简介
TODO
模型定义
DeepseekForCausalLM(
(model): DeepseekModel(
(embed_tokens): Embedding(102400, 5120)
(layers): ModuleList(
(0): DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=512, out_features=32768, bias=False)
(o_proj): Linear(in_features=16384, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=12288, bias=False)
(up_proj): Linear(in_features=5120, out_features=12288, bias=False)
(down_proj): Linear(in_features=12288, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
(1-59): 59 x DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=512, out_features=32768, bias=False)
(o_proj): Linear(in_features=16384, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMoE(
(experts): ModuleList(
(0-159): 160 x DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=1536, bias=False)
(up_proj): Linear(in_features=5120, out_features=1536, bias=False)
(down_proj): Linear(in_features=1536, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=3072, bias=False)
(up_proj): Linear(in_features=5120, out_features=3072, bias=False)
(down_proj): Linear(in_features=3072, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
)
(norm): DeepseekRMSNorm()
)
(lm_head): Linear(in_features=5120, out_features=102400, bias=False)
)
预备知识
参考:
预备1:MHA

而后面的 MQA、GQA、MLA,都是围绕 “如何减少 KV Cache 同时尽可能地保证效果” 这个主题发展而来的产物。
预备2:MHA 的瓶颈
一个自然的问题是:为什么降低 KV Cache 的大小如此重要?
众所周知,一般情况下 LLM 的推理都是在 GPU 上进行,单张 GPU 的显存是有限的,一部分我们要用来存放模型的参数和前向计算的激活值,这部分依赖于模型的体量,选定模型后它就是个常数;另外一部分我们要用来存放模型的 KV Cache,这部分不仅依赖于模型的体量,还依赖于模型的输入长度,也就是在推理过程中是动态增长的,当 Context 长度足够长时,它的大小就会占主导地位,可能超出一张卡甚至一台机(8 张卡)的总显存量。
在 GPU 上部署模型的原则是:能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为 “卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于 “木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的 “拖累” 就越大,事实上即便是单卡 H100 内 SRAM 与 HBM 的带宽已经达到了 3TB/s,但对于 Short Context 来说这个速度依然还是推理的瓶颈,更不用说更慢的卡间、机间通信了。
所以,减少 KV Cache 的目的就是要实现在更少的设备上推理更长的 Context,或者在相同的 Context 长度下让推理的 batch size 更大,从而实现更快的推理速度或者更大的吞吐总量。当然,最终目的都是为了 实现更低的推理成本。
要想更详细地了解这个问题,读者可以进一步阅读《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》、《A guide to LLM inference and performance》、《LLM inference speed of light》等文章,这里就不继续展开了(主要是笔者水平也有限,唯恐说多错多)。
预备3:MQA

预备4:GQA
然而,也有人担心 MQA 对 KV Cache 的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个 MHA 与 MQA 之间的 过渡版本 GQA(Grouped-Query Attention)应运而生,出自论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》。

在 llama2/3-70B 中,GQA 的 \(g=8\),其他用了 GQA 的同体量模型基本上也保持了这个设置,这并非偶然,而是同样出于推理效率的考虑。我们知道,70B 这个体量的模型,如果不进行极端的量化,那么不可能部署到单卡(A100/H100 80G)上。单卡不行,那么就能单机了,一般情况下一台机可以装 8 张卡,刚才我们说了,Attention 的每个 Head 实际上是 独立运算然后拼接 起来的,当 \(g=8\) 时,正好可以 每张卡负责计算一组 K、V 对应的 Attention Head,这样可以在尽可能保证 K、V 多样性的同时 最大程度上减少卡间通信。
MLA(Multi-head Latent Attention)
参考:
有了 MHA、MQA、GQA 的铺垫,我们理解 MLA(Multi-head Latent Attention)就相对容易一些了。DeepSeek-V2 的技术报告里是从低秩投影的角度引入 MLA 的,以至于有部分读者提出 “为什么 LoRA 提出这么久了,直到 MLA 才提出对 KV Cache 低秩分解的做法” 之类的疑问。
然而,笔者认为低秩投影这个角度并不贴近本质,因为要说低秩投影的话,事实上只要我们将 GQA 的所有 K、V 叠在一起,就会发现 GQA 也相当于在做低秩投影:
![]()
综上,MLA 的本质改进不是低秩投影,而是低秩投影之后的工作。
阶段1:一般的线性变换 + 矩阵吸收


阶段2:Decoupled Rotary Position Embedding(解耦的 RoPE)
DeepSeek-V2 不能直接将 RoPE 应用在 压缩后的 KV 上,因为 RoPE 矩阵是位置敏感的,在推理过程中生成的 token 与当前的位置是相关联的,这就像是 一张高清图片压缩成一个标清图片,其位置信息发生了改变,不能直接使用。

