简介
the AI-native open-source embedding database

Chroma is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.

特点
Simple: Fully-typed, fully-tested, fully-documented
Integrations: 能够集成 LangChain 以及 LlamaIndex
Dev, Test, Prod: the same API that runs in your python notebook, scales to your cluster
Feature-rich: Queries, filtering, density estimation and more
Free & Open Source: Apache 2.0 Licensed
核心代码(4 个函数)
import chromadb
from pprint import pprint
"""
创建一个客户端
"""
chroma_client = chromadb.Client()
"""
创建一个集合:向量、元数据等信息
类似于传统数据库的一张表
"""
collection = chroma_client.get_or_create_collection("test-1")
"""
添加数据
"""
collection.add(
documents=[
"This is a document",
"This is another document"
], # 文档/文本
metadatas=[
{"source": "my_source"},
{"source": "my_source"}
], # 元数据
ids=["id9", "id10"] # 序号
)
"""
从集合中检索
"""
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)
pprint(results)
Client(数据库)
本地持久化
前面代码中创建的集合不会落到数据盘中,只用于快速搭建项目原型,程序退出即消失。如果想使集合可以重复利用,只需要稍微修改一下代码即可:
# Client 改为 PersistentClient
client = chromadb.PersistentClient(path="/path/to/save/to")
客户端/服务端部署
实际项目一般不会只有客户端代码,因此 chroma 也被设计成可以客户端-服务端方式进行部署。
服务端启动命令:
# --path 参数可以指定数据持久化路径
# 默认开启 8000 端口
chroma run --path /db_path
客户端连接脚本:
import chromadb
client = chromadb.HttpClient(host='localhost', port=8000)
Collection(集合)
创建 or 选择集合
# 创建名称为 my_collection 的集合,如果已经存在,则会报错
collection = client.create_collection(name="my_collection", embedding_function=emb_fn)
# 获取名称为 my_collection 的集合,如果不存在,则会报错
collection = client.get_collection(name="my_collection", embedding_function=emb_fn)
# 获取名称为 my_collection 的集合,如果不存在,则创建
collection = client.get_or_create_collection(name="my_collection", embedding_function=emb_fn)
探索集合
# 检索
results = collection.query(
query_texts=["This is a query document"],
n_results=2
)
# 返回集合中的前 10 条记录
collection.peek()
# 返回集合的数量
collection.count()
# 重命名集合
collection.modify(name="new_name")
操作集合
增:add()
删:delete()
集合的删除操作通过指定
ids实现如果没有指定
ids,则会删除满足 where 的所有数据
collection.delete(
ids=["id1", "id2", "id3",...],
where={"chapter": "20"}
)
改:update()
集合的修改也是通过指定 id 实现,如果 id 不存在,则会报错。
如果更新的内容是 documents,则连同对应的 embeddings 都一并更新。
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
documents=["doc1", "doc2", "doc3", ...],
)
查:query 和 get() 两个接口
# 可以用文本进行查找,会调用模型对文本进行向量化表示,然后再查找出相似的向量
collection.query(
query_texts=["doc10", "thus spake zarathustra", ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
# 也可以用向量进行查找
collection.query(
query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
where 和 where_document 分别对元信息和文本进行过滤
collection.get(
ids=["id1", "id2", "id3", ...],
where={"style": "style1"},
where_document={"$contains":"search_string"}
)
get() 更像是传统意义上的 select 操作,同样也支持 where 和 where_document 两个过滤条件。
Embedding(嵌入)
嵌入是表示任何类型数据的 AI 原生方式,非常适合使用各种 AI 驱动的工具和算法。它们可以表示文本、图像,很快还可以表示音频和视频。
Chroma 有许多选项可用于创建嵌入,无论是在本地使用已安装的库,还是通过调用 API。
默认:all-MiniLM-L6-v2
默认情况下,Chroma 使用 all-MiniLM-L6-v2 的 Sentence Transformers 来创建 Embedding,如下所示:
/root/.cache/chroma/onnx_models/all-MiniLM-L6-v2/onnx.tar.gz: 100%|██████████| 79.3M/79.3M [00:01<00:00, 47.4MiB/s]
默认的嵌入函数如下所示:
from chromadb.utils import embedding_functions
default_ef = embedding_functions.DefaultEmbeddingFunction()
嵌入函数可以链接到集合,并在调用 add 、 update upsert 或 query 时使用。您也可以直接使用它们,这对于调试非常方便。
val = default_ef(["foo"])
"""
[[0.05035809800028801, 0.0626462921500206, -0.061827320605516434...]]
