FastChat 介绍
FastChat 是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人。
FastChat 的核心功能包括:
最先进模型(例如 Vicuna、MT-Bench)的训练和评估代码
具有 Web UI 以及与 OpenAI 兼容的 RESTful API 的分布式多模型服务系统
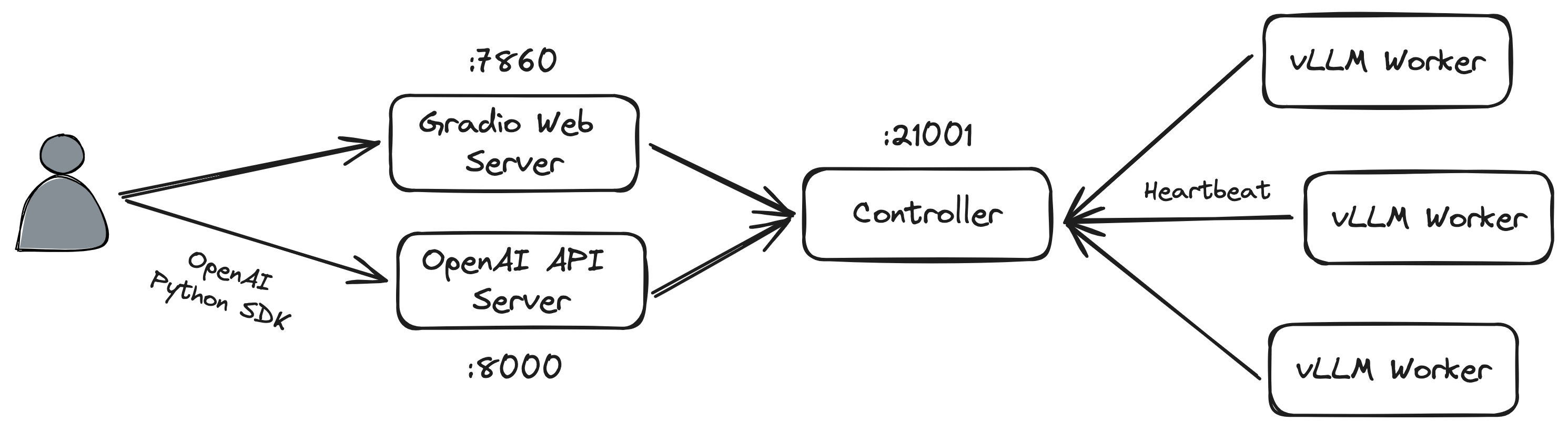
架构

FastChat 使用
安装
$ pip install fastchat
基本使用:CLI 模式
单 GPU 的使用方法
$ CUDA_VISIBLE_DEVICES=4 python -m fastchat.serve.cli --model-path ./model/chatglm2-6b --debug
其中,
--model-path可以是本地文件夹,也可以是 Hugging Face 存储库名称--debug可以打印有用的调试信息(例如提示、生成 token 的速度)
输出的内容如下所示:
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████| 7/7 [00:10<00:00, 1.45s/it]
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
问: 你好
答: 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:', 'outputs': '你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。', 'speed (token/s)': 13.29}
问: 请你讲一个冷笑话
答: 下面是一个冷笑话:
有一天,老师在课堂上问:“如果有五只鸟站在树枝上,你用气枪打死了一只,还剩下几只?”
