2023-04-19:论文速递
1、Visual Instruction Tuning
视觉指令微调
《Visual Instruction Tuning》
URL:https://arxiv.org/abs/2304.08485
项目地址:https://llava-vl.github.io/
Official Code:https://github.com/haotian-liu/LLaVA
Dataset:https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
Model:https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0
Demo:https://llava.hliu.cc/
单位:微软

用语言生成数据对 多模态语言图像指令 进行微调,提出一种名为 LLaVA(Large Language and Vision Assistant)的大型多模态模型,连接视觉编码器和大型语言模型,用于通用的视觉和语言理解。
动机:将指令微调方法应用于多模态领域。为此,我们提出了使用语言生成数据来生成多模态语言图像指令,并开发了一种名为 LLaVA 的大型多模态模型。
方法:提出使用 GPT-4 生成多模态语言图像指令,用这些指令来微调一个名为 LLaVA 的大型多模态模型,该模型连接一个视觉编码器和大型语言模型,以实现通用的视觉和语言理解。提出了一个数据重组的视角和流程,将图像-文本对转换为适当的指令格式。
优势:所提出的 LLaVA 模型具有很多优势,其中最重要的是其在多模态问答方面取得了最先进的性能。

摘要
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks in the language domain, but the idea is less explored in the multimodal field.
- 使用机器生成的指令跟踪数据对大型语言模型 (LLM) 进行指令调优提高了语言领域新任务的零样本能力,但在多模态领域探索较少。
Multimodal Instruct Data. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
我们首次尝试使用纯语言 GPT-4 生成多模态语言图像指令跟踪数据。
LLaVA Model. We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
我们介绍了 LLaVA(大型语言和视觉助手),一种端到端训练有素的大型多模式模型,连接视觉编码器和 LLM 以实现通用视觉和语言理解。
Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
- 我们的早期实验表明,LLaVA 展示了令人印象深刻的多模型聊天能力,有时在未见过的图像/指令上表现出多模态 GPT-4 的行为,并且在合成多模态指令跟随数据集上与 GPT-4 相比产生了 85.1% 的相对分数。当在 Science QA 上进行微调时,LLaVA 和 GPT-4 的协同作用达到了 92.53% 的新的最先进的准确率。
Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
- 我们公开了 GPT-4 生成的视觉指令调整数据、我们的模型和代码库。
LLaVA
LLaVa 使用简单的投影矩阵连接预训练的 CLIP ViT-L/14 视觉编码器和大型语言模型 LLaMA。我们考虑一个 两阶段的指令微调 过程:
Stage 1: Pre-training for Feature Alignment.(特征对齐)
- 基于 CC3M 的子集,仅更新投影矩阵 \(W\)
Stage 2: Fine-tuning End-to-End.(端到端微调)
针对下面两种场景,对投影矩阵 \(W\) 和 LLM \(f_{\phi}\) 都进行更新/微调
Visual Chat:LLaVA is fine-tuned on our generated multimodal instruction-following data for daily user-oriented applications.
Science QA:LLaVA is fine-tuned on this multimodal reasonsing dataset for the science domain.
