记录在 PyTorch 中加载和保存模型的方法,包括
- CPU 模型与 GPU 模型的相互加载
citation test[1]
1、加载模型
2、保存模型
保存模型时,可以直接将整个模型(结构和参数)进行保存:
# 选择模型
model = CNN()
torch.save(model,'CNN_all.pth')
然后直接使用 torch.load 来加载模型:
model = torch.load('CNN_all.pth')
model.eval()
如果
3、冻结部分层
4、删除部分层
5、欠拟合和过拟合
参考:
我们将在学习曲线(Learning Curves)上寻找模型欠拟合(underfittiing)或者过拟合(overfitting)的证据,并查看几种防止过拟合或者欠拟合的策略。
我们可能认为训练数据中的信息有两种:信号(signal)和噪声(noise)。信号是概括的部分,即可以帮助我们的模型根据新数据进行预测的部分。噪声是仅适用于训练数据的那部分;噪声是来自现实世界中的数据的所有随机波动,或者是所有无法实际帮助模型做出预测的偶然的、非信息性的模式。噪音是部分可能看起来有用但实际上不是。
我们通过选择 最小化训练集损失 的权重或参数来训练模型。但是,要准确评估模型的性能,我们需要在一组新数据(验证数据)上对其进行评估。
当我们训练模型时,我们一直在逐个 epoch 绘制训练集时期的损失。为此,我们也将添加一条绘制验证数据损失的曲线。这些图我们称之为学习曲线。为了有效地训练深度学习模型,我们需要能够解释它们。
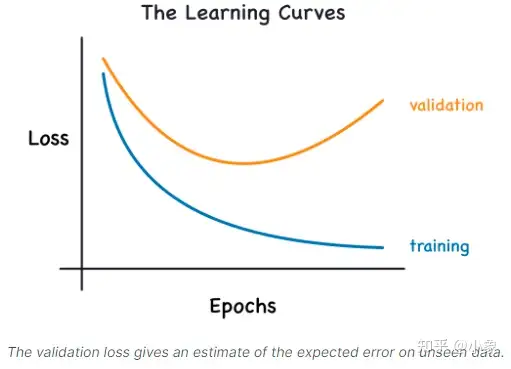
当模型学习信号或学习噪声时,训练损失就会下降
只有当模型学习到信号时,验证损失才会下降
由于模型从训练集中学到的任何噪声都不会推广到新数据,因此,当模型学习到信号时,两条曲线都会下降,但是当它学习到噪声时,曲线中就会产生间隙,训练损失与验证损失之间差距的大小会告诉你模型学习了多少噪声。
理想情况下,我们将创建学习所有信号而不学习噪声的模型。这实际上永远不会发生。事实上,我们会做出权衡。我们可以让模型以学习更多噪声为代价来学习更多信号。只要这种让步对我们有利,验证损失就会继续减少。然而,在某一点之后,这种让步可能对我们不利,成本超过收益,验证损失开始上升。如下图所示:
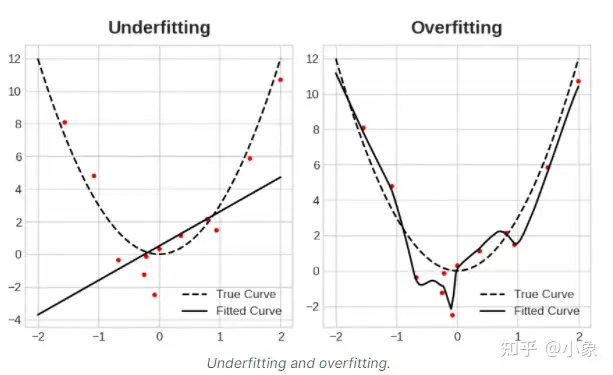
这种权衡表明在训练模型时可能会出现两个问题:信号不足或噪声过多
训练集 欠拟合(Underfitting)是指由于模型 没有学习到足够的信号 导致损失没有达到应有的水平(不收敛)
过拟合(Overfitting)是指由于模型 学习了太多噪声 造成损失没有达到应有的水平
训练深度学习模型的诀窍是在两者之间找到最佳平衡。
总之,
在构建机器学习算法时,我们会利用样本数据集来训练模型。
但是,当模型在样本数据上训练时间过长或模型过于复杂时,模型就会开始学习数据集中的 “噪声” 或不相关信息。
当模型记住噪声并且与训练集过于接近时,模型就会变得 “过拟合”,并且无法很好地泛化到新数据。
如果模型不能很好地泛化到新数据,那么它将无法执行其预期的分类或预测任务。
我们将研究从训练数据中获取更多信号同时减少噪声量的几种方法:
Capacity
Early Stopping
模型的 capacity 是指它能够学习的模式的大小和复杂性。对于神经网络,这在很大程度上取决于它有多少神经元以及它们如何连接在一起。
我们可以通过增加模型的宽度(向现有层增加更多单元)或增加模型的深度(添加更多层)来增加神经网络模型的 capacity。
越宽 的网络越容易学习到更多的 线性关系
越深 的网络更倾向于学习 非线性关系
哪个更好只取决于数据集。
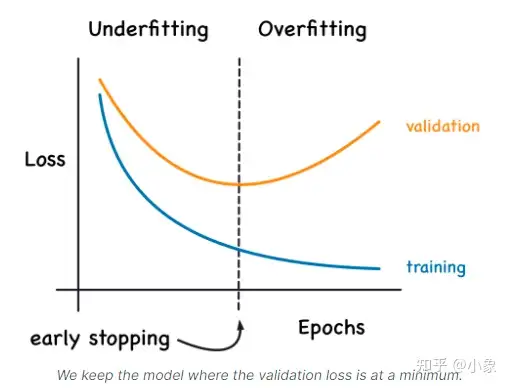
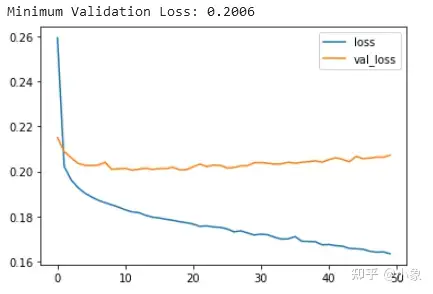
我们提到当模型过于急切地学习噪声时,在训练期间验证损失(validation loss)可能会开始增加。为了防止这种情况,我们可以在验证损失(validation loss)不再减少时停止训练。以这种方式中断训练称为 early stopping。如下图所示:
遇到下面这种情况,可以尝试 使用更大容量 的模型(这些曲线之间的差距非常小,验证损失永远不会增加,因此 网络欠拟合 而不是过拟合的可能性更大)