学生回答:“还剩下零只,因为其他鸟会被枪声吓飞。”
老师沉思了一会儿,然后摇了摇头:“这样啊,那只能再等等了,等第五只鸟自己飞下来的时候再打。”
学生回应:“太好了,我正好有足够的时间可以写一篇文章。”
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。\n\n[Round 2]\n\n问:请你讲一个冷笑话\n\n答:', 'outputs': '下面是一个冷笑话:\n\n有一天,老师在课堂上问:“如果有五只鸟站在树枝上,你用气枪打死了一只,还剩下几只?”\n\n学生回答:“还剩下零只,因为其他鸟会被枪声吓飞。”\n\n老师沉思了一会儿,然后摇了摇头:“这样啊,那只能再等等了,等第五只鸟自己飞下来的时候再打。”\n\n学生回应:“太好了,我正好有足够的时间可以写一篇文章。”', 'speed (token/s)': 40.36}
问: 请你解释一下黑洞
答: 黑洞是宇宙中一种极其巨大质量密集的天体,它的存在基于爱因斯坦的广义相对论。黑洞是由一个事件视界所包围的区域,事件视界是一种类似于数学“无回头点”的范围,一旦任何东西进入了事件视界,就再也无法逃脱黑洞的引力。
黑洞的形成通常是由于一个超大质量恒星在死亡时,其核心因为内部的引力而塌缩成了一个非常小的区域,形成了一个非常致密的物体。这个物体的引力非常强大,甚至连光也无法逃脱,因此在宇宙中看起来就像是一个“黑洞”。
黑洞的大小由其质量决定,质量越大,黑洞的引力就越强,事件视界也就越大。黑洞的质量可以通过测量其自转和膨胀来估计,也可以通过观察周围天体的运动来确定。
黑洞是宇宙中最神秘、最具有挑战性的天体之一,对于我们了解宇宙的演化和引力物理的基本规律具有极其重要的意义。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。\n\n[Round 2]\n\n问:请你讲一个冷笑话\n\n答:下面是一个冷笑话:\n\n有一天,老师在课堂上问:“如果有五只鸟站在树枝上,你用气枪打死了一只,还剩下几只?”\n\n学生回答:“还剩下零只,因为其他鸟会被枪声吓飞。”\n\n老师沉思了一会儿,然后摇了摇头:“这样啊,那只能再等等了,等第五只鸟自己飞下来的时候再打。”\n\n学生回应:“太好了,我正好有足够的时间可以写一篇文章。”\n\n[Round 3]\n\n问:请你解释一下黑洞\n\n答:', 'outputs': '黑洞是宇宙中一种极其巨大质量密集的天体,它的存在基于爱因斯坦的广义相对论。黑洞是由一个事件视界所包围的区域,事件视界是一种类似于数学“无回头点”的范围,一旦任何东西进入了事件视界,就再也无法逃脱黑洞的引力。\n\n黑洞的形成通常是由于一个超大质量恒星在死亡时,其核心因为内部的引力而塌缩成了一个非常小的区域,形成了一个非常致密的物体。这个物体的引力非常强大,甚至连光也无法逃脱,因此在宇宙中看起来就像是一个“黑洞”。\n\n黑洞的大小由其质量决定,质量越大,黑洞的引力就越强,事件视界也就越大。黑洞的质量可以通过测量其自转和膨胀来估计,也可以通过观察周围天体的运动来确定。\n\n黑洞是宇宙中最神秘、最具有挑战性的天体之一,对于我们了解宇宙的演化和引力物理的基本规律具有极其重要的意义。', 'speed (token/s)': 38.79}
多 GPU 的使用方法
您可以使用模型并行性来聚合来自同一台计算机上多个 GPU 的 GPU 内存。
$ CUDA_VISIBLE_DEVICES=0,1 python3 -m fastchat.serve.cli --model-path ./model/chatglm2-6b --num-gpus 2 --debug
输出的内容如下所示:
问: 你好
答: 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:', 'outputs': '你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。', 'speed (token/s)': 12.65}
问: 请你详细解释一下黑洞
答: 黑洞是宇宙中一种极其巨大质量密度的天体,它形成于恒星演化过程中的非常规阶段——超新星爆发或星云的碰撞。黑洞的边界称为事件视界,越靠近事件视界,黑洞的引力就越强,距离事件视界越远,黑洞的引力就越弱。
黑洞具有非常强大的引力,即使是光也无法逃脱黑洞的引力范围,因此被称为“黑洞”。
黑洞的大小由其质量决定,质量越大,黑洞的边界事件视界也就越大。在天文学家中,黑洞的质量通常用太阳质量来衡量,最大的已知黑洞的质量可以达到数百亿个太阳质量。
黑洞对周围物体的影响也很大,可以摧毁周围的恒星和星云,甚至整个星系。在黑洞附近,物质会被吸入黑洞,形成所谓的“吞噬盘”。吞噬盘中的物质在黑洞强大的引力作用下,会迅速加热,产生强烈的辐射和高能粒子。
