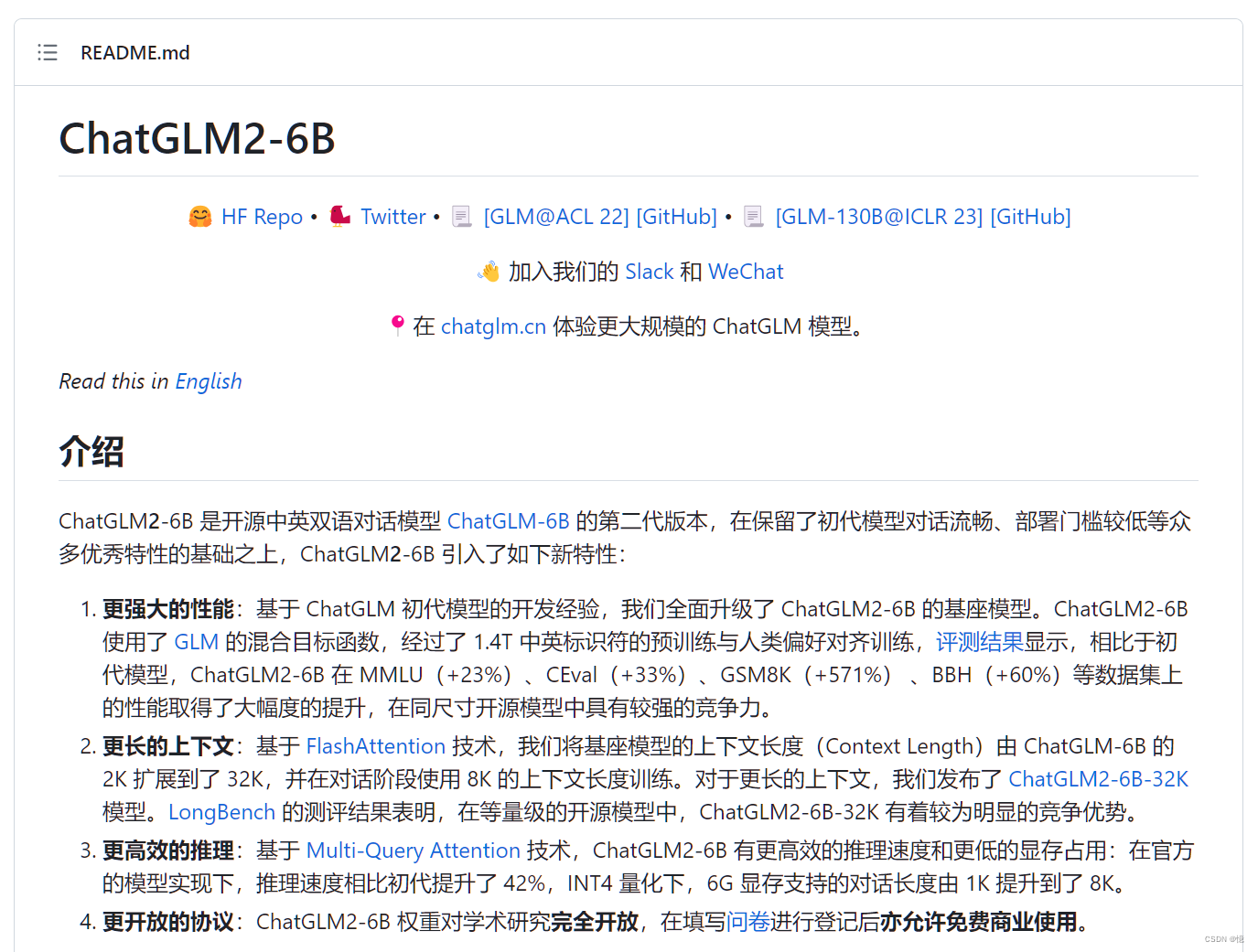
LangChain-Chatchat 的前身是 LangChain-ChatGLM
1、部署
系统环境:
LangChain-Chatchat 版本:v0.2.9
操作系统:Ubuntu 20.04.5 LTS (GNU/Linux 5.15.0-88-generic x86_64)
GPU:Nvidia V100S 32GB
Python:3.10
1.1、创建虚拟环境,下载依赖
$ conda create -n Chatchat python==3.10
$ conda activate Chatchat
$ pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
langchain-ChatGLM /configs/model_config.py:模型配置文件,默认的模型路径是 ./model/
https://github.com/jayli/langchain-ChatGLM/blob/main/configs/model_config.py
1.2、下载本地模型
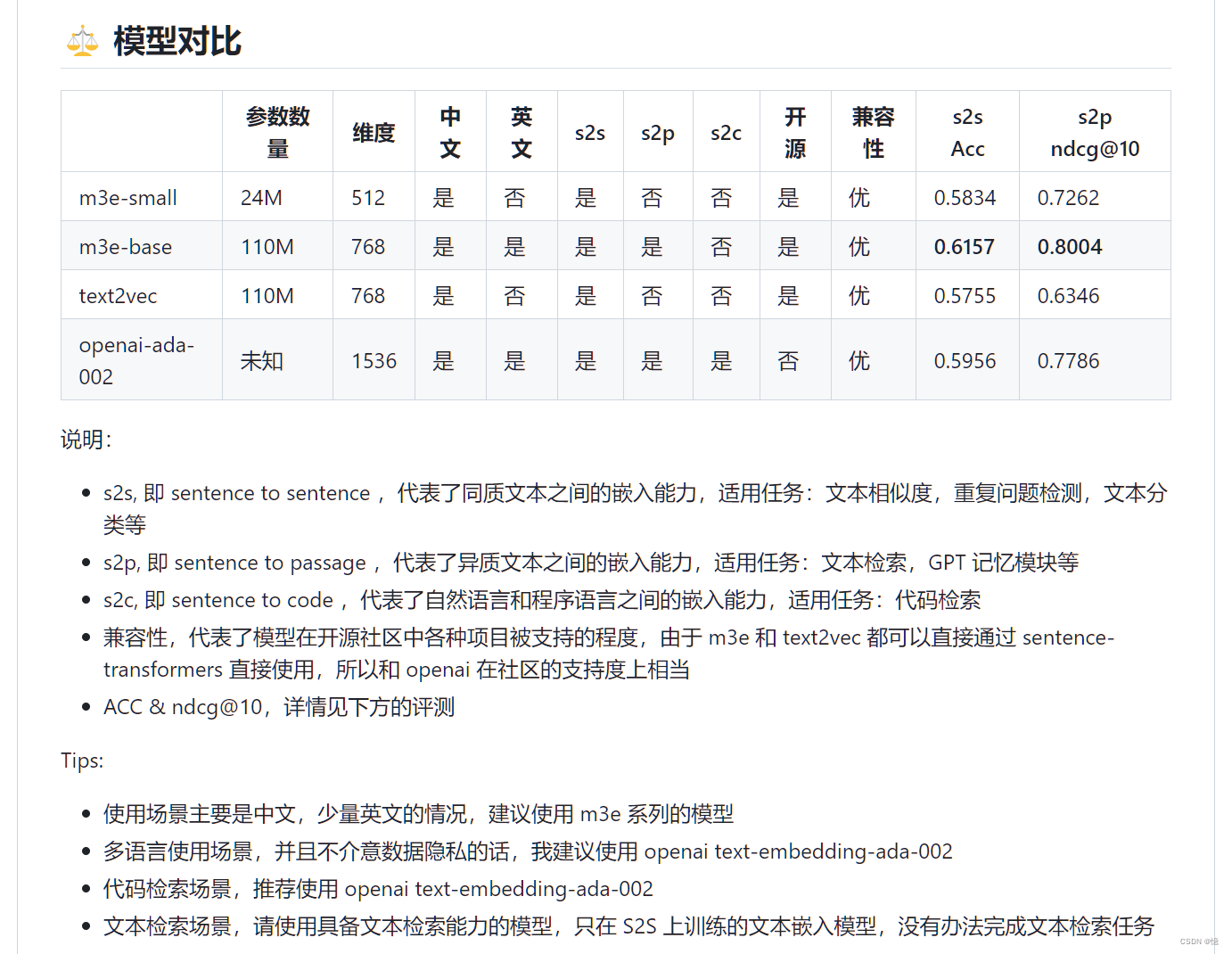
以下各类模型均仅演示一个对应的模型,更多支持的模型可以查看 []
$ sudo apt-get install git-lfs
$ git lfs install
Updated git hooks.
Git LFS initialized.
$ git clone https://huggingface.co/THUDM/chatglm2-6b
Cloning into 'chatglm2-6b'...
fatal: unable to access 'https://huggingface.co/THUDM/chatglm2-6b/': Failed to connect to huggingface.co port 443: Connection refused
$ git clone https://huggingface.co/THUDM/chatglm2-6b -c http.proxy="http://127.0.0.1:7890"
Cloning into 'chatglm2-6b'...
remote: Enumerating objects: 186, done.
remote: Counting objects: 100% (186/186), done.
remote: Compressing objects: 100% (81/81), done.
remote: Total 186 (delta 104), reused 186 (delta 104), pack-reused 0
Receiving objects: 100% (186/186), 1.92 MiB | 1.98 MiB/s, done.
Resolving deltas: 100% (104/104), done.
Filtering content: 100% (8/8), 11.63 GiB | 10.70 MiB/s, done.
1.2.1、Embedding 模型
这里采用的是 m3e-base 模型:
$ git clone https://huggingface.co/moka-ai/m3e-base
1.2.2、LLM 模型
这里采用的是 chatglm2-6b 模型:
$ git clone https://huggingface.co/THUDM/chatglm2-6b -c http.proxy="http://127.0.0.1:7890"