"""
其他 Sentence Transformer
Chroma 还可以使用任何 Sentence Transformer 模型来创建嵌入:
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
您可以传入一个可选 model_name 参数,该参数允许您选择要使用的句子转换器模型。默认情况下,Chroma 使用 all-MiniLM-L6-v2。
您可以在 这里 查看所有可用模型的列表。
自定义 Embedding Function
此外,Chroma 还可以与多种不同的嵌入模型进行集成,如下图所示:
例如,与 HuggingFace 模型进行集成:
import chromadb.utils.embedding_functions as embedding_functions
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key="YOUR_API_KEY", # HuggingFace 的 Access Token
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
您可以创建自己的嵌入函数以与 Chroma 一起使用,它只需要实现 EmbeddingFunction 即可:
from chromadb import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, input: Documents) -> Embeddings:
# embed the documents somehow
return embeddings
下面使用 text2vec 库中的嵌入模型来定义 EmbeddingFunction 的例子:
from chromadb import Documents, EmbeddingFunction, Embeddings
from text2vec import SentenceModel
# 加载 text2vec 库的向量化模型
model = SentenceModel('text2vec-chinese')
# Documents 是字符串数组类型,Embeddings 是浮点数组类型
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, input: Documents) -> Embeddings:
# embed the documents somehow
return model.encode(input).tolist()
Multi-modal(多模态)
Chroma 支持多模态集合,即可以存储多种数据模态并可由多种模式数据查询的集合。
除了对于文本(Document)数据的嵌入,Chroma 还可以处理图像(Image)、视频(Video)、语音(Audio)等多模态数据。
多模态的 Colab Demo
多模态嵌入函数
Chroma 支持多模态嵌入功能,可用于将来自多个模态的数据嵌入到单个嵌入空间中。
Chroma 内置了 OpenCLIP 嵌入函数,支持文本和图像。
from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction
"""
用到了 OpenAI 的 CLIP 文字-图片模型
"""
embedding_function = OpenCLIPEmbeddingFunction()
数据加载器
Chroma 支持数据加载器,用于通过 URI 存储和查询存储在 Chroma 本身之外的数据。
Chroma 不会存储此数据,而是存储 URI,并在需要时从 URI 加载数据。
Chroma 有一个数据加载器(data loader),用于从内置的文件系统加载图像。
from chromadb.utils.data_loaders import ImageLoader
data_loader = ImageLoader()
多模态集合
可以通过传入多模态嵌入函数来创建多模态集合(multi-modal collection)。
为了从 URI 加载数据,还必须传入数据加载器。
import chromadb
client = chromadb.Client()
collection = client.create_collection(
name='multimodal_collection',
embedding_function=embedding_function,
data_loader=data_loader
)
往集合中添加 numpy 类型的图片:
collection.add(
ids=['id1', 'id2', 'id3'],
images=[...] # A list of numpy arrays representing images
)
与文本检索类似,只是变成了 query_images 而已
results = collection.query(
query_images=[...] # A list of numpy arrays representing images
)
Integration(集成)
Chroma 与许多流行的 LLM 工具保持集成。这些工具可用于定义 AI 原生应用程序的业务逻辑、管理数据、微调嵌入空间等。包括:
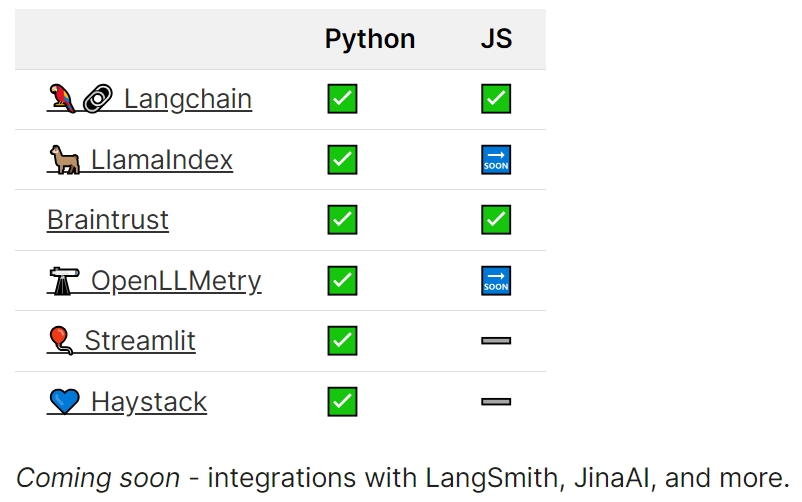
LangChain
参考:
LlamaIndex
参考:
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/04/14/chroma-database/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)