黑洞是宇宙中最神秘、最具有挑战性的天体之一,对于我们了解宇宙的演化和引力物理的基本规律具有极其重要的意义。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。\n\n[Round 2]\n\n问:请你详细解释一下黑洞\n\n答:', 'outputs': '黑洞是宇宙中一种极其巨大质量密度的天体,它形成于恒星演化过程中的非常规阶段——超新星爆发或星云的碰撞。黑洞的边界称为事件视界,越靠近事件视界,黑洞的引力就越强,距离事件视界越远,黑洞的引力就越弱。\n\n黑洞具有非常强大的引力,即使是光也无法逃脱黑洞的引力范围,因此被称为“黑洞”。\n\n黑洞的大小由其质量决定,质量越大,黑洞的边界事件视界也就越大。在天文学家中,黑洞的质量通常用太阳质量来衡量,最大的已知黑洞的质量可以达到数百亿个太阳质量。\n\n黑洞对周围物体的影响也很大,可以摧毁周围的恒星和星云,甚至整个星系。在黑洞附近,物质会被吸入黑洞,形成所谓的“吞噬盘”。吞噬盘中的物质在黑洞强大的引力作用下,会迅速加热,产生强烈的辐射和高能粒子。\n\n黑洞是宇宙中最神秘、最具有挑战性的天体之一,对于我们了解宇宙的演化和引力物理的基本规律具有极其重要的意义。', 'speed (token/s)': 38.8}
有时,huggingface / transformers 中的 “自动” 设备映射策略并不能完美地平衡多个 GPU 之间的内存分配。在上面的例子中,由于一张卡就足以将 ChatGLM-6B 加载到显卡中,因此实际上第二张卡并不会占用显存(几乎不起作用)。
因此,可以使用 --max-gpu-memory 指定每个 GPU 用于存储模型权重的最大内存。这允许它为激活分配更多内存,因此您可以使用更长的上下文长度或更大的批大小。例如:
$ CUDA_VISIBLE_DEVICES=0,1 python3 -m fastchat.serve.cli --model-path ./model/chatglm2-6b --num-gpus 2 --max-gpu-memory 8GiB --debug
纯 CPU 的使用方法
$ python3 -m fastchat.serve.cli --model-path ./model/chatglm2-6b --device cpu --debug
输出的内容如下所示:
问: 你好
答: 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:', 'outputs': '你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。', 'speed (token/s)': 3.06}
问: 请你介绍一下黑洞
答: 当物质的引力足够强大时,它会形成一个非常紧凑的物体,即黑洞。黑洞的边界称为事件视界,越靠近事件视界,黑洞的引力就越强。在事件视界内,引力使任何物质都无法逃脱,所以黑洞也被称为“黑洞”。
黑洞是由一个叫做爱因斯坦的物理学家在20世纪早期提出的概念。他通过引力理论,发现了一个质量与光线传播速度成正比的想法。这就是著名的引力波概念。
现实中已经发现了很多黑洞,但科学家还无法准确地计算它们的质量。黑洞是我们目前宇宙中了解最少的一种物体,因此有关黑洞的研究仍然非常活跃。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。\n\n[Round 2]\n\n问:请你介绍一下黑洞\n\n答:', 'outputs': '当物质的引力足够强大时,它会形成一个非常紧凑的物体,即黑洞。黑洞的边界称为事件视界,越靠近事件视界,黑洞的引力就越强。在事件视界内,引力使任何物质都无法逃脱,所以黑洞也被称为“黑洞”。\n\n黑洞是由一个叫做爱因斯坦的物理学家在20世纪早期提出的概念。他通过引力理论,发现了一个质量与光线传播速度成正比的想法。这就是著名的引力波概念。\n\n现实中已经发现了很多黑洞,但科学家还无法准确地计算它们的质量。黑洞是我们目前宇宙中了解最少的一种物体,因此有关黑洞的研究仍然非常活跃。', 'speed (token/s)': 3.49}
还可以使用 Intel AI Accelerator AVX512_BF16/AMX 加速 CPU 推理,例如:
$ CPU_ISA=amx python3 -m fastchat.serve.cli --model-path ./model/chatglm2-6b --device cpu --debug
输出的内容如下所示:
问: 你好
答: 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:', 'outputs': '你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。', 'speed (token/s)': 3.4}
问: 请你介绍一下黑洞
答: 黑洞是宇宙中一种极其天体,它的诞生源于天体间的核聚变。当一个非常大质量的天体耗尽其核心燃料时,会在内部崩塌并塌缩成为一个极端密集、强引力的物体。这种物体会吸收周围的物质,包括光线,使它们无法逃逸。这就是黑洞。
黑洞的体积通常很小,直径一般只有几十公里到数百万公里不等,但它们的质量却非常大。天文学家认为,一个黑洞的质量可能达到太阳质量的数十亿倍。
