简介
Extracting formulas from scientific papers has always been a challenging task.
本文介绍一些可以识别科学论文公式的工具,例如:
Nougat:Neural Optical Understanding for Academic Documents
- 基于端到端、可训练的 Transformer 模型(包含 Encoder-Decoder),用于将 PDF 页面转换为标记(markup)
- 其性能表现不如 Nougat
- 其性能表现不如 Nougat
- Nougat 就是基于该模型结构
Mathpix Snip:付费工具
Nougat
Nougat 基于 Donut 的端到端结构,其具体结构如下所示:
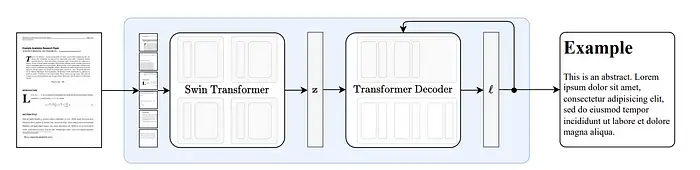
其中,
Swin Transformer Encoder:获取文档图像,并将其转化为特征向量(Embedding)
Transformer Decoder:根据特征向量,通过自回归的方式将其转化为 Token 序列
Nougat 在 arXiv 测试集上的实验结果如下所示:
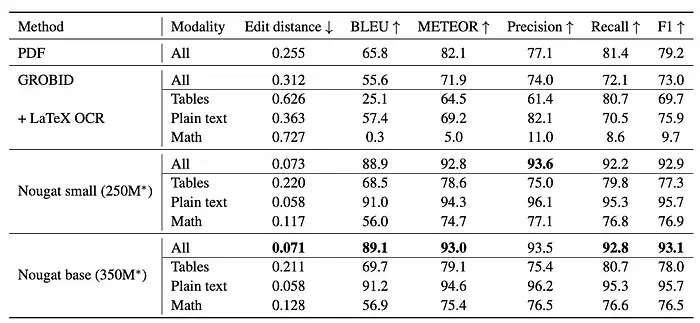
Nougat 安装
通过 pypi 进行安装:
pip install nougat-ocr
通过 github 进行安装:
pip install git+https://github.com/facebookresearch/nougat
CLI(命令行)运行
这里以 《Attention is all you need》 论文的第 5 页为例:

使用 naugat-base 模型进行识别与转换:
nougat ./1706.03762.pdf --model 0.1.0-base --page '5' -o ./results
运行结果如下所示:
WARNING:root:No GPU found. Conversion on CPU is very slow.
downloading nougat checkpoint version 0.1.0-base to path /root/.cache/torch/hub/nougat-0.1.0-base
config.json: 100% 560/560 [00:00<00:00, 1.78Mb/s]
pytorch_model.bin: 100% 1.31G/1.31G [00:06<00:00, 213Mb/s]
special_tokens_map.json: 100% 96.0/96.0 [00:00<00:00, 337kb/s]
tokenizer.json: 100% 2.04M/2.04M [00:00<00:00, 28.5Mb/s]
tokenizer_config.json: 100% 106/106 [00:00<00:00, 423kb/s]
/usr/local/lib/python3.10/dist-packages/torch/functional.py:507: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3549.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
0% 0/1 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/nougat/model.py:437: UserWarning: var(): degrees of freedom is <= 0. Correction should be strictly less than the reduction factor (input numel divided by output numel). (Triggered internally at ../aten/src/ATen/native/ReduceOps.cpp:1760.)
return torch.var(self.values, 1) / self.values.shape[1]
[nltk_data] Downloading package words to /root/nltk_data...
[nltk_data] Unzipping corpora/words.zip.