这就导致 DeepSeek-V2 需要 重新计算每个 token 的位置信息,这会降低推理速度。为了解决 MLA 中的 RoPE 与低秩 KV 联合压缩不兼容的问题,DeepSeek 团队提出了 解耦 RoPE 的策略。
在这种策略中,DeepSeek-V2 使用 额外的多头查询(multi-head queries) 和 共享的键(shared keys) 来携带位置编码信息。这样,即使在低秩压缩的情况下,也能有效地保持位置信息,并且不会增加推理时的计算负担。

阶段3:最终形式
最后有一个细节,就是 MLA 的最终版本,还将 Q 的输入也改为了低秩投影形式,这与减少 KV Cache 无关,主要是为了减少训练期间参数量和相应的梯度(原论文说的是激活值,个人表示不大理解)所占的显存:
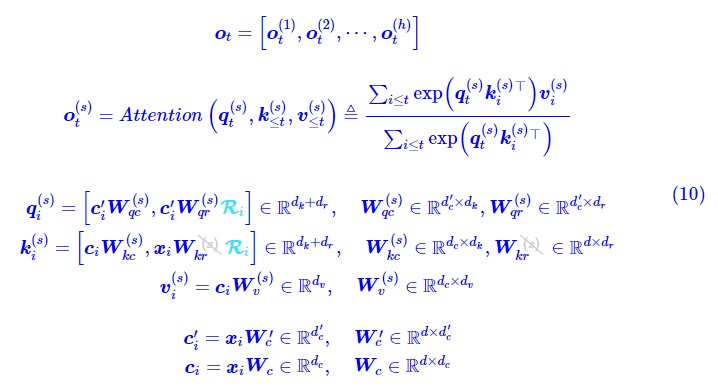
注意 \(k_i^{(s)}\) 中的第二项,带 RoPE 的部分,其输入还是 \(x_i\) 而不是 \(c_i\),这里保持了原论文的设置,不是笔误,\(d_c^{\prime}\) 原论文的取值是 \(1536\),跟 \(d_c=512\) 不同。
推理阶段的 MLA 则改为:
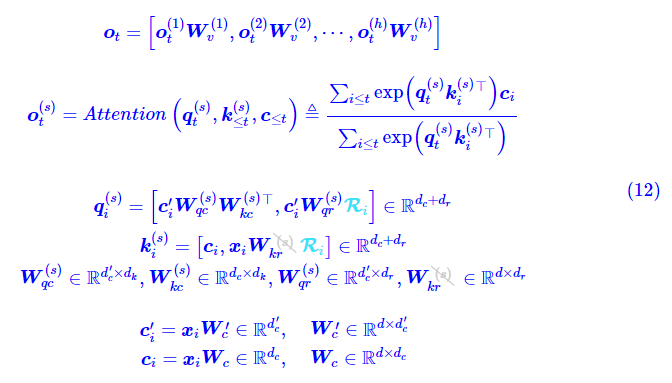
此时 Q、K 的 Head Size 变成了\(d_c+d_r\),V 的 Head Size 则变成了 \(d_c\),按照原论文的设置,这是 \(d_k\)、\(d_v\) 的 4 倍。所以实际上 MLA 在推理阶段做的这个转换,虽然能有效减少 KV Cache,但其推理的计算量是增加的。
那为什么还能提高推理效率呢?这又回到 “瓶颈” 一节所讨论的问题了,我们可以将 LLM 的推理分两部分:第一个 Token 的生成(Prefill)和后续每个 Token 的生成(Generation),Prefill 阶段涉及到对输入所有 Token 的并行计算,然后把对应的 KV Cache 存下来,这部分对于计算、带宽和显存都是瓶颈,MLA 虽然增大了计算量,但 KV Cache 的减少也降低了显存和带宽的压力,大家半斤八两;但是 Generation 阶段由于每步只计算一个 Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此 MLA 的引入理论上能明显提高 Generation 的速度。
还有一个细节充分体现了这个特性。一般的 LLM 架构参数满足 \(h×d_k=d\),即 num_heads * head_size = hidden_size,但 DeepSeek-V2 不一样,它 \(d_k=128,d=5120\),但 \(h=128\),是一般设置的 \(3\) 倍!这是因为 MLA 的 KV Cache 大小跟 \(h\) 无关,增大 \(h\) 只会增加计算量和提升模型能力,但不会增加 KV Cache,所以不会带来速度瓶颈。
GQA、MQA 虽然能够降低 KV Cache,但也伴随着性能的下降
低秩的 KV 联合压缩(Low-Rank Key-Value Joint Compression)
c is the compressed latent vector for keys and values
$W^{DKV}$:Down-Projection matrix
$W^{UK}$、$W^{UV}$:Up-Projection matrix
在推理阶段,MLA 只需要缓存 \(c\),因此只需要缓存 \(d_c\times l\) 个元素,其中 \(l\) 表示层数。