黑洞的强引力场非常强大,甚至连光都无法逃脱。这也是为什么它们被称为“黑洞”,因为它们会让任何接近它们的物体被吸引进去,包括光线。在黑洞的表面,物质被撕裂成最基本的粒子,例如原子核和夸克。
黑洞对宇宙的演化和结构产生了很大的影响。例如,它们可以改变星系和星团的形成和演化,还可以影响宇宙大尺度结构。同时,黑洞也是天文学家研究宇宙中引力和物质性质的重要领域。
{'conv_template': 'chatglm2', 'prompt': '[Round 1]\n\n问:你好\n\n答:你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。\n\n[Round 2]\n\n问:请你介绍一下黑洞\n\n答:', 'outputs': '黑洞是宇宙中一种极其天体,它的诞生源于天体间的核聚变。当一个非常大质量的天体耗尽其核心燃料时,会在内部崩塌并塌缩成为一个极端密集、强引力的物体。这种物体会吸收周围的物质,包括光线,使它们无法逃逸。这就是黑洞。\n\n黑洞的体积通常很小,直径一般只有几十公里到数百万公里不等,但它们的质量却非常大。天文学家认为,一个黑洞的质量可能达到太阳质量的数十亿倍。\n\n黑洞的强引力场非常强大,甚至连光都无法逃脱。这也是为什么它们被称为“黑洞”,因为它们会让任何接近它们的物体被吸引进去,包括光线。在黑洞的表面,物质被撕裂成最基本的粒子,例如原子核和夸克。\n\n黑洞对宇宙的演化和结构产生了很大的影响。例如,它们可以改变星系和星团的形成和演化,还可以影响宇宙大尺度结构。同时,黑洞也是天文学家研究宇宙中引力和物质性质的重要领域。', 'speed (token/s)': 3.73}
量化
如果没有足够的内存,可以通过添加 --load-8bit 上述命令来启用 8 位压缩。这样可以将内存使用量减少大约一半,而模型质量会略有下降。它与 CPU、GPU 和 Metal 后端兼容。
$ python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --load-8bit
除此之外,您还可以添加到 --cpu-offloading 上述命令中,将不适合 GPU 的权重卸载到 CPU 内存上。这需要启用 8 位压缩并安装 bitsandbytes 包,该包仅在 Linux 操作系统上可用。
Web UI
要使用 Web UI 提供服务,您需要三个主要组件:与用户交互的 Web 服务器、托管一个或多个模型的模型工作器,以及用于协调 Web 服务器和模型作业(worker)的控制器。
首先,开启控制器:
$ python3 -m fastchat.serve.controller
这个控制器用于管理分布式的作业(worker)线程。
接着,启动模型作业(model worker):
$ python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
等到该过程完成加载模型,您会看到 “Uvicorn running on …”。模型作业将自身 注册 到控制器。
要确保模型作业已经正确连接到控制器,可以使用以下命令发送测试消息 test_message:
$ python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.5
最后,开启 Gradio 网络服务:
$ python3 -m fastchat.serve.gradio_web_server
这是用户将与之交互的用户界面。通过执行这些步骤,您将能够使用 Web UI 提供模型。您现在可以打开浏览器并与模特聊天。如果模型未显示,请尝试重新启动 gradio 的 Web 服务器。
支持的模型
API
参考:
- FastChat 文档
FastChat 为其支持的模型提供与 OpenAI 兼容的 API,因此您可以将 FastChat 用作 OpenAI API 的本地替代品。FastChat 服务器兼容 openai-python 库和 cURL 命令。
支持以下 OpenAI API:
Chat Completions(参考:https://platform.openai.com/docs/api-reference/chat)
Completions(参考:https://platform.openai.com/docs/api-reference/completions)
Embeddings(参考:https://platform.openai.com/docs/api-reference/embeddings)
部署过程如下:
首先,启动控制器:
$ python -m fastchat.serve.controller --host 127.0.0.1 --port 21001
2024-01-21 22:01:25 | INFO | controller | args: Namespace(host='127.0.0.1', port=21001, dispatch_method='shortest_queue', ssl=False)
2024-01-21 22:01:25 | ERROR | stderr | INFO: Started server process [40157]