Cloning into 'chatglm2-6b'...
remote: Enumerating objects: 186, done.
remote: Counting objects: 100% (186/186), done.
remote: Compressing objects: 100% (81/81), done.
remote: Total 186 (delta 104), reused 186 (delta 104), pack-reused 0
Receiving objects: 100% (186/186), 1.92 MiB | 1.98 MiB/s, done.
Resolving deltas: 100% (104/104), done.
Filtering content: 100% (8/8), 11.63 GiB | 10.70 MiB/s, done.
1.3、修改配置文件
自行创建「model」文件夹
下载模型解压到「model」文件夹中
复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
1.3.1、修改模型配置
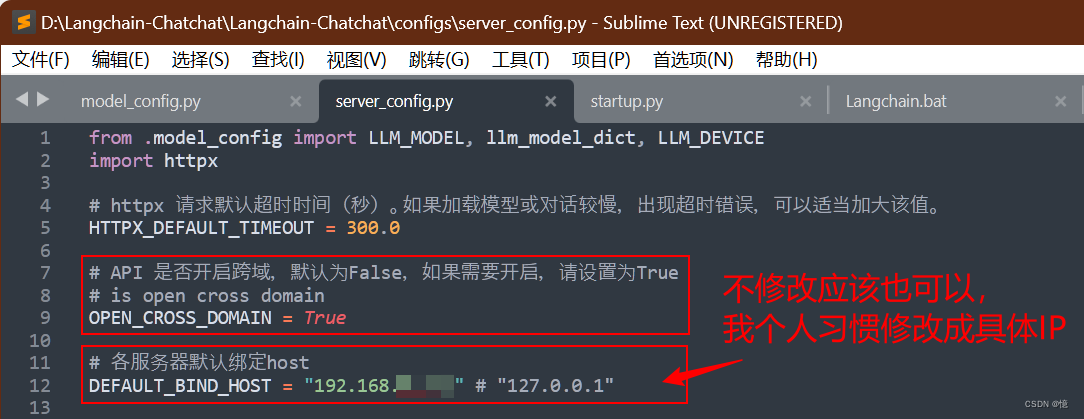
1.3.2、修改 Server 配置
server_config.py 服务配置修改:
1.3.3、修改知识库配置
1.4、启动
1.4.1、知识库的初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
如果您是从 0.1.x 版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型与 configs/model_config.py 中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可:
$ python init_database.py
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启 normalize_L2,需要以下命令初始化或重建知识库:
$ python init_database.py --recreate-vs
输出的结果:
recreating all vector stores
2024-01-03 21:07:33,096 - faiss_cache.py[line:94] - INFO: loading vector store in 'samples/vector_store/m3e-base' from disk.
2024-01-03 21:07:33,373 - SentenceTransformer.py[line:66] - INFO: Load pretrained SentenceTransformer: /workspace/why/cpx/code/Langchain-Chat/model/m3e-base
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.14s/it]
2024-01-03 21:07:39,139 - loader.py[line:54] - INFO: Loading faiss with AVX2 support.
2024-01-03 21:07:39,418 - loader.py[line:56] - INFO: Successfully loaded faiss with AVX2 support.