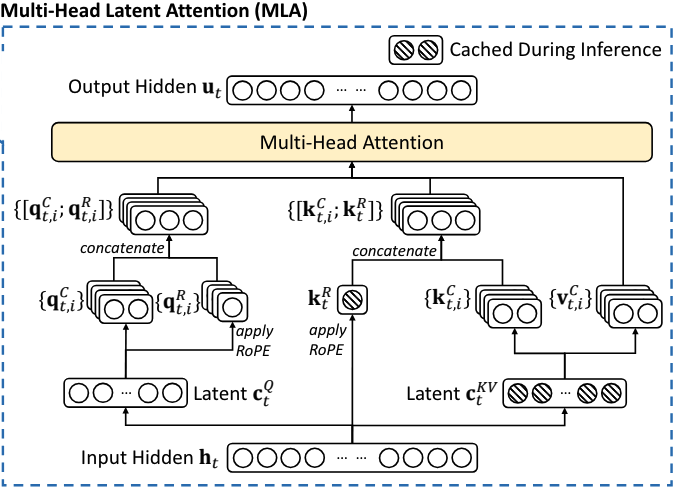
MLA 代码
参考:
"""queries 的处理"""
# t1: hidden_states: (b, s, 5120)
# t2: self.q_a_proj(hidden_states): (b, s, 1536)
# t3: self.q_a_layernorm(t2): (b, s, 1536)
# q: t4: self.q_b_proj(t3): (b, s, 128 * 192)
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
# t1: q: (b, s, 128 * 192)
# t2: q.view: (b, s, 128, 192)
# q: t3: t2.transpose(1, 2): (b, 128, s, 192 = (128 + 64))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
# q_nope: (b, 128, s, 128)
# q_pe: (b, 128, s, 64)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
"""keys and values 的处理"""
# t1: hidden_states: (b, s, 5120)
# compressed_kv: t2: self.kv_a_proj_with_mqa(t1): (b, s, 576 = 512 + 64)
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
# compressed_kv: (b, s, 512)
# k_pe: (b, s, 64)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
# t1: k_pe: (b, s, 64)
# t2: k_pe.view: (b, s, 1, 64)
# k_pe: t2.transpose(1, 2): (b, 1, s, 64)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
# t1: compressed_kv: (b, s, 512)
# t2: self.kv_a_layernorm(t1): (b, s, 512)
# t3: self.kv_b_proj(t2): (b, s, 128 * (128 + 128))
# t4: t3.view: (b, s, 128, 128 + 128)
# kv: t5: t4.transpose(1, 2): (b, 128, s, 128 + 128)
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
"""对部分 queries 和 keys 施加 RoPE"""
# k_nope: (b, 128, s, 128)
# value_states: (b, 128, s, 128)
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
# kv_seq_len: s
kv_seq_len = value_states.shape[-2]
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
# q_pe: (b, 128, s, 64)
# k_pe: (b, 1, s, 64)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
"""将经过 RoPE 的 queries 和 keys 分别于不需要经过 RoPE 的部分拼接
得到新的 queries 和 keys
"""
# query_states: (b, 128, s, 128 + 64)
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
# query_states 的 (b, 128, s, :128) 部分拼接不需要进行 rope 的部分
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
# query_states 的 (b, 128, s, 128:) 部分拼接进行了 rope 的部分
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
# key_states: (b, 128, s, 128 + 64)
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
# key_states 的 (b, 128, s, :128) 部分拼接不需要进行 rope 的部分
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
# key_states 的 (b, 128, s, 128:) 部分拼接进行了 rope 的部分
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
"""计算 attention"""
# t1: query_states: (b, 128, s, 192)
# t2: key_states.transpose(2, 3): (b, 128, 192, s)
# attn_weights: matmul(t1, t2): (b, 128, s, s)
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
)
# 计算 attention softmax 时 upcast 到 fp32
# attn_weights: (b, 128, s, s)
attn_weights = nn.functional.softmax(
attn_weights, dim=-1, dtype=torch.float32
).to(query_states.dtype)
attn_weights = nn.functional.dropout(
attn_weights, p=self.attention_dropout, training=self.training
)
"""得到最终的输出"""
# t1: attn_weights: (b, 128, s, s)
# t2: value_states: (b, 128, s, 128)
# attn_output: matmul(t1, t2): (b, 128, s, 128)
attn_output = torch.matmul(attn_weights, value_states)
# t1: attn_output: (b, 128, s, 128)
# attn_output: t2: t1.transpose(1, 2): (b, s, 128, 128)
attn_output = attn_output.transpose(1, 2).contiguous()
# t1: attn_output: (b, s, 128, 128)
# attn_output: t2: t1.reshape: (b, s, 128 * 128)
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim)
# t1: attn_output: (b, s, 128 * 128)
# attn_output: self.o_proj(t1): (b, s, 5120)
attn_output = self.o_proj(attn_output)
DeepSeekMoE
两个关键思想:
将专家细分为更细的粒度,以实现更高的专家专业化和更准确的知识获取(routed experts)
隔离一些共享专家以减轻路由专家之间的知识冗余(shared experts)
性能大幅优于 GShard 等传统的 MoE 架构
shared 2 expert + top-6 routed expert from 160 expert
TODO
参考
DeepSeek-V2:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/06/02/deepseek-v2/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)