2024-01-21 22:01:25 | ERROR | stderr | INFO: Waiting for application startup.
2024-01-21 22:01:25 | ERROR | stderr | INFO: Application startup complete.
2024-01-21 22:01:25 | ERROR | stderr | INFO: Uvicorn running on http://127.0.0.1:21001 (Press CTRL+C to quit)
2024-01-21 22:01:55 | INFO | controller | Register a new worker: http://localhost:21002
2024-01-21 22:01:55 | INFO | controller | Register done: http://localhost:21002, {'model_names': ['chatglm2-6b'], 'speed': 1, 'queue_length': 0}
2024-01-21 22:01:55 | INFO | stdout | INFO: 127.0.0.1:47242 - "POST /register_worker HTTP/1.1" 200 OK
2024-01-21 22:02:46 | INFO | controller | Register an existing worker: http://localhost:21002
2024-01-21 22:02:46 | INFO | controller | Register done: http://localhost:21002, {'model_names': ['chatglm2-6b'], 'speed': 1, 'queue_length': 0}
# 发送心跳包
2024-01-21 22:02:46 | INFO | stdout | INFO: 127.0.0.1:40412 - "POST /register_worker HTTP/1.1" 200 OK
2024-01-21 22:03:31 | INFO | controller | Receive heart beat. http://localhost:21002
2024-01-21 22:03:31 | INFO | stdout | INFO: 127.0.0.1:59534 - "POST /receive_heart_beat HTTP/1.1" 200 OK
2024-01-21 22:04:16 | INFO | controller | Receive heart beat. http://localhost:21002
然后,启动模型工作节点,并将其注册到控制器中:
$ python -m fastchat.serve.model_worker --model-path ./model/chatglm2-6b --host 127.0.0.1 --port 8100
2024-01-21 22:02:28 | INFO | model_worker | args: Namespace(host='127.0.0.1', port=8100, worker_address='http://localhost:21002', controller_address='http://localhost:21001', model_path='./model/chatglm2-6b', revision='main', device='cuda', gpus=None, num_gpus=1, max_gpu_memory=None, dtype=None, load_8bit=False, cpu_offloading=False, gptq_ckpt=None, gptq_wbits=16, gptq_groupsize=-1, gptq_act_order=False, awq_ckpt=None, awq_wbits=16, awq_groupsize=-1, enable_exllama=False, exllama_max_seq_len=4096, exllama_gpu_split=None, exllama_cache_8bit=False, enable_xft=False, xft_max_seq_len=4096, xft_dtype=None, model_names=None, conv_template=None, embed_in_truncate=False, limit_worker_concurrency=5, stream_interval=2, no_register=False, seed=None, debug=False, ssl=False)
2024-01-21 22:02:28 | INFO | model_worker | Loading the model ['chatglm2-6b'] on worker d3b69e58 ...
