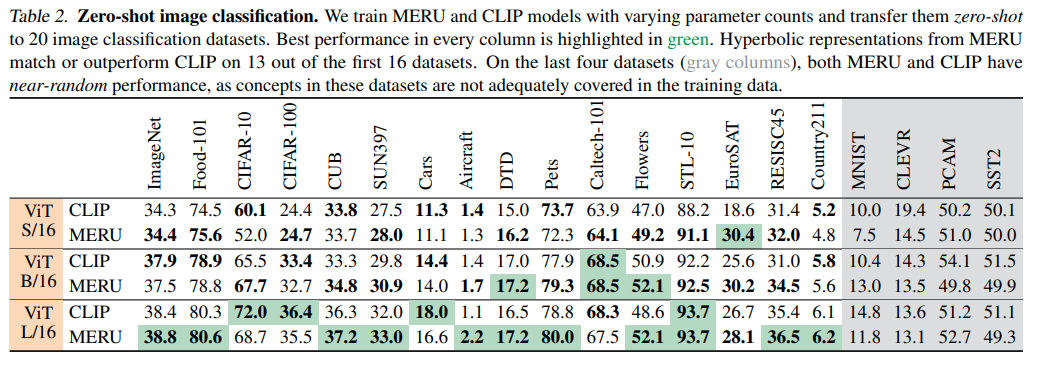
Zero-shot image classification 的实验结果如下图所示:
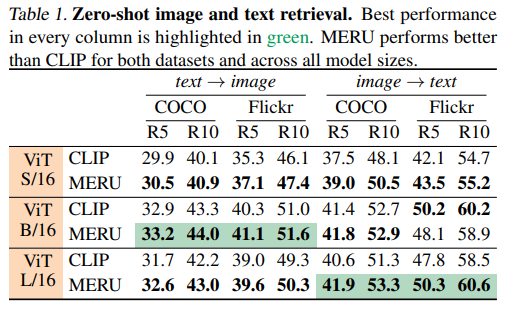
Zero-shot image-text retrieval 的实验结果如下图所示:
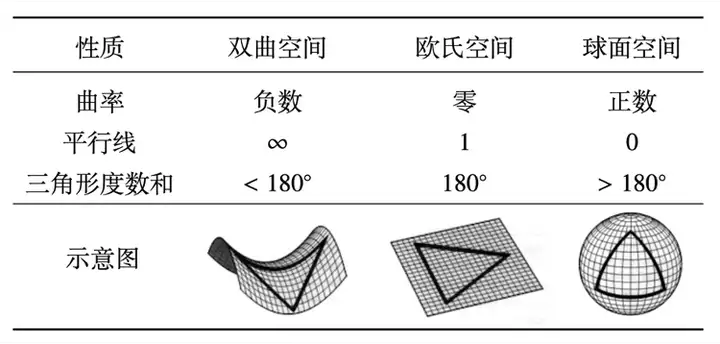
常曲率空间 指空间中各点截面曲率相等,即空间各处 “弯曲” 程度相同。根据曲率数值正负划分为 双曲空间、欧氏空间及球面空间 三种,各空间几何性质如下图所示:
2、Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
视频版 Stable Diffusion
《Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models》
URL:https://arxiv.org/abs/2304.08818
Official Code:未开源
项目主页:https://research.nvidia.com/labs/toronto-ai/VideoLDM/
会议:CVPR 2023
单位:NVIDIA、LMU Munich

动机:要实现高分辨率视频合成是一项资源密集型任务,该论文提出了一种基于 Video Latent Diffusion Models(Video LDMs,潜在扩散模型) 的合成方法,可以在避免过多计算需求的同时实现高质量图像合成和时间连贯的驾驶场景视频生成。
方法:首先在图像上预训练 “潜在扩散模型”,通过将时间维度引入潜在空间扩散模型并在编码的图像序列上微调,将图像生成器变成视频生成器。同时,该方法还将扩散模型升采样器进行时间对齐,将其转换为时间连贯的视频超分辨率模型。
优势:该方法在两个实际应用场景中取得了优秀的性能表现,并且可以将公开的、先进的文本到图像 LDM Stable Diffusion 转化为具有高分辨率视频生成能力的文本到视频 LDM。
一句话总结:
提出一种基于 “潜扩散模型” 的高分辨率视频合成方法,通过在压缩的低维潜空间训练扩散模型,实现高质量图像合成并避免过多的计算需求,可用于生成高分辨率且时间连贯的驾驶场景视频,并能够将文本转化为视频进行创意内容创作。
研究者高效训练视频生成模型的关键思路在于:重用预训练的固定图像生成模型,并利用了由参数 \(θ\) 参数化的 LDM。具体而言,他们实现了两个不同的时间混合层,即 时间注意力和 基于 3D 卷积的残差块。研究者使用 正弦嵌入 为模型提供了 时间位置编码。具体流程如下图所示。

其他
SAM-Adapter
《SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, and More》
URL:https://arxiv.org/abs/2304.09148
Official Code:https://github.com/tianrun-chen/SAM-Adapter-PyTorch
主页:https://tianrun-chen.github.io/SAM-Adaptor/
单位:魔芯科技、浙江大学、湖州大学