如下图所示:

数据集
Multimodal Instrucion-Following Data
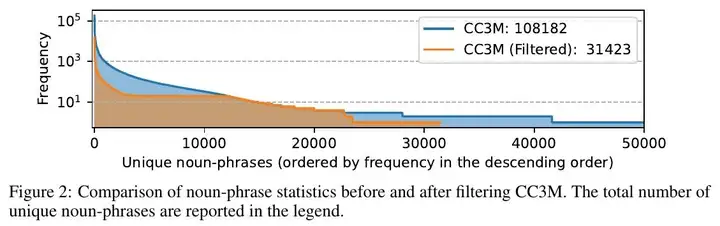
unique noun-phrases 独特的名词短语
ordered by frequency in the descending order 按频率降序排列
基于 COCO 数据集,我们与纯语言 GPT-4 进行交互,总共收集了 158K 个独特的语言-图像指令跟随样本,分别包括 58K 个对话(conversations)、23K 个详细描述(detailed description)和 77k 个复杂推理(complex reasoning)。
实验结果
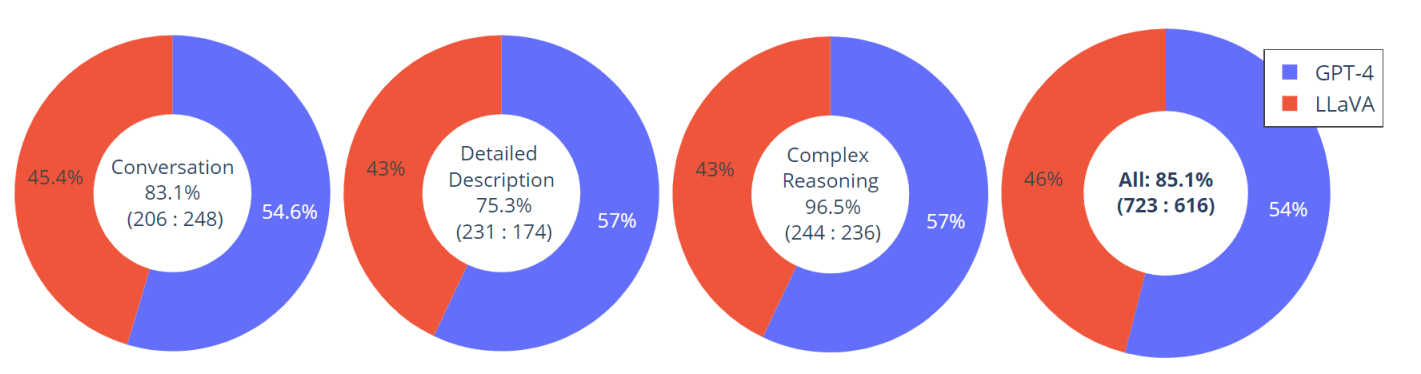