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:09<00:00, 1.40s/it]
2024-01-21 22:02:38 | ERROR | stderr |
2024-01-21 22:02:46 | INFO | model_worker | Register to controller
2024-01-21 22:02:46 | ERROR | stderr | INFO: Started server process [41219]
2024-01-21 22:02:46 | ERROR | stderr | INFO: Waiting for application startup.
2024-01-21 22:02:46 | ERROR | stderr | INFO: Application startup complete.
2024-01-21 22:02:46 | ERROR | stderr | INFO: Uvicorn running on http://127.0.0.1:8100 (Press CTRL+C to quit)
# 发送心跳包
2024-01-21 22:03:31 | INFO | model_worker | Send heart beat. Models: ['chatglm2-6b']. Semaphore: None. call_ct: 0. worker_id: d3b69e58.
2024-01-21 22:04:16 | INFO | model_worker | Send heart beat. Models: ['chatglm2-6b']. Semaphore: None. call_ct: 0. worker_id: d3b69e58.
2024-01-21 22:05:01 | INFO | model_worker | Send heart beat. Models: ['chatglm2-6b']. Semaphore: None. call_ct: 0. worker_id: d3b69e58.
2024-01-21 22:05:46 | INFO | model_worker | Send heart beat. Models: ['chatglm2-6b']. Semaphore: None. call_ct: 0. worker_id: d3b69e58.
2024-01-21 22:06:31 | INFO | model_worker | Send heart beat. Models: ['chatglm2-6b']. Semaphore: None. call_ct: 0. worker_id: d3b69e58.
最后,启动 RESTful API 服务器:
$ python -m fastchat.serve.openai_api_server --host 127.0.0.1 --port 8000
2024-01-21 22:04:11 | INFO | openai_api_server | args: Namespace(host='127.0.0.1', port=8000, controller_address='http://localhost:21001', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_keys=None, ssl=False)
2024-01-21 22:04:11 | ERROR | stderr | INFO: Started server process [41435]
2024-01-21 22:04:11 | ERROR | stderr | INFO: Waiting for application startup.
2024-01-21 22:04:11 | ERROR | stderr | INFO: Application startup complete.
