数据集
FineWeb 数据集
https://huggingface.co/datasets/HuggingFaceFW/fineweb
![]()
How to download and use 🍷 FineWeb You can load the full dataset or a specific crawl/dump (see table below). Dumps have the format CC-MAIN-(year)-(week number).
(Smaller) sample versions Along with config default (all the data), and the configs for each individual dump, you can also download the following configs:
sample-350BT: a subset randomly sampled from the whole dataset of around 350B gpt2 tokens (388GB)sample-100BT: a subset randomly sampled from the whole dataset of around 100B gpt2 tokens (277.4GB)sample-10BT: a subset randomly sampled from the whole dataset of around 10B gpt2 tokens (27.6GB)
sample-10B was sampled from sample-100B which in turn was sampled from sample-350BT.
FineWeb-EDU 数据集
数据集预处理
下载 FineWeb-EDU 数据集,并将每一个 token ids 存储成 100 个 npy 文件,以便后续训练和验证阶段加载使用。
$ HF_ENDPOINT=https://hf-mirror.com python fineweb.py
输出结果:
Resolving data files: 100%|██████████████████████████████████████████| 1571/1571 [00:05<00:00, 301.63it/s]
Downloading data: 100%|████████████████████████████████████████████████| 541M/541M [03:12<00:00, 2.80MB/s]
Downloading data: 100%|██████████████████████████████████████████████| 2.15G/2.15G [04:25<00:00, 8.10MB/s]
Downloading data: 100%|██████████████████████████████████████████████| 2.15G/2.15G [19:52<00:00, 1.80MB/s]
Generating train split: 9672101 examples [02:00, 80527.00 examples/s] | 461M/2.15G [04:24<20:11, 1.39MB/s]
Loading dataset shards: 100%|██████████████████████████████████████████| 100/100 [00:00<00:00, 647.87it/s]
Shard 0: 100%|█████████████████████████████████████| 100000000/100000000 [00:12<00:00, 7945080.25tokens/s]
Shard 1: 100%|█████████████████████████████████████▉| 99997871/100000000 [00:12<00:00, 7973708.84tokens/s]
Shard 2: 100%|█████████████████████████████████████▉| 99999982/100000000 [00:13<00:00, 7689462.98tokens/s]
Shard 98: 100%|████████████████████████████████████▉| 99999499/100000000 [00:13<00:00, 7628157.79tokens/s]
Shard 99: 54%|███████████████████▉ | 53989101/100000000 [00:08<00:07, 6468649.01tokens/s]
训练:使用 FineWeb-EDU 数据集
$ torchrun --standalone --nproc_per_node=2 train_gpt2.py
$ OMP_NUM_THREADS=8 nohup torchrun --standalone --nproc_per_node=2 train_gpt2.py > train_gpt2_64_1024_node2.log 2>&1 &
一些错误
由于在 Nvidia V100S 上运行,导致原先的代码会有一定的问题。因此,特意进行记录。
注意:在 Google Colab 上的 T4 GPU 运行时,原先的代码不存在问题。
numpy uint16 to torch long
直接将 uint16 的 numpy 数据转为 PyTorch Long:
ptt = torch.tensor(npt, dtype=torch.long)
报错:
TypeError: can't convert np.ndarray of type numpy.uint16. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
Fused AdamW
由于服务器最开始的 torch 版本较老,不支持 fused 参数。因此在使用 Fused AdamW 时出现报错:
torch 1.13.1
torchelastic 0.2.2
torchtext 0.14.1
torchvision 0.14.1
TypeError: AdamW.__init__() got an unexpected keyword argument 'fused'
optimizer = raw_model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device=device)
File "/root/code/build-nanogpt/train_gpt2.py", line 204, in configure_optimizers
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=(0.9, 0.95), eps=1e-8, fused=use_fused)
使用 pip install --upgrade torch 升级到最新的 PyTorch(2.3.1):
torch 2.3.1
torchelastic 0.2.2
torchtext 0.14.1
torchvision 0.14.1
with torch.autocast()
Bfloat16 on nvidia V100 gpu(不支持)
[rank0]: File "/root/code/build-nanogpt/train_gpt2.py", line 393, in <module>
[rank0]: with torch.autocast(device_type=device, dtype=torch.bfloat16):
[rank0]: File "/opt/conda/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 241, in __init__
[rank0]: raise RuntimeError(
[rank0]: RuntimeError: User specified an unsupported autocast device_type 'cuda:0'
解决:with torch.autocast(device_type=device, dtype=torch.float16):
因此,取消使用自动混合精度进行训练。
PyTorch 自动混合精度文档:https://pytorch.org/docs/stable/notes/amp_examples.html#autocast-and-custom-autograd-functions
