Cross-Attention
在多模态学习领域中,交叉注意力(Cross-Attention) 是一种常用的模态融合方式。
假设现在有 Video 和 Text 两种模态的数据,如果要将 Text 的数据融合到 Video 中,只需要将 Attention 中的 Query = Video,Key & Value = Text,然后进行计算即可:
# Post-Norm
q = video
k = v = text
# Cross-Attention
attented = cross-attention(
query = q,
key = k,
value = v
)
# LayerNorm and Residual Connection
result = layer_norm(attented + q)
需要注意的是:这里的 残差连接(residual connection)添加的是 Query 向量,而非 Key 或者 Value 向量。
图示
在论文 Attention Is All You Need 中给出了标准 Transformer 的结构示意图,如下所示:
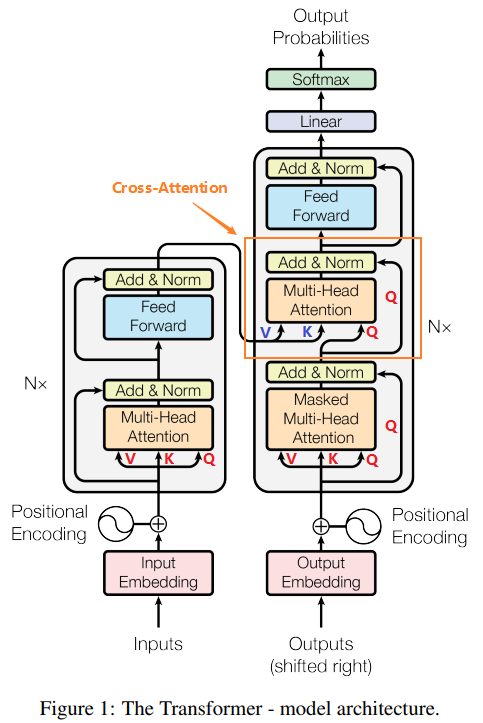
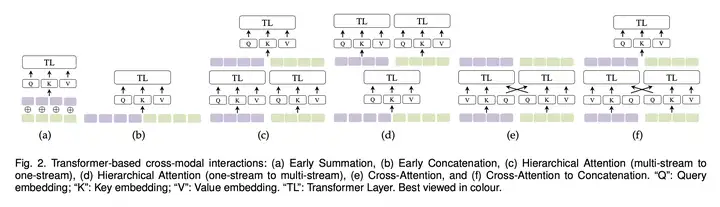
在论文 Multimodal Learning with Transformers: A Survey 中给出了几种不同的模态融合方式(其中就包括了 Cross-Attention),如下图所示:
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/fragment/2023-05-29-cross-attention/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)