2024-01-21 22:04:11 | ERROR | stderr | INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
执行下列的命令,查看所有已经注册到控制器的工作节点:
$ curl http://127.0.0.1:8000/v1/models
但是,发现返回的结构是空的:
{
"object": "list",
"data": []
}
具体的原因尚不清楚,Github 仓库上也有一些 Issue 反馈了这一问题,但是尚不知道如何处理。
TODO
高级功能
可扩展性
可以将 多个模型作业注册到单个控制器,该控制器可用于为具有更高吞吐量的单个模型提供服务,或同时为多个模型提供服务。执行此操作时,请为不同的模型工作线程分配不同的 GPU 和端口。
# worker 0
$ CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5 --controller http://localhost:21001 --port 31000 --worker http://localhost:31000
# worker 1
$ CUDA_VISIBLE_DEVICES=1 python3 -m fastchat.serve.model_worker --model-path lmsys/fastchat-t5-3b-v1.0 --controller http://localhost:21001 --port 31001 --worker http://localhost:31001
还可以启动一个 多选项卡 的 gradio 服务器,其中包括 Chatbot Arena 选项卡:
$ python3 -m fastchat.serve.gradio_web_server_multi
与 vLLM 集成
参考:
![]()
基于 huggingface / transformers 的默认模型 worker 具有很好的兼容性,但速度可能很慢。
如果想要高吞吐量的批量服务,可以尝试与 vLLM 集成。
- 安装 vLLM
$ pip install vllm
- 启动模型工作程序时,将普通工作程序
fastchat.serve.model_worker替换为 vLLM 工作程序fastchat.serve.vllm_worker:
$ python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-7b-v1.5
其他的所有命令(如控制器、gradio Web 服务器和 OpenAI API 服务器)保持不变。
如果看到分词器错误,请尝试:
$ python3 -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-7b-v1.5 --tokenizer hf-internal-testing/llama-tokenizer
如果使用 AWQ 量化模型,请尝试:
$ python3 -m fastchat.serve.vllm_worker --model-path TheBloke/vicuna-7B-v1.5-AWQ --quantization awq
第三方 Web UI
Controller 解析
参考:
controller.py 中的 get_worker_address() 方法定义了两种工作节点(worker)的调度方法:LOTTERY 和 SHORTEST_QUEUE。这两种方法决定了当有一个任务需要执行时,应该选择哪个工作节点来执行这个任务。
如果没有指定上述两种方法中的任何一种,方法会引发一个值错误。
总的来说,这两种调度方法都试图在工作节点之间均衡地分配任务,但它们的方法和侧重点不同:
LOTTERY 方法侧重于工作节点的速度
SHORTEST_QUEUE 方法侧重于工作节点的当前负载
LOTTERY(抽奖)
这种方法基于每个 工作节点的速度 来随机选择一个工作节点。工作节点的速度越高,被选中的概率就越大。
首先,该方法收集所有支持给定模型的工作节点的名称和速度
然后,它将速度转换为一个 概率分布,这样速度较高的工作节点会有更高的概率被选中
使用
np.random.choice根据这个概率分布随机选择一个工作节点有一个被注释掉的部分,它会在返回工作节点之前检查工作节点的状态。如果工作节点不可用,它会从列表中移除,并重新计算概率分布,然后再次尝试选择
SHORTEST_QUEUE(最短队列)
这种方法选择 当前队列长度最短 的工作节点。队列长度表示工作节点上 待处理的任务数量。这种方法的目的是尽量均衡地分配任务,避免某些工作节点过载而其他工作节点空闲。
首先,收集所有支持给定模型的工作节点的名称和队列长度
然后,计算每个工作节点的队列长度与其速度的 比值。这是因为速度较快的工作节点可以更快地处理任务,所以即使它的队列稍微长一点,它仍然可能是一个好的选择
使用
np.argmin找到队列长度与速度比值最小的工作节点选择的工作节点的队列长度加 1,表示有一个新任务被分配给它
controller 整体结构
controller.py 是一个使用 FastAPI 框架的服务器应用,其主要目的是 管理和调度多个工作节点(worker)。这些工作节点可以理解为运行特定模型的服务器实例。
以下是对代码的详细解析:
导入模块:代码开始时导入了一系列必要的模块,如
argparse用于命令行参数解析,asyncio用于异步操作,dataclasses用于数据类,fastapi用于API服务器等。日志设置:使用
build_logger函数从fastchat.utils创建一个日志记录器。调度方法枚举:定义了一个
DispatchMethod枚举,它有两个值:LOTTERY和SHORTEST_QUEUE,分别表示两种不同的工作节点选择策略。工作节点信息数据类:
WorkerInfo数据类用于存储工作节点的信息,如 模型名称、速度、队列长度 等。心跳控制器:
heart_beat_controller函数是一个无限循环,用于定期检查工作节点的心跳并删除过期的工作节点。Controller类:
__init__:初始化函数中,创建一个空的工作节点信息字典和一个心跳线程register_worker:注册或更新工作节点的信息get_worker_status:从工作节点获取其状态remove_worker:从注册列表中删除工作节点refresh_all_workers:刷新所有工作节点的状态list_models:列出所有可用模型get_worker_address:根据选择的调度方法返回一个工作节点地址receive_heart_beat:接收工作节点的心跳并更新其状态remove_stale_workers_by_expiration:删除过期的工作节点handle_no_worker和handle_worker_timeout:处理没有工作节点或工作节点超时的情况worker_api_get_status和worker_api_generate_stream:允许控制器作为工作节点来获取状态或生成数据流
FastAPI 应用:定义了一个 FastAPI 应用和一系列 API 端点,如
register_worker、refresh_all_workers、list_models等。create_controller函数:解析命令行参数并创建一个控制器实例主执行部分:如果这个脚本是主程序,则创建一个控制器并运行 FastAPI 应用
调度代码解析
def get_worker_address(self, model_name: str):
# 基于抽奖的调度方法
if self.dispatch_method == DispatchMethod.LOTTERY:
worker_names = [] # 用于存储支持给定模型的工作节点的名称
worker_speeds = [] # 用于存储支持给定模型的工作节点的处理速度
# 遍历所有已注册的工作节点
for w_name, w_info in self.worker_info.items():
# 如果当前工作节点支持给定的模型
if model_name in w_info.model_names:
worker_names.append(w_name)
worker_speeds.append(w_info.speed)
# 将工作节点的速度转换为 NumPy 数组
worker_speeds = np.array(worker_speeds, dtype=np.float32)
norm = np.sum(worker_speeds) # 计算所有工作节点的速度总和
if norm < 1e-4: # 如果总速度接近于零,则没有合适的工作节点
return ""
worker_speeds = worker_speeds / norm # 计算每个工作节点速度对应的概率分布
if True: # 这是一个始终为真的条件,可能是代码的遗留部分(可忽略)
pt = np.random.choice(np.arange(len(worker_names)), p=worker_speeds)
worker_name = worker_names[pt]
return worker_name
# 在选择工作节点之前,先检查被选中的工作节点的状态
# 如果工作节点不可用,它会从列表中移除,并重新计算概率分布,然后再次尝试选择
while True:
pt = np.random.choice(np.arange(len(worker_names)), p=worker_speeds)
worker_name = worker_names[pt]
if self.get_worker_status(worker_name):
break
else:
self.remove_worker(worker_name)
worker_speeds[pt] = 0
norm = np.sum(worker_speeds)
if norm < 1e-4:
return ""
worker_speeds = worker_speeds / norm
continue
return worker_name
# 基于最短队列的调度方法
elif self.dispatch_method == DispatchMethod.SHORTEST_QUEUE:
worker_names = [] # 用于存储支持给定模型的工作节点的名称
worker_qlen = [] # 用于存储工作节点的队列长度与处理速度的比值
# 遍历所有已注册的工作节点
for w_name, w_info in self.worker_info.items():
# 如果当前工作节点支持给定的模型
if model_name in w_info.model_names:
worker_names.append(w_name)
# 计算队列长度与速度的比值
worker_qlen.append(w_info.queue_length / w_info.speed)
if len(worker_names) == 0: # 如果没有工作节点支持给定的模型,返回空字符串
return ""
# 找到队列长度与处理速度比值最小的工作节点
min_index = np.argmin(worker_qlen)
w_name = worker_names[min_index]
# 增加该工作节点的队列长度,表示有一个新任务被分配给它
self.worker_info[w_name].queue_length += 1
# 记录一条日志,显示所有工作节点的名称、队列长度和被选中的工作节点的名称
logger.info(
f"names: {worker_names}, queue_lens: {worker_qlen}, ret: {w_name}"
)
return w_name
else: # 如果没有指定上述两种方法中的任何一种,引发一个值错误
raise ValueError(f"Invalid dispatch method: {self.dispatch_method}")
参考
Github:
文档:
CSDN:
知乎:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/01/19/fastchat/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)