/opt/conda/envs/Chatchat/lib/python3.10/site-packages/langchain_community/vectorstores/faiss.py:122: UserWarning: Normalizing L2 is not applicable for metric type: METRIC_INNER_PRODUCT
warnings.warn(
2024-01-03 21:07:39,464 - faiss_cache.py[line:94] - INFO: loading vector store in 'samples/vector_store/m3e-base' from disk.
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 91.23it/s]
2024-01-03 21:07:39,486 - utils.py[line:289] - INFO: UnstructuredFileLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/test.txt
2024-01-03 21:07:39,487 - utils.py[line:289] - INFO: CSVLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.csv
2024-01-03 21:07:39,487 - utils.py[line:289] - INFO: JSONLinesLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.jsonl
2024-01-03 21:07:39,488 - utils.py[line:289] - INFO: RapidOCRPDFLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain.pdf
2024-01-03 21:07:39,488 - utils.py[line:289] - INFO: CSVLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.csv
2024-01-03 21:07:39,489 - utils.py[line:289] - INFO: UnstructuredExcelLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.xlsx
2024-01-03 21:07:39,489 - utils.py[line:289] - INFO: UnstructuredExcelLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.xlsx
2024-01-03 21:07:39,490 - utils.py[line:289] - INFO: JSONLinesLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.jsonl
2024-01-03 21:07:39,490 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型指令对齐训练原理.md
2024-01-03 21:07:39,491 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型推理优化策略.md
2024-01-03 21:07:39,491 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型技术栈-算法与原理.md
2024-01-03 21:07:39,492 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-923924-83386.jpg
2024-01-03 21:07:39,492 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-805089-731888.jpg
2024-01-03 21:07:39,493 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-930255-616209.jpg
2024-01-03 21:07:39,493 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-349153-657791.jpg
2024-01-03 21:07:39,493 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-590671-36787.jpg
2024-01-03 21:07:39,494 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-20096-279847.jpg
2024-01-03 21:07:39,494 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-299768-254064.jpg
2024-01-03 21:07:39,495 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-350029-666381.jpg
2024-01-03 21:07:39,495 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-729151-372321.jpg
2024-01-03 21:07:39,496 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-124076-270516.jpg
2024-01-03 21:07:39,497 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-618350-869132.jpg
2024-01-03 21:07:39,497 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-789705-122117.jpg
2024-01-03 21:07:39,498 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-628857-182232.jpg
2024-01-03 21:07:39,498 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-380552-579242.jpg
2024-01-03 21:07:39,499 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-906937-836104.jpg
2024-01-03 21:07:39,499 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-36114-765327.jpg
2024-01-03 21:07:39,515 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-42284-124759.jpg
2024-01-03 21:07:39,543 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-580318-260070.jpg
2024-01-03 21:07:39,575 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-81470-404273.jpg
2024-01-03 21:07:39,606 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg
2024-01-03 21:07:39,672 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-95996-523276.jpg
文档切分示例:page_content=': 0\ntitle: 效果如何优化\nfile: 2023-04-04.00\nurl: https://github.com/imClumsyPanda/langchain-ChatGLM/issues/14\ndetail: 如图所示,将该项目的README.md和该项目结合后,回答效果并不理想,请问可以从哪些方面进行优化\nid: 0' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.csv', 'row': 0}
2024-01-03 21:07:40,118 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-17565-176537.jpg
正在将 samples/test_files/langchain-ChatGLM_open.csv 添加到向量库,共包含323条文档
Batches: 0%| | 0/11 [00:00<?, ?it/s]2024-01-03 21:07:40,153 - utils.py[line:371] - ERROR: RuntimeError: 从文件 samples/test_files/langchain-ChatGLM_closed.csv 加载文档时出错:Error loading /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.csv
2024-01-03 21:07:40,153 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-108319-429731.jpg
Batches: 18%|████████████▉ | 2/11 [00:12<01:05, 7.29s/it]No module named 'transformers_modules'0: 0%| | 0/8 [00:00<?, ?it/s]
No module named 'transformers_modules'
文档切分示例:page_content='{"title": "效果如何优化", "file": "2023-04-04.00", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/14", "detail": "如图所示,将该项目的README.md和该项目结合后,回答效果并不理想,请问可以从哪些方面进行优化", "id": 0}' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.jsonl', 'seq_num': 1}
2024-01-03 21:07:52,709 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-699343-219844.jpg
文档切分示例:page_content='{"title": "加油~以及一些建议", "file": "2023-03-31.0002", "url": "https://github.com/imClumsyPanda/langchain-ChatGLM/issues/2", "detail": "加油,我认为你的方向是对的。", "id": 0}' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.jsonl', 'seq_num': 1}
2024-01-03 21:07:52,736 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-19929-302935.jpg
2024-01-03 21:07:53,821 - main.py[line:158] - WARNING: Because the aspect ratio of the current image exceeds the limit (min_height or width_height_ratio), the program will skip the detection step.
Batches: 100%|██████████████████████████████████████████████████████████████████████| 11/11 [00:45<00:00, 4.12s/it]
('samples', 'test_files/langchain-ChatGLM_closed.csv', '从文件 samples/test_files/langchain-ChatGLM_closed.csv 加载文档时出错:Error loading /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.csv')
正在将 samples/test_files/langchain-ChatGLM_open.jsonl 添加到向量库,共包含394条文档
Batches: 46%|████████████████████████████████▊ | 6/13 [00:22<00:30, 4.38s/it]2024-01-03 21:09:18,544 - xml.py[line:105] - INFO: Reading document from string ... | 3/8 [01:02<01:35, 19.03s/it]
2024-01-03 21:09:18,545 - html.py[line:151] - INFO: Reading document ...
2024-01-03 21:09:18,610 - common.py[line:601] - INFO: HTML element instance has no attribute type
2024-01-03 21:09:18,622 - xml.py[line:105] - INFO: Reading document from string ...
2024-01-03 21:09:18,623 - html.py[line:151] - INFO: Reading document ...
2024-01-03 21:09:18,623 - common.py[line:601] - INFO: HTML element instance has no attribute type
Batches: 54%|██████████████████████████████████████▏ | 7/13 [00:31<00:35, 5.98s/it]2024-01-03 21:09:21,565 - xml.py[line:105] - INFO: Reading document from string ...
2024-01-03 21:09:21,694 - html.py[line:151] - INFO: Reading document ...