INFO:root:Processing file 1706.03762.pdf with 1 pages
100% 1/1 [07:26<00:00, 446.25s/it]
Nougat 默认输出的 MMD(Mathpix Markdown) 文件,与普通的 Markdown 文件不太兼容。可以通过 --markdown 来向下兼容 Markdown 文件。
直接使用 Typora 无法正确渲染相应的公式,因此,使用 VS Code 下载相应的插件 Mathpix Markdown,渲染后的结果如下所示:
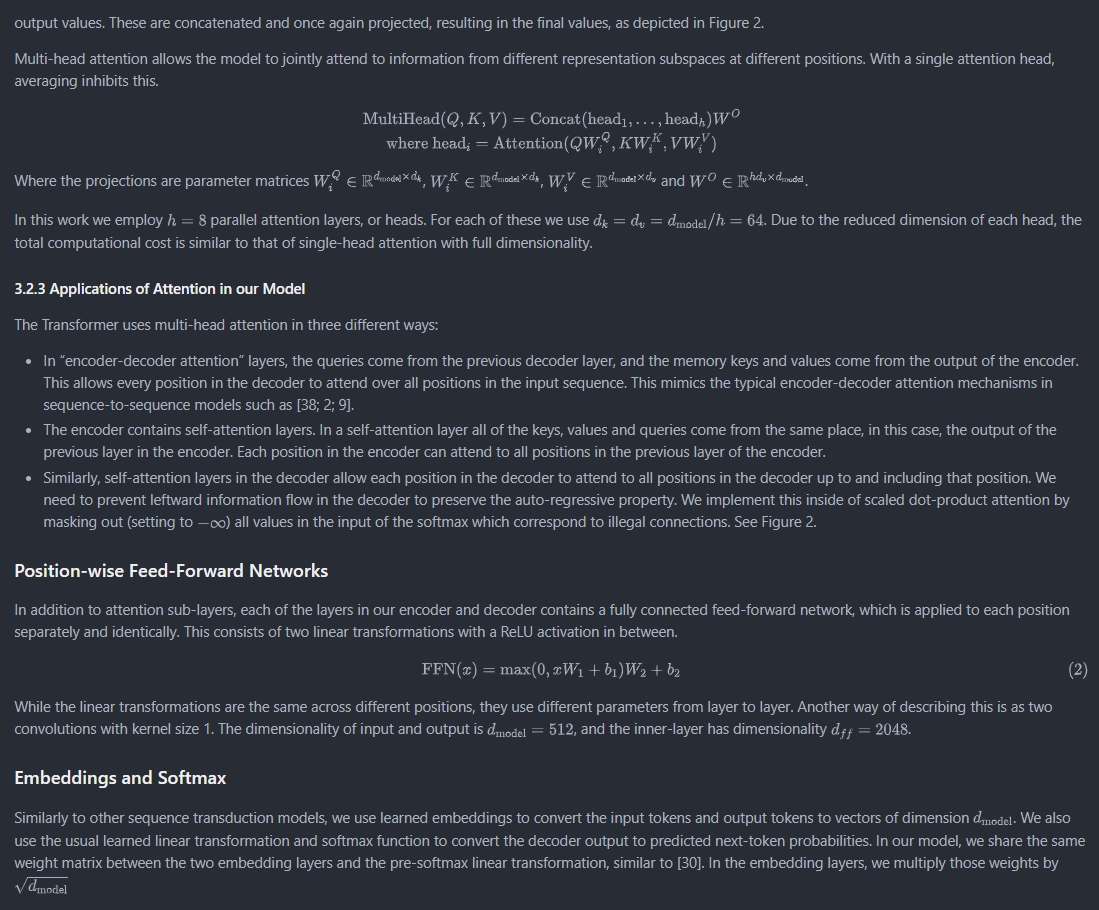
可以看到,Naugat 能够比较准确地对论文进行识别和转换,包括文本、公式。但是,标题中标号 `3.3` 和 `3.4` 没有被成功转换。
Nougat 完整的运行参数如下所示:
usage: nougat [-h] [--batchsize BATCHSIZE] [--checkpoint CHECKPOINT] [--model MODEL] [--out OUT]
[--recompute] [--markdown] [--no-skipping] pdf [pdf ...]
positional arguments:
pdf PDF(s) to process.
options:
-h, --help show this help message and exit
--batchsize BATCHSIZE, -b BATCHSIZE
Batch size to use.
--checkpoint CHECKPOINT, -c CHECKPOINT
Path to checkpoint directory.
--model MODEL_TAG, -m MODEL_TAG
Model tag to use.
--out OUT, -o OUT Output directory.
--recompute Recompute already computed PDF, discarding previous predictions.
--full-precision Use float32 instead of bfloat16. Can speed up CPU conversion for some setups.
--no-markdown Do not add postprocessing step for markdown compatibility.
--markdown Add postprocessing step for markdown compatibility (default).
--no-skipping Don't apply failure detection heuristic.
--pages PAGES, -p PAGES
Provide page numbers like '1-4,7' for pages 1 through 4 and page 7. Only works for single PDFs.
小结
上面的运行代码可以通过 Google Colab Notebook 获取
总的来说,Nougat 是一款出色的公式提取工具。
然而,作为一款端到端工具(它不需要任何与 OCR 相关的输入或模块,网络会隐式识别文本),它缺乏中间结果,而且定制选项似乎也很有限。
此外,Nougat 利用自回归前向传递来生成文本,这导致生成速度相对较慢,并增加了出现幻觉和重复的可能性。
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/04/15/extract-formulas-from-pdf/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)