构建了一个包含 30 个未见过图像的评估数据集:每个图像都与三种类型的指令相关联:对话、详细描述和复杂推理。这导致了 90 条新的语言图像指令,我们在这些指令上测试了 LLaVA 和 GPT-4,并使用 GPT-4 从 1 到 10 对它们的响应进行评分。报告了每种类型的总分和相对分。总体而言,与 GPT-4 相比,LLaVA 达到了 85.1% 的相对分数,表明所提出的自我指导方法在多模式设置中的有效性。如下图所示:
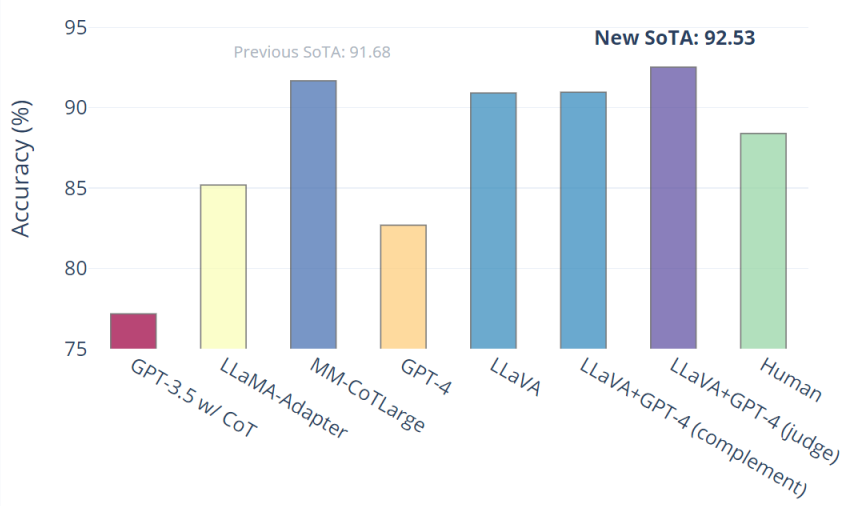
仅 LLaVA 就达到了 90.92%。我们使用纯文本 GPT-4 作为判断,根据它自己之前的答案和 LLaVA 答案来预测最终答案。这种“GPT-4 as juedge”方案产生了新的 SOTA 92.53%。
示例演示
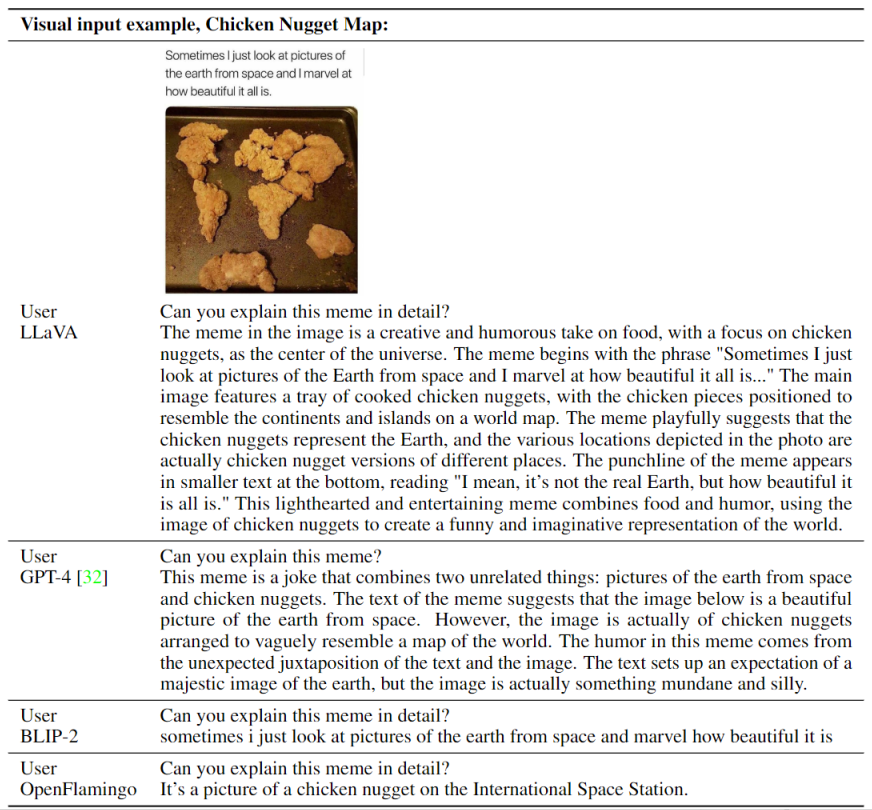
与 OpenAI GPT-4 技术报告 中两个示例的视觉推理(Visual Reasoning)进行对比,如下图所示:

Optical character recognition (OCR) 的几个例子,如下图所示:
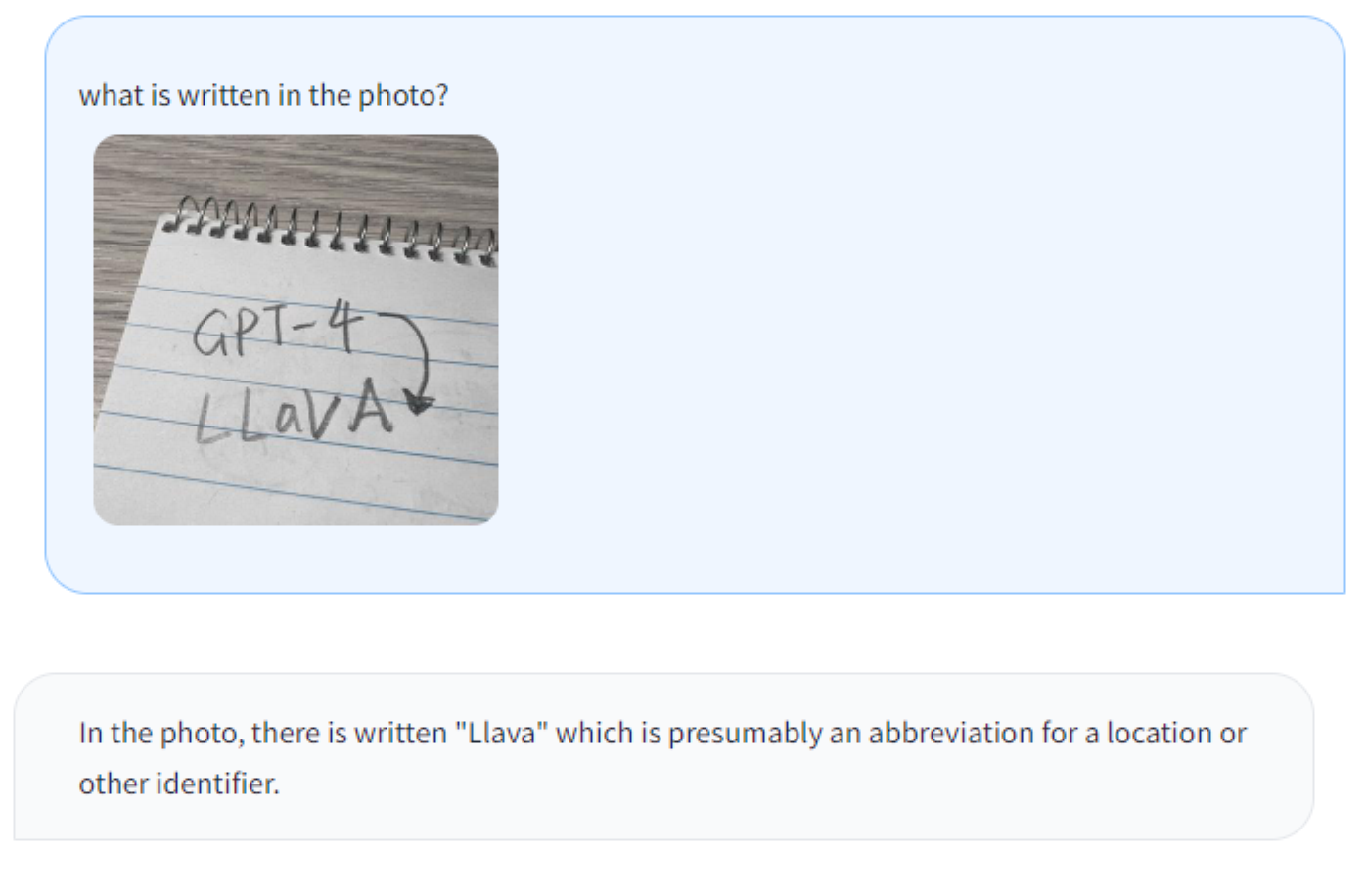
上述这个例子的不足之处是无法准确识别 “LLaVA”,而是识别成了 “Llava”,对 手写体的字母大小写 识别仍有待改进。
而下面这个例子,LLaVA 能够准确识别打印体的字母大小写,如下所示:
![]()
上述都是 LLaVA 项目主页 的一些示例,接下来使用一张阅兵的图片来对 在线的 LLaVA Demo 进行测试,结果如下所示:
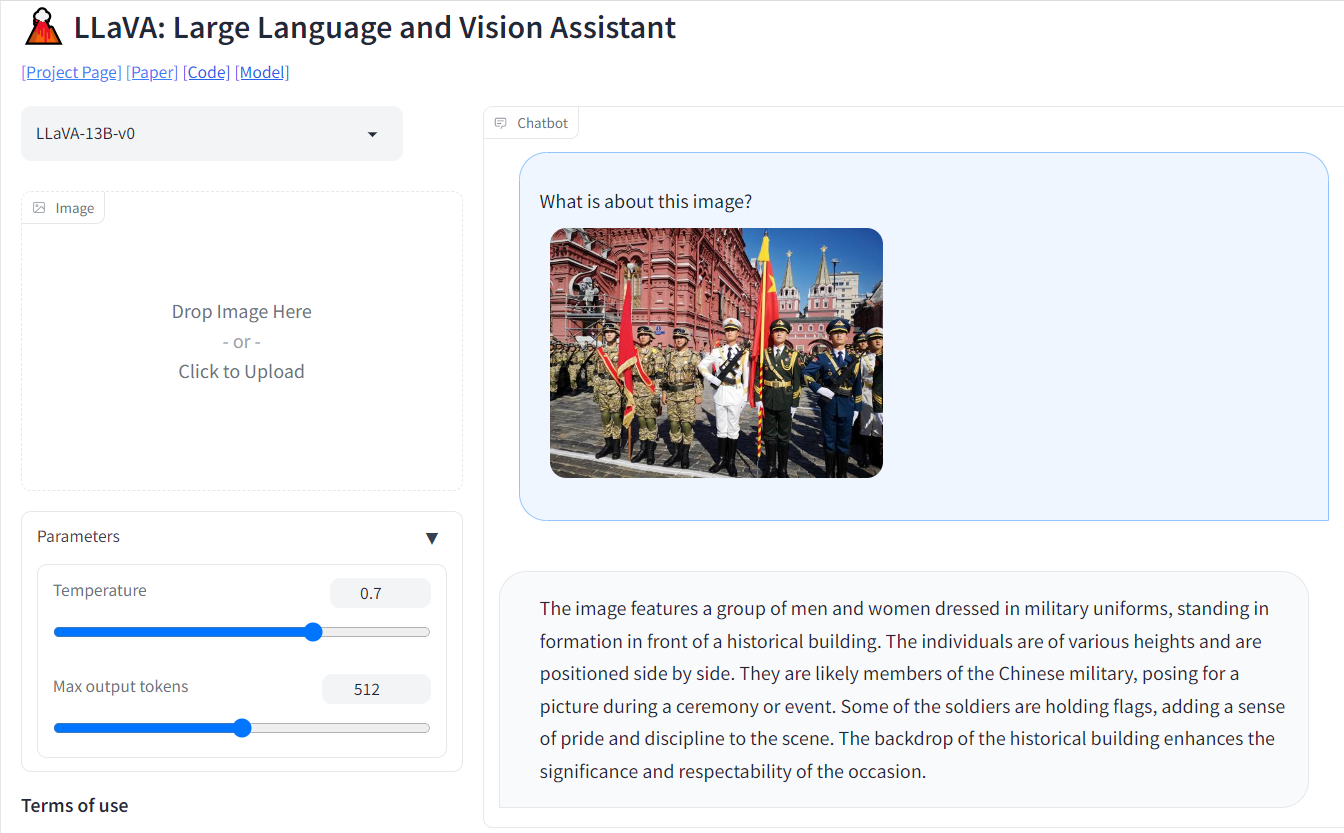
The image features a group of men and women dressed in military uniforms, standing in formation in front of a historical building. The individuals are of various heights and are positioned side by side. They are likely members of the Chinese military, posing for a picture during a ceremony or event. Some of the soldiers are holding flags, adding a sense of pride and discipline to the scene. The backdrop of the historical building enhances the significance and respectability of the occasion.