2024-01-03 21:09:22,004 - common.py[line:601] - INFO: HTML element instance has no attribute type
Batches: 62%|███████████████████████████████████████████▋ | 8/13 [00:36<00:28, 5.68s/it]2024-01-03 21:09:26,470 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-454007-940199.jpg
Batches: 69%|█████████████████████████████████████████████████▏ | 9/13 [00:38<00:18, 4.55s/it]文档切分示例:page_content='大模型推理优化策略' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型推理优化策略.md'}
2024-01-03 21:09:26,598 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-918388-323086.jpg
文档切分示例:page_content='阶段一:监督训练阶段,此阶段包括以下步骤:\n1.获得Helpful模型对redteaming提示的响应。因此,在这些情况下,模型的响应可能是有\n害的。\n2.在提供了一套应该遵守的原则,让Helpful模型据此评论自己的响应。\n3.要求Helpful模型根据其提供的评论修改其先前的响应\n4.重复步骤2和3进行n次选代\n5.针对来自所有有害提示的响应的所有修订版本微调预训练的LLM1,还包括有用的提示和响应\n的组合,以确保微调后的模型仍然有用,此模型即SupervisedLearningConstitutional\nAI(SL-CAI)模型。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-17565-176537.jpg'}
2024-01-03 21:09:26,647 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-793118-735987.jpg
文档切分示例:page_content='大模型指令对齐训练原理\nRLHF\nSFT\nRM\nPPO\nAIHF-based\nRLAIF\n核心在于通过AI 模型监督其他 AI 模型,即在SFT阶段,从初始模型中采样,然后生成自我批评和修正,然后根据修正后的反应微调原始模型。在 RL 阶段,从微调模型中采样,使用一个模型来评估生成的样本,并从这个 AI 偏好数据集训练一个偏好模型。然后使用偏好模型作为奖励信号对 RL 进行训练' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型指令对齐训练原理.md'}
2024-01-03 21:09:26,706 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-276446-401476.jpg
文档切分示例:page_content='NVIDIA Megatron Trains LLM\nPipelineParallelism\nDevice 1\n910111213141516\nDevice 2\n910111213141516\nDevice 3\n910111213141516\nDevice 4\n910111213141516\n10\n1F1Bschedule\nDevice 1\n101112\n1F1B:\nDevice 2\n9101112\n10\nreduce memory' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-20096-279847.jpg'}
2024-01-03 21:09:26,936 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-759487-923925.jpg
文档切分示例:page_content='阶段二:强化学习阶段,此阶段包括以下步骤:\n1.使用在上一步训练得到的SL-CAI\n模型生成针对有害提示的响应对,\n2.使用具有一个原则和一对响应的反馈模型,去选择更无害的响应\n3.反馈模型的归一化对数概率用于训练偏好模型/奖励模型\n4.最后,利用上一步训练的偏好模型作为奖励函数,以RLHF方式训练SL-CAI模型,得\n到ReinforcementLearning\nConstitutionalAl (RL-CAl)\n模型。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-95996-523276.jpg'}
2024-01-03 21:09:27,175 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-838373-426344.jpg
文档切分示例:page_content='(b,S,v/N)\n(b, s)\n(b,S,v/N)\n(b, s)\n计算\n计算每行\n计算总loss\n按行求和\nAlIReduce\ne/sum(e)\nloss\nY1\nY1\nscalar\ne1\n(b,s)\nL1\nL1\nAlIReduce\n(b, S,v/N)\nscalar\n(b, s)\n(b, S, v/N)\n(b, s)' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-124076-270516.jpg'}
2024-01-03 21:09:27,907 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-220157-552735.jpg
文档切分示例:page_content='具体算法流程为\n1.搭建神经网络\n2.训练神经网络至损失函数收敛\n3.计算神经网络每个参数的二阶导数\nhkk\n4.计算神经网络每个参数的显著性:Sk=hkku2/2\n5.按照显著性对参数进行排序,并删除一些低显著性的参数。可认为删除参数是将其设置为0并训\n练时冻结。\n6.从步骤2开始重复' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-628857-182232.jpg'}
2024-01-03 21:09:30,340 - utils.py[line:289] - INFO: RapidOCRLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-57107-679259.jpg
文档切分示例:page_content='上图展示了DAPPLE的workflow,包括DAPPLEProfiler、DAPPLEPlanner、DAPPLE\nRuntime,基本流程如下:\n1.DAPPLEProfiler用户的DNN模型,每一层的执行时间、activation大小和模型参数大小作为\n输入;\n2.Profiler产生的结果作为输入,DAPPLEPlanner在给定的全局批量大小上生成优化的\n(混合)\n并行化计划;\n3.DAPPLERuntime获取Planner的结果,并将原始模型图转换为流水线并行图。\nDAPPLEPlanner其中,planner旨在最小化一次训练迭代的端到端执行时间(考虑通信开销、\nglobalbatchsize等),如解决不均匀的模型stage切片。该模块负责Stage切分、设备分配,并' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-906937-836104.jpg'}
2024-01-03 21:09:30,517 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型应用技术原理.md
文档切分示例:page_content='PPO\nRRHF\nUseasarewardmodel\nAdvantage\nExpert Score\nSelecttofine-tune\nChatGPT Score\nAlign by ranking\nReward Model\nReference Model\nModel Score\nModel Response\nQuery Value\nLanguage Model\nLanguage Model\nValue Model\nQuery\nExpert Response\n100\nQuery\nQuery\nChatGPT Response\nReward\n80\n气东来\nQuery\nModel Response\nRRHF V.S PPO' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-805089-731888.jpg'}
2024-01-03 21:09:31,409 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型技术栈-实战与应用.md
文档切分示例:page_content='YO\nAttention(Q,K,V)=softmax\n其中\nQ,K,V∈r\nNxd\n(N表示序列长度,d表示维度),上述公式可拆解为:\nS=QK\nER\nN×N\nP = softmax(S) ∈ R\nNxN\nO=PV∈R\nNxd' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-380552-579242.jpg'}