与其他基础模型一样,我们的实验结果表明,SAM 可能在某些分割任务中失败或表现不佳,例如阴影检测(shadow detection)和伪装对象检测 / 隐藏对象检测(camouflaged object detection / concealed object detection)。
提出了一种 SAM-Adapter 的 PEFT 方法,通过使用简单而有效的适配器将特定域的信息(domain-specific information)或视觉提示(visual prompts)引入(添加)到分割模型中,而不需要微调 SAM 模型。
实验表明,SAM-Adapter 能够显著提高 SAM 在具有挑战的任务(前面提到的两个任务)上的性能,甚至超过针对特征任务的专用模型。
在该方法中,信息 是通过 视觉提示 传达给网络的,这已被证明了在用最少的额外可训练参数,能高效地将一个冻结的大基础模型适应到许多下游任务工作。
the task-specific knowledge \(F^i\) is learned and injected into the network via Adapters. 如下图所示:
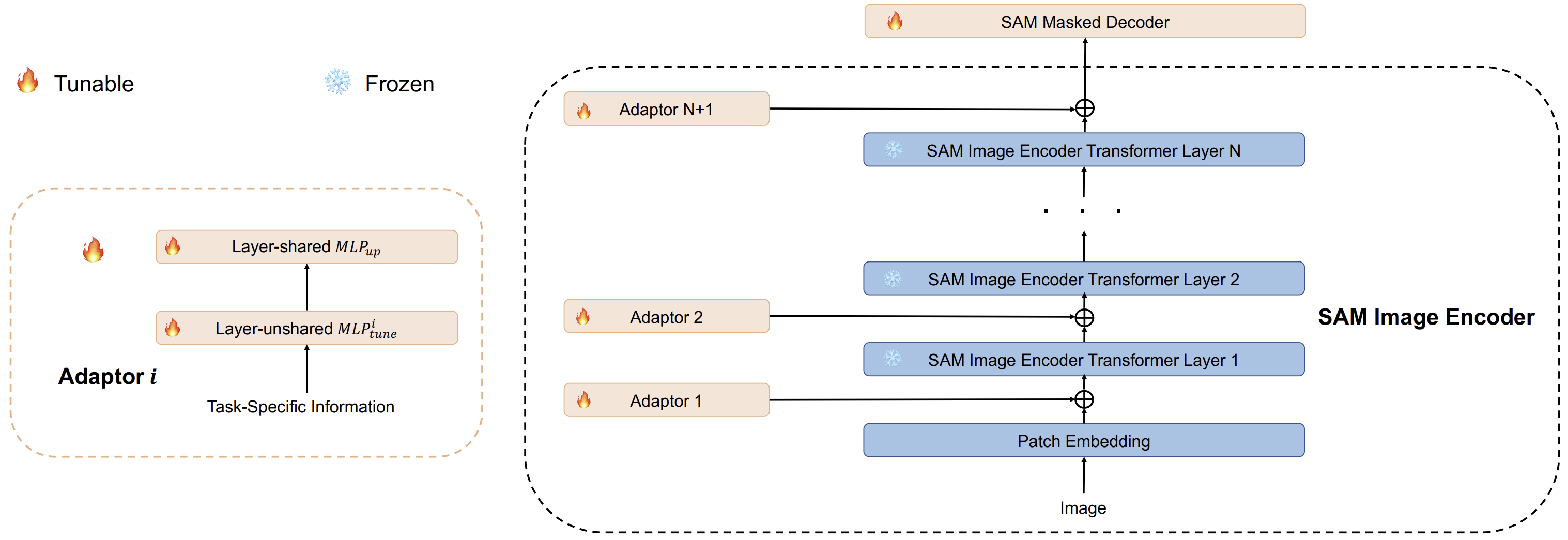
具体来说,the adapter takes the information \(F^i\) and obtains the prompt \(P^i\):
\[\begin{align} P^i = \text{MLP}_{up}^i(\text{GELU}(\text{MLP}_{tune}^i(F^i))) \end{align}\]其中,
\(\text{MLP}_{tune}^i\) 表示线性层,用于为 每一个 Adapter 生成特定任务的提示
\(\text{MLP}_{up}^i\) 是一个在所有 Adapter 之间 共享 的向上投影层,用于调整成 transformer 所需特征的维度
\(P^i\) 表示附加到 SAM 模型的每个 transformer 层的输出提示
\(\text{GELU}\) 是激活函数
信息 \(F^i\) 可以有多种形式的选择
SAM-Adapter 在伪装物体检测上的可视化结果,如下图所示:

SAM-Adapter 在阴影检测上的可视化结果,如下图所示:

除了 SAM-Adapter 方法,后续可能还有出现其他 SAM + PEFT 的变体,但也不排除 SAM-Adapter 的作者也进行了尝试(但可能效果不好)。
再扩展一点,未来将会出现大量 Foundation Model + PEFT + Prompt 范式的工作。
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-04-20-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)