照片中,一群身穿军装的男女列队站在一座历史建筑前。这些个体的高度各不相同,并且并排放置。他们很可能是中国军人,在仪式或活动中摆出姿势拍照。一些士兵举着旗帜,为现场增添了自豪感和纪律感。这座历史建筑的背景增强了这一场合的重要性和声望。
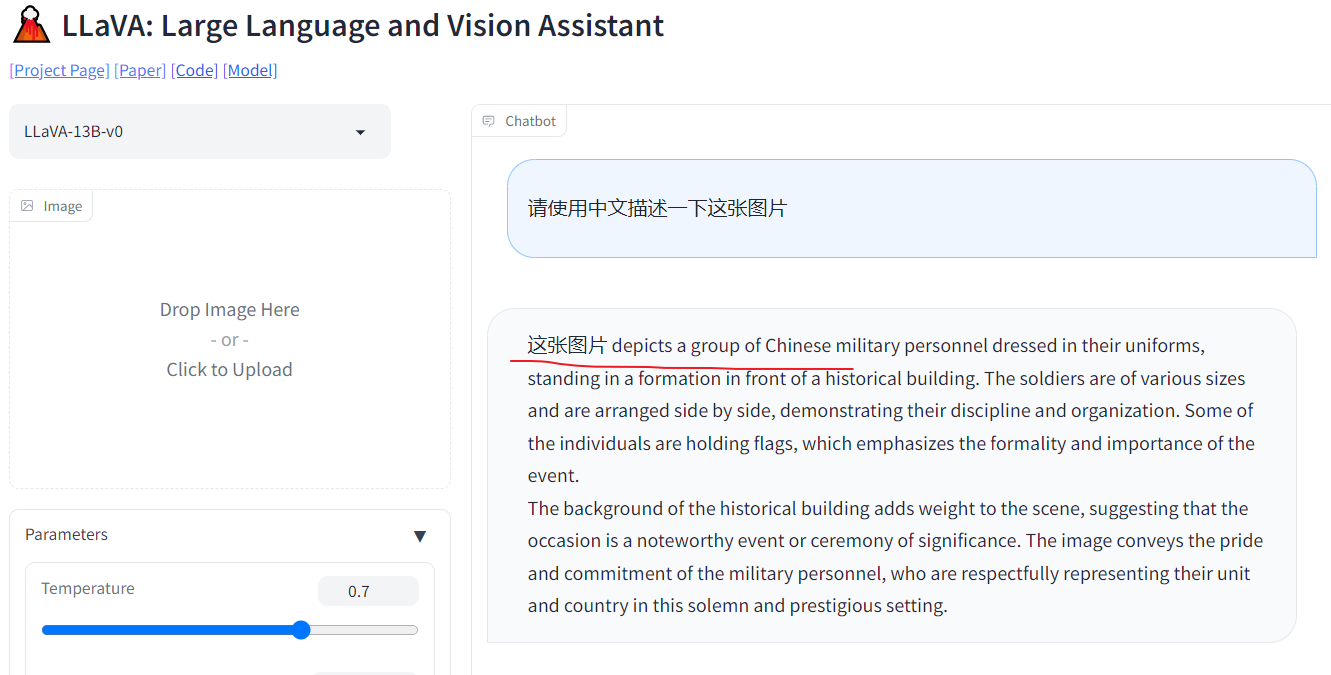
可以看到,目前 LLaVA 的聊天效果还是不错的,描述的内容也比较符合输入的图片。但是,对于中文的支持不是很友好,输出的结果是 “中英混乱” 的,如下所示:
2、Tool Learning with Foundation Models
综述:基于基础模型的工具学习
《Tool Learning with Foundation Models》
URL:https://arxiv.org/abs/2304.08354
Official Code:https://github.com/openbmb/bmtools
单位:清华大学、中国人民大学
摘要
动机:人类使用工具的能力非常强大,将这种能力应用到人工智能系统中可以提高系统的性能。本文的动机是系统地研究如何将基础模型与工具整合起来,以实现高效的工具学习。
方法:提出一种 通用的工具学习框架,介绍了如何训练模型以提高其使用工具的能力,并实验了 17 种典型工具 的使用。
优势:提出一种新的 工具学习方法,展示了基础模型在工具使用方面的巨大潜力,并提供了许多未来研究的方向和问题。
一句话总结:
讨论了如何让人工智能系统像人一样熟练地使用工具,提出一种使用基础模型的工具学习范式,通过整合专用工具和基础模型的优势,提高了问题解决的准确性、效率和自动化程度。
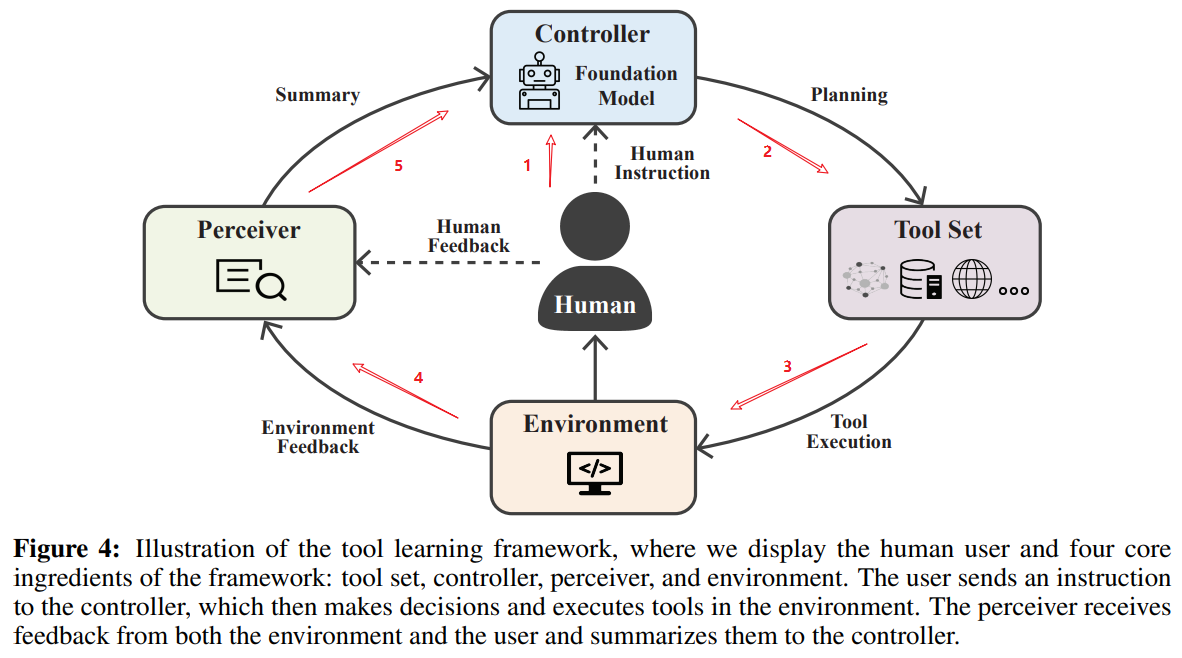
总体框架
工具学习的框架图如下所示。其中我们展示了人类用户和框架的四个核心组成部分:工具集、控制器、感知器和环境。用户向控制器发送指令,然后控制器做出决策并在环境中执行工具。感知器接收来自环境和用户的反馈,并将它们汇总给控制器。
You are now acting as an expert in the field of signal anomaly detection. From a professional point of view, do you think there is any need to modify the following content? Be careful not to modify the whole text, you need to point out the places that need to be modified one by one, and give revision opinions and recommended revision content. And then ensure these content are more precise, academic and formal grammar. And also enhance flow and coherence. Please provide multiple versions for reference. Since your output length is limited, in order to save space. Please use ellipses for the parts you don’t think need to be modified.
Overall, the following latex style content is:
你现在扮演一个 [这里放你所研究的领域] 领域的专家,从专业的角度,您认为上面这些内容是否有需要修改的地方? 注意,不要全文修改,您需要一一指出需要修改的地方,并且给出修改意见以及推荐的修改内容。
You are now acting as an expert in the field of anomaly signal detection in satellite networks. From a professional point of view, do you think there is any need to modify the following content? Be careful not to modify the whole text, you need to point out the places that need to be modified one by one, and give revision opinions and recommended revision content. And then ensure these content are more precise, academic and formal grammar. And also enhance flow and coherence. Please provide multiple versions for reference. Since your output length is limited, in order to save space. Please use ellipses for the parts you don’t think need to be modified.
Overall, the following latex style content (about the conclusion in our anomaly signal detection paper) is:
更多
###
参考
LLaVA:
项目主页:https://llava-vl.github.io/
Tool Learning 综述:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/wiki/2023-04-19-paper-list/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)