2024-01-03 21:09:31,506 - utils.py[line:289] - INFO: UnstructuredMarkdownLoader used for /workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/分布式训练技术原理.md
文档切分示例:page_content='NVIDIA Megatron Trains LLM\nPipelineParallelism\nDevice 1\n101112\nLayer 1-4\nDevice 2\n9101112\n10\nLayer5-8\nDevice 3\n9101112\n13\n10\n11\nLayer 9-12\nDevice 4\n10\n10\n11\n11\n12\nLayer 13-16\nTime' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-618350-869132.jpg'}
文档切分示例:page_content='Response\nGenerate Responses\nto“Red Teaming”\nFinetuned\nHelpful RLHF\nCritique\nSL-CAI\nModel\nPrompts Eliciting\nModel\nHarmful Samples\nRevision\nConstitutional Al Feedback\nGenerate Responses\nforSelf-lmprovement\nRLAIF\nto“Red Teaming\nPreference\nFinetuned\nTraining\nFinal\nPrompts Eliciting\nwith\nRL-CAI\nPairsofSamples\nModel (PM)' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-349153-657791.jpg'}
文档切分示例:page_content='Y1\nY2\nWE1\nWE2\n(h,v/N)\n知s@猛猿\n(b, s, h)\n(b,S,v/N)' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-42284-124759.jpg'}
Batches: 77%|█████████████████████████████████████████████████████▊ | 10/13 [00:45<00:15, 5.31s/it]文档切分示例:page_content='Algorithm2 FLAsHATTENTIONForwardPass\nRequire: Matrices Q,K,V ∈ RNxd in HBM, on-chip SRAM of size M, softmax scaling constant ∈ R,\nmasking function MAsK,dropout probability Pdrop\n1:Initialize thepseudo-random number generator stateR and save toHBM.\n2:Set block sizes B=[],B,=min(],d).\n3:InitializeO=(0)Nxd∈RNxd,=(O)N∈R,m=(-oo)N ∈R in HBM.\nblocks Q..,QΩz, of size B, xd each, and divide K, V in to T =blocks\nK1,...,KT.and V1,...,VT,of size Bx d each.' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-590671-36787.jpg'}
文档切分示例:page_content='Algorithm1QuantizeWgiveninverseHessianH-1=(2Xx+XI)-1andblocksizeB.\nQ←0dwxdo\nl/quantizedoutput\nE←OdxB\nl/blockquantizationerrors\nH-←Cholesky(H-)\n//Hessianinverseinformation\nfori=0,B,2B,...do\nforj=i,...,i+B-1do\nQ:←quant(W.)\nl/quantizecolumn\nE:j-i←(W:j-Q:5)/[H-]j\nl/guantizationerror\nj.j:(i+B)\nI/updateweightsinblock\nendfor' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-729151-372321.jpg'}
文档切分示例:page_content='大模型技术栈-算法与原理\ntokenizer方法\nword-level\nchar-level\nsubword-level\nBPE\nWordPiece\nUniLM\nSentencePiece\nByteBPE\nposition encoding\n绝对位置编码\nROPE\nAliBi\n相对位置编码\nTransformer-XL\nT5/TUPE\nDeBERTa\n其他位置编码\n注意力机制\n稀疏注意力\nflash-attention' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型技术栈-算法与原理.md'}
2024-01-03 21:09:36,026 - xml.py[line:105] - INFO: Reading document from string ...
文档切分示例:page_content='的forward计算:把输入X拷贝到两块GPU上,每块GPU即可独立做forward计算。\n的forward计算:\n每块GPU上的forward的计算完毕,取得Z1和Z2后,GPU间做一次\nAllReduce,相加结果产生Z。\n的backward计算:只需要把\n拷贝到两块GPU上,两块GPU就能各自独立做梯度计算\n的backward计算:当当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们\n需要求得\n则l正比时两块GPU做一次AlReduce,\n把各自的梯度\nax\n[2\nax\nax\n相加即可。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-36114-765327.jpg'}
2024-01-03 21:09:36,041 - xml.py[line:105] - INFO: Reading document from string ...
2024-01-03 21:09:36,070 - html.py[line:151] - INFO: Reading document ...
文档切分示例:page_content='Algorithm1SpeculativeDecodingStep\nInputs: Mp, Mq, prefic.\nSample guesses x1..\nfromMyautoregressively\nfori=1 todo\nqi(c)<Mq(prefic+[c1,...,ci-1])\nCi~qi(x)\nend for\nRun Mp in parallel.\np1(x),...,P+1(x)<\nMp(prefix),...,Mp(prefic+[ci,...,c])\nDeterminethenumberofacceptedguessesn.\nr1~U(0,1),...,r~U(0,1)\nn←min({i-1|1≤i≤,ri>' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-923924-83386.jpg'}
2024-01-03 21:09:36,094 - xml.py[line:105] - INFO: Reading document from string ...
2024-01-03 21:09:36,119 - html.py[line:151] - INFO: Reading document ...
2024-01-03 21:09:36,171 - common.py[line:601] - INFO: HTML element instance has no attribute type
文档切分示例:page_content='将activation的量化难度转移到weight上,需要引l入平滑因子s,则\nY =(X diag(s)-1) ·(diag(s)W)=xw\n为了减少激活的量化难度,可以让s=ma(X),j=1,2,...,C,即第j个channel\n的最大值。\n但是这样weight的量化难度会变得难以量化,因此需要引入另一个超参转移强度Q,\nS=max(X;1) / max(/W,1)1-α\n其中α可以根据activation和weight的量化难易程度进行调整,对于大多数模型α=0.5,\n对于模型GLM-130B,由于其activation值更加难以量化,设置α=0.75,可以更好地进行量\n化。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-81470-404273.jpg'}
2024-01-03 21:09:36,198 - html.py[line:151] - INFO: Reading document ...