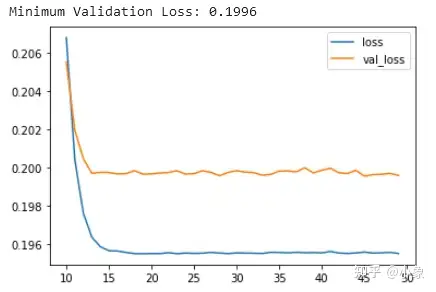
下面这种情况属于 过拟合。现在验证损失很早就开始上升,而训练损失继续下降。这表明网络已经开始过拟合。在这一点上,我们需要尝试一些方法来防止它,通过 减少单元数量 或通过 提前停止 等方法。
6、Dropout 的设置技巧
参考:
决定使用 dropout 之前,需要先判断模型是否过拟合
先
dropout rate = 0, 训练后得到模型的一些指标(比如: F1, Accuracy, AP)。比较 train 数据集和 test 数据集的指标。过拟合:尝试下面的步骤。
欠拟合:尝试调整模型的结构,暂时忽略下面步骤。
dropout 设置成 0.4-0.6 之间, 再次训练得到模型的一些指标。
如果过拟合明显好转,但指标也下降明显,可以尝试减少 dropout(0.2)
如果过拟合还是严重,增加 dropout(0.2)
重复上面的步骤多次,就可以找到理想的 dropout 值了。
一般情况,dropout rate 设为 0.3-0.5 即可。
dropout rate 过大 容易导致 欠拟合:
- 容易把有用的特征信息给丢弃掉
7、
根据智源研究院官网介绍,2018 年 11 月成立的智源研究院,是一家系统型创新驱动的研究院,致力于搭建一个高效有活力的 AI 研发平台。
2021 年 6 月,智源研究院发布 “悟道2.0”——中国首个 + 世界最大超大规模预训练模型,达到了 1.75 万亿参数;是当时的 GPT 3 采用的 1750 亿参数量的 10 倍,亦超过了谷歌发布的 Switch Transformer(1.6 万亿参数量)。
[[3.75, 11.43], [11.7, 17.86], [0.31, 7.85], [5, 15.16], [0, 4.68]]
tensor([[0.0271, 0.0184],
[0.0270, 0.0184],
[0.0270, 0.0183],
[0.0270, 0.0183],
[0.0270, 0.0183]], device='cuda:0')
[118.46, 213.44]
tensor([[0.0268, 0.0270]], device='cuda:0')
Traceback (most recent call last):
File "/root/code/Prompt-TVG/train_prompt.py", line 260, in <module>
test_losses = loss_fn(model_outputs, data)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/root/code/Prompt-TVG/loss/total_loss.py", line 54, in forward
gt_start_pos = torch.index_select(gt_start_pos, 0, torch.nonzero(vtm_labels).squeeze(-1))
Multi-modal fusion
- 通过 circular matrices(循环矩阵)
- 通过 cross-attention 和 convolution 操作
- 使用从语言特征生成的动态过滤器(dynamic filters),以便根据查询内容调制(通过卷积)视觉信息
- Hadamard 积:融合多模型信息的主流方式
VLG-Net 通过图卷积来融合多模态信息(在图匹配层)
VLG-Net:
We use 1D convolutions to project the input visual features to a fixed dimension (512), and the GCNeXt blocks’ hyper-parameters are set as in [72].
对于 ActivityNet Captions、TACoS 和 DiDeMo 数据集,均使用 512 维的视频特征
参考
引用列表:
- 张三. 测试论文 [J]. 北京:清华大学出版社,2000: 10-18。
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/fragment/2023-04-25-pytorch-load_model/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)