OMP_NUM_THREADS
$ Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
$ OMP_NUM_THREADS=8 nohup torchrun --standalone --nproc_per_node=2 train_gpt2.py > train_gpt2_64_1024_node2.log 2>&1 &
思考
损失函数
将 Next Token Prediction 视为一个 多分类(vocab_size)问题,模型输出的 logits 就是 vocabulary 中每个词可能的概率,而 target 就是正确分类对应的 vocabulary 下标。
使用 Cross Entropy 损失函数:
\[loss = -\sum_i\text{logits}_i\log \text{target}\]当模型的结果越来越好时,logits 越会接近于 ont-hot。
targets = x[1:] # (B, T)
logits = self.lm_head(x) # (B, T, vocab_size)
loss = None
if targets is not None:
# logits: (B*T, vocab_size)
# target: (B*T) -> (B*T, 1)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
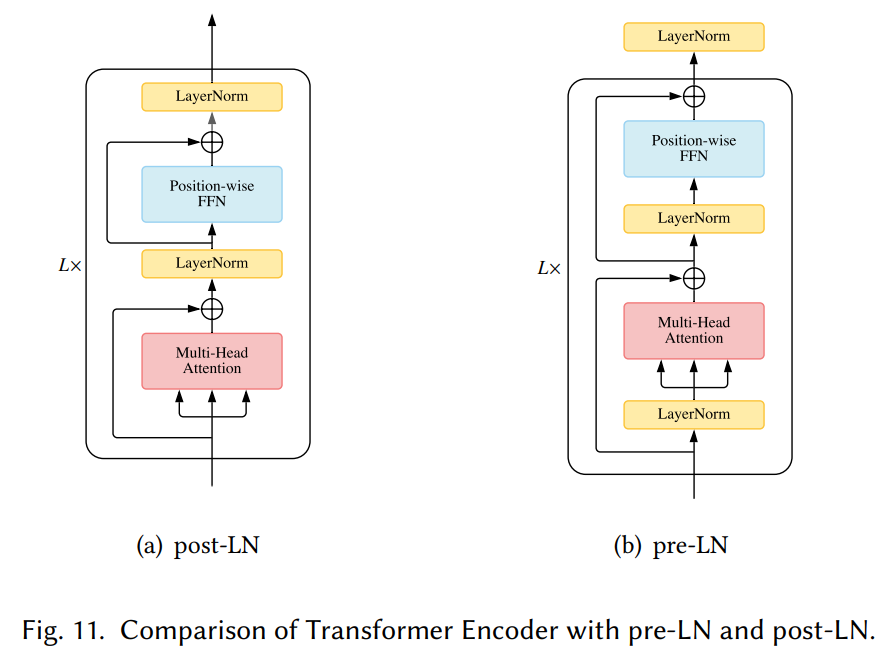
Pre-LN
GPT-2 使用 Pre-LN 的形式,如图所示:
参考
视频
We reproduce the GPT-2 (124M) from scratch. This video covers the whole process: First we build the GPT-2 network, then we optimize its training to be really fast, then we set up the training run following the GPT-2 and GPT-3 paper and their hyperparameters, then we hit run, and come back the next morning to see our results, and enjoy some amusing model generations. Keep in mind that in some places this video builds on the knowledge from earlier videos in the Zero to Hero Playlist (see my channel). You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
Links:
build-nanogpt GitHub repo, with all the changes in this video as individual commits: https://github.com/karpathy/build-nan…
nanoGPT repo: https://github.com/karpathy/nanoGPT
llm.c repo: https://github.com/karpathy/llm.c
my website: https://karpathy.ai
my twitter: / karpathy
our Discord channel: / discord
Supplementary links:
Attention is All You Need paper: https://arxiv.org/abs/1706.03762
OpenAI GPT-3 paper: https://arxiv.org/abs/2005.14165
OpenAI GPT-2 paper: https://d4mucfpksywv.cloudfront.net/b… The GPU I’m training the model on is from Lambda GPU Cloud, I think the best and easiest way to spin up an on-demand GPU instance in the cloud that you can ssh to: https://lambdalabs.com
Chapters:
00:00:00 intro: Let’s reproduce GPT-2 (124M)
00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint
00:13:47 SECTION 1: implementing the GPT-2 nn.Module
00:28:08 loading the huggingface/GPT-2 parameters
00:31:00 implementing the forward pass to get logits
00:33:31 sampling init, prefix tokens, tokenization
00:37:02 sampling loop
00:41:47 sample, auto-detect the device
00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
00:52:53 cross entropy loss
00:56:42 optimization loop: overfit a single batch
01:02:00 data loader lite
01:06:14 parameter sharing wte and lm_head
01:13:47 model initialization: std 0.02, residual init
01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
01:39:38 float16, gradient scalers, bfloat16, 300ms
01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
02:00:18 flash attention, 96ms
02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping
02:21:06 learning rate scheduler: warmup + cosine decay
02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms
02:34:09 gradient accumulation
02:46:52 distributed data parallel (DDP)
03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU)
03:23:10 validation data split, validation loss, sampling revive
03:28:23 evaluation: HellaSwag, starting the run
03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro
03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA
03:59:39 summary, phew, build-nanogpt github repo
Corrections: I will post all errata and followups to the build-nanogpt GitHub repo (link above)
SuperThanks: I experimentally enabled them on my channel yesterday. Totally optional and only use if rich. All revenue goes to to supporting my work in AI + Education.
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/06/12/nanogpt/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)