2024-01-03 21:09:36,199 - common.py[line:601] - INFO: HTML element instance has no attribute type
2024-01-03 21:09:36,375 - common.py[line:601] - INFO: HTML element instance has no attribute type
文档切分示例:page_content='其学习过程如下:令X=α1,···,n是一组n个训练提示。\n给定一个初始模型\n型g(wo,),\nRAFT\n迭代更新\nWo,如算法1。在每个阶段t,RAFT平\n采样一批提示并通过\ng(wt-1,÷)\n生成响\n应。\n这些样本的相关奖励是使用奖励函数计算。\nRAFT\n随后对收集的样本进行排序并选择1/k百\n分比的具有最高奖励的样本作为训练样本B。然后在这个数据集上对模型进行微调,下一阶段开\n始。\n在这个过程中,采样训练数据的过程和模型训练是完全解耦的。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-350029-666381.jpg'}
文档切分示例:page_content='argminwa\n(quant(wq)-wg)²\n[H-²]g\n99\nw—quant(wg)\nH-\n[H-²1q' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-19929-302935.jpg'}
文档切分示例:page_content='Vamana\n这个算法和NSG[2][4]思路比较像(不了解NSG的可以看参考文献2,不想读paper的话可以\n看参考文献4),主要区别在于裁边策略。准确的说是给NSG的裁边策略上加了一个开关\nalpha。NSG的裁边策略主要思路是:对于目标点邻居的选择尽可能多样化,如果新邻居相比目标\n点,更靠近目标点的某个邻居,我们可以不必将这个点加入邻居点集中。也就是说,对于目标点的\n每个邻居节点,周围方圆dist(目标点,邻居点)范围内不能有其他邻居点。这个裁边策略有效控\n制了图的出度,并且比较激进,所以减少了索引的内存占用,提高了搜索速度,但同时也降低了搜\n索精度。Vamana的裁边策略其实就是通过参数alpha自由控制裁边的尺度。具体作用原理是给' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-580318-260070.jpg'}
文档切分示例:page_content='AlgorithmOStandardAttentionImplementation\nRequire:Matrices\nQ,K,VERNxd\ninHBM.\n1:Load Q,K by blocks from HBM,compute S=QKT,write S to HBM.\nRead Sfrom HBM,computeP=softmax(S),writePtoHBM.\n3:\nLoad PandVbyblocks fromHBM,compute O=PV,write O toHBM.\n知乎\n@紫气东来\n4:Return' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-789705-122117.jpg'}
Batches: 85%|███████████████████████████████████████████████████████████▏ | 11/13 [00:51<00:11, 5.59s/it]文档切分示例:page_content='Type\nInput\nOutput\nDefinitions\n/,y\n{yes, no, continue}\nDecides when to retrieve with R\nRetrieve\nIsREL\nC,d\nrelevant, irrelevant}\nd provides useful information to solve .\nx,d,y\nIsSUP\n[fully supported, partially\nAll of the verification-worthy statement in y\nsupported, no support}\nis supported by d.\nIsUsE\nc,y\n{5, 4,3, 2, 1}\ny is a useful response to .' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-108319-429731.jpg'}
文档切分示例:page_content='Multi-head\nGrouped-query\nMulti-query\nValues\nKeys\n00000000\nQueries' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-699343-219844.jpg'}
Batches: 92%|████████████████████████████████████████████████████████████████▌ | 12/13 [00:52<00:04, 4.14s/it]文档切分示例:page_content='大模型应用技术原理\nRAG\n向量数据库 对比\n选型标准\n开源vs.闭源vs. 源码可见\n客户端/SDK语言\n托管方式\nself-hosted/on-premise\nredis,pgvector,milvus\nmanaged/cloud-native\nzilliz,pinecone\nembeded+cloud-native\nchroma,lanceDB\nself-hosted+cloud-native\nvald,drant,weaviate,vspa,elasticsearch\n索引方法\n算法\nFlat\nTree-based\nAnnoy(Approximate Nearest Neighbors Oh Yeah)\nKD-Tree\nTrinary Projection Trees\nIVF\nIVF\nIVMF(Inverted Multi-index File)\nGraph-based\nHNSW\nNSG\nVamana(DiskANN)' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型应用技术原理.md'}
Batches: 100%|██████████████████████████████████████████████████████████████████████| 13/13 [00:53<00:00, 4.14s/it]
文档切分示例:page_content='分布式训练技术原理\n数据并行\nFSDP\nFSDP算法是由来自DeepSpeed的ZeroRedundancyOptimizer技术驱动的,但经过修改的设计和实现与PyTorch的其他组件保持一致。FSDP将模型实例分解为更小的单元,然后将每个单元内的所有参数扁平化和分片。分片参数在计算前按需通信和恢复,计算结束后立即丢弃。这种方法确保FSDP每次只需要实现一个单元的参数,这大大降低了峰值内存消耗。(数据并行+Parameter切分)\nDDP\nDistributedDataParallel (DDP), 在每个设备上维护一个模型副本,并通过向后传递的集体AllReduce操作同步梯度,从而确保在训练期间跨副本的模型一致性 。为了加快训练速度, DDP将梯度通信与向后计算重叠 ,促进在不同资源上并发执行工作负载。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/分布式训练技术原理.md'}
文档切分示例:page_content='大模型技术栈-实战与应用\n训练框架\ndeepspeed\nmegatron-lm\ncolossal-ai\ntrlx\n推理框架\ntriton\nvllm\ntext-generation-inference\nlit-llama\nlightllm\nTensorRT-LLM(原FasterTransformer)\nfastllm\ninferllm\nllama-cpp\nopenPPL-LLM\n压缩框架\nbitsandbytes\nauto-gptq\ndeepspeed\nembedding框架\nsentence-transformer\nFlagEmbedding\n向量数据库 向量数据库对比\nfaiss\npgvector\nmilvus\npinecone\nweaviate\nLanceDB\nChroma\n应用框架\nAuto-GPT\nlangchain\nllama-index\nquivr\npython前端\nstreamlit\ngradio' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/大模型技术栈-实战与应用.md'}
文档切分示例:page_content='BoolQ\nPIQA\nSIQA\nHella-Swag\nARC-e\nARC-c\nNQ\nTQA\nMMLU\nGSM8K\nHuman-Eval\nMHA\n71.0\n79.3\n48.2\n75.1\n71.2\n43.0\n12.4\n44.7\n28.0\n4.9\n7.9\nMQA\n70.6' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-930255-616209.jpg'}
文档切分示例:page_content='1.将每个句子编码成embedding向是,并进行均值池化和L2归一化的预处理。\n2.在潜在空间中,\n将所有样本点聚类成几个类别\n3.从这些聚类样本中进行采样,\n找到原始分布中的核心样本,\n4.便用这些检索到的样本来指导微调\nLLIM1\n并进行评估' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型指令对齐训练原理-幕布图片-759487-923925.jpg'}
正在将 samples/test_files/langchain-ChatGLM_closed.jsonl 添加到向量库,共包含217条文档
2024-01-03 21:09:45,493 - utils.py[line:145] - INFO: Note: detected 96 virtual cores but NumExpr set to maximum of 64, check "NUMEXPR_MAX_THREADS" environment variable.
2024-01-03 21:09:45,504 - utils.py[line:148] - INFO: Note: NumExpr detected 96 cores but "NUMEXPR_MAX_THREADS" not set, so enforcing safe limit of 8.
2024-01-03 21:09:45,504 - utils.py[line:160] - INFO: NumExpr defaulting to 8 threads.
Batches: 14%|██████████▎ | 1/7 [00:00<00:03, 1.70it/s]文档切分示例:page_content='WE1\n(b, s, h)\n(b, s)\nWE2\nAllReduce\n(v/N,h)\n知乎@猛猿' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-220157-552735.jpg'}
文档切分示例:page_content='每块GPU上,我们可以先按行求和,得到各自GPU上的GPU\nsum(e)\n将每块GPU上结果做AlIReduce,得到每行最终的sum(e),也就softmax中的分母。此时的通讯\n量为b*S\nloss,按行加总起来以后得到GPU上scalarLoss。\n将GPU上的scalarLoss做AllReduce,得到总Loss。此时通讯量为N\n这样,我们把原先的通讯量从b*S*v大大降至b*S+N。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-838373-426344.jpg'}
Batches: 43%|██████████████████████████████▊ | 3/7 [00:02<00:03, 1.09it/s]文档切分示例:page_content='Method\nWeight\nActivation\nW8A8\nper-tensor\nper-tensor dynamic\nZeroQuant\ngroup-wise\nper-token dynamic\nLLM.int8\nper-channel\nper-tokendynamic+FP16\nOutlierSuppression\nper-tensor\nper-tensorstatic\nSmoothQuant-O1\nper-tensor\nper-token dynamic\nSmoothQuant-O2\nper-tensor\nper-tensor dynamic\nSmoothQuant-O3\nper-tensor\nper-tensorstatic' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型技术栈-算法与原理-幕布图片-454007-940199.jpg'}
文档切分示例:page_content='GELU(\n)=GELU(\nY1\nY2\n)!=GELU(\nY1\n)+GELU(\nY2\nGELU(\nGELU(\nY1\nGELU(\nY2\n知乎\n@猛猿' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-57107-679259.jpg'}
Batches: 100%|████████████████████████████████████████████████████████████████████████| 7/7 [00:05<00:00, 1.36it/s]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-299768-254064.jpg 添加到向量库,共包含0条文档
正在将 samples/llm/大模型推理优化策略.md 添加到向量库,共包含10条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:03<00:00, 3.13s/it]
文档切分示例:page_content='Self-RAG是一个新的框架,通过自我反思令牌\n(Self-reflection tokens)\n来训练和控制任意LM1\n它主要分为三个步骤:检索、生成和批评。\n1.检索:首先,Self-RAG解码检索令牌\n(retrievaltoken)以评估是否需要检索,并控制检索组\n件。如果需要检索,LM将调用外部检索模块查找相关文档。\n2.生成:如果不需要检索,模型会预测下一个输出段。如果需要检索,模型首先生成批评令牌\n(critique token)\n来评估检索到的文档是否相关,然后根据检索到的段落生成后续内容。\n3.批评:如果需要检索,模型进一步评估段落是否支持生成。最后,一个新的批评令牌\n(critique\ntoken)' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-918388-323086.jpg'}
文档切分示例:page_content="MLP层张量模型并行\nforward\nforward\nfoward:\n(b,s,h'/N)\n(b,s,h'/N)*(h'/N,h)\n(b,s,h)\n(b, s, h)\n(b,s,h)*(h,h'/N)\nfoward:\nZ=Z1+Z2\nGELU\nZ1\nXA1\nY1\nY1B1\nDropout\n(b,s,h)\n(b,s,h)\nGELU\nZ2\nXA2" metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg'}
文档切分示例:page_content='Algorithm3StandardAttentionBackwardPass\nRequire:Matrices\nQ,K,V,dO ∈ RNxd,P ∈RNxN in HBM.\n1:LoadP,dObyblocksfrom HBM,\ncomputedV=PTdOeRNxd\nwritedVtoHBM.\n2:\nLoad dO,VbyblocksfromHBM,\ncomputedP=dOVTeRNxN\nwritedPtoHBM\nwhere dSi=Pij(dPij-∑PdP),writedS toHBM.\nLoad dSand K byblocks fromHBM,\ncompute\ndQ=dSK,\nwritedQtoHBM.\n5:' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型推理优化策略-幕布图片-276446-401476.jpg'}
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-17565-176537.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.50it/s]
正在将 samples/llm/大模型指令对齐训练原理.md 添加到向量库,共包含4条文档
Batches: 0%| | 0/1 [00:00<?, ?it/s]文档切分示例:page_content='Vamana的建索引过程比较简单:\n1.初始化一张随机图;\n2.计算起点,和NSG的导航点类似,先求全局质心,然后求全局离质心最近的点作为导航点。和\nNSG的区别在于:NSG的输入已经是一张近邻图了,所以直接在初始近邻图上对质心点做一次\n近似最近邻搜索就可以了。但是Vamana初始化是一张随机近邻图,所以不能在随机图上直接\n做近似搜索,需要全局比对,得到一个导航点,这个点作为后续迭代的起始点,目的是尽量减少\n平均搜索半径;\n3.基于初始化的随机近邻图和步骤2中确定的搜索起点对每个点做ANN,将搜索路径上所有的点' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/llm/img/大模型应用技术原理-幕布图片-793118-735987.jpg'}
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.83it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-20096-279847.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 8.03it/s]
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-95996-523276.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2.27it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-124076-270516.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.09s/it]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-628857-182232.jpg 添加到向量库,共包含1条文档:17, 25.86s/it]
文档切分示例:page_content='title\nfile\nurl\ndetail\nid\n0.0\n效果如何优化\n2023-04-04.00\nhttps://github.com/imClumsyPanda/langchain-ChatGLM/issues/14\n如图所示,将该项目的README.md和该项目结合后,回答效果并不理想,请问可以从哪些方面进行优化\n0\n1.0\n怎么让模型严格根据检索的数据进行回答,减少胡说八道的回答呢\n2023-04-04.00\nhttps://github.com/imClumsyPanda/langchain-ChatGLM/issues/15\n举个例子:\n1' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_open.xlsx'}
Batches: 0%| | 0/1 [00:00<?, ?it/s]文档切分示例:page_content='title\nfile\nurl\ndetail\nid\n0.0\n加油~以及一些建议\n2023-03-31.0002\nhttps://github.com/imClumsyPanda/langchain-ChatGLM/issues/2\n加油,我认为你的方向是对的。\n0\n1.0\n当前的运行环境是什么,windows还是Linux\n2023-04-01.0003\nhttps://github.com/imClumsyPanda/langchain-ChatGLM/issues/3\n当前的运行环境是什么,windows还是Linux,python是什么版本?\n1' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain-ChatGLM_closed.xlsx'}
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.22it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-906937-836104.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 14.06it/s]
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-805089-731888.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.68it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-380552-579242.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.43it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-618350-869132.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.79it/s]
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-349153-657791.jpg 添加到向量库,共包含2条文档
Batches: 0%| | 0/1 [00:00<?, ?it/s]文档切分示例:page_content='ChatGPT是OpenAI开发的一个大型语言模型,可以提供各种主题的信息,\n# 如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南\n## 介绍\n我很高兴欢迎您阅读我的最新书籍《The Art of Asking ChatGPT for High-Quality Answers: A complete Guide to Prompt Engineering Techniques》。本书是一本全面指南,介绍了各种提示技术,用于从ChatGPT中生成高质量的答案。\n我们将探讨如何使用不同的提示工程技术来实现不同的目标。ChatGPT是一款最先进的语言模型,能够生成类似人类的文本。然而,理解如何正确地向ChatGPT提问以获得我们所需的高质量输出非常重要。而这正是本书的目的。' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/test.txt'}
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.63it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-42284-124759.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 78.55it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-590671-36787.jpg 添加到向量库,共包含4条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 49.73it/s]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-729151-372321.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 93.21it/s]
正在将 samples/llm/大模型技术栈-算法与原理.md 添加到向量库,共包含30条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.61it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-36114-765327.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 61.61it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-923924-83386.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 52.81it/s]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-81470-404273.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 74.82it/s]
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-350029-666381.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 20.28it/s]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-19929-302935.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 63.21it/s]
正在将 samples/llm/img/大模型应用技术原理-幕布图片-580318-260070.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 52.60it/s]
RapidOCRPDFLoader context page index: 7: 100%|████████████████████████████████████████| 8/8 [02:12<00:00, 16.61s/it]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-789705-122117.jpg 添加到向量库,共包含1条文档12<00:18, 18.46s/it]
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.54it/s]
正在将 samples/llm/img/大模型应用技术原理-幕布图片-108319-429731.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 18.07it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-699343-219844.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 5.93it/s]
正在将 samples/llm/大模型应用技术原理.md 添加到向量库,共包含7条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 6.60it/s]
正在将 samples/llm/分布式训练技术原理.md 添加到向量库,共包含11条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.33it/s]
正在将 samples/llm/大模型技术栈-实战与应用.md 添加到向量库,共包含2条文档
文档切分示例:page_content='See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/372669736\nCreating Large Language Model Applications Utilizing LangChain: A Primer on\nDeveloping LLM Apps Fast\nArticle\xa0\xa0in\xa0\xa0International Conference on Applied Engineering and Natural Sciences · July 2023\nDOI: 10.59287/icaens.1127\nCITATIONS\n0\nREADS\n47\n2 authors:\nSome of the authors of this publication are also working on these related projects:\nTHALIA: Test Harness for the Assessment of Legacy Information Integration Approaches View project\nAnalysis of Feroresonance with Signal Processing Technique View project\nOguzhan Topsakal' metadata={'source': '/workspace/why/cpx/code/Langchain-Chat/knowledge_base/samples/content/test_files/langchain.pdf'}
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 44.69it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-930255-616209.jpg 添加到向量库,共包含3条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 17.88it/s]
正在将 samples/llm/img/大模型指令对齐训练原理-幕布图片-759487-923925.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 25.16it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-220157-552735.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 18.89it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-838373-426344.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 32.82it/s]
正在将 samples/llm/img/大模型技术栈-算法与原理-幕布图片-454007-940199.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 80.04it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-57107-679259.jpg 添加到向量库,共包含1条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 76.83it/s]
正在将 samples/llm/img/大模型应用技术原理-幕布图片-918388-323086.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 70.71it/s]
正在将 samples/llm/img/分布式训练技术原理-幕布图片-392521-261326.jpg 添加到向量库,共包含3条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 93.17it/s]
正在将 samples/llm/img/大模型推理优化策略-幕布图片-276446-401476.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 78.06it/s]
正在将 samples/llm/img/大模型应用技术原理-幕布图片-793118-735987.jpg 添加到向量库,共包含2条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 52.95it/s]
正在将 samples/test_files/langchain-ChatGLM_open.xlsx 添加到向量库,共包含164条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 6/6 [00:00<00:00, 7.55it/s]
正在将 samples/test_files/langchain-ChatGLM_closed.xlsx 添加到向量库,共包含86条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 6.94it/s]
正在将 samples/test_files/test.txt 添加到向量库,共包含59条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.95it/s]
正在将 samples/test_files/langchain.pdf 添加到向量库,共包含52条文档
Batches: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 7.46it/s]
2024-01-03 21:10:08,996 - faiss_cache.py[line:38] - INFO: 已将向量库 ('samples', 'm3e-base') 保存到磁盘
总计用时: 0:02:36.170183
1.4.2、启动 WebUI
一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码:
$ CUDA_VISIBLE_DEVICES=7 python startup.py -a
并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或 –all-webui), --all-api, --llm-api, -c (或 –controller), --openai-api, -m (或 –model-worker), --api, --webui,其中:
–all-webui为一键启动 WebUI 所有依赖服务;–all-api为一键启动 API 所有依赖服务;–llm-api为一键启动 Fastchat 所有依赖的 LLM 服务;–openai-api为仅启动 FastChat 的 controller 和 openai-api-server 服务;其他为单独服务启动选项;
返回的结果:
==============================Langchain-Chatchat Configuration==============================
操作系统:Linux-5.15.0-88-generic-x86_64-with-glibc2.31.
python版本:3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0]
项目版本:v0.2.9
langchain版本:0.0.352. fastchat版本:0.2.34
当前使用的分词器:ChineseRecursiveTextSplitter
当前启动的LLM模型:['chatglm2-6b'] @ cuda
{'device': 'cuda',
'host': '0.0.0.0',
'infer_turbo': False,
'model_path': '/workspace/why/cpx/code/Langchain-Chat/model/chatglm2-6b',
'model_path_exists': True,
'port': 20002}
当前Embbedings模型: m3e-base @ cuda
==============================Langchain-Chatchat Configuration==============================
2024-01-03 21:12:05,883 - startup.py[line:651] - INFO: 正在启动服务:
2024-01-03 21:12:05,883 - startup.py[line:652] - INFO: 如需查看 llm_api 日志,请前往 /workspace/why/cpx/code/Langchain-Chat/logs
2024-01-03 21:12:15 | ERROR | stderr | INFO: Started server process [34475]
2024-01-03 21:12:15 | ERROR | stderr | INFO: Waiting for application startup.
2024-01-03 21:12:15 | ERROR | stderr | INFO: Application startup complete.
2024-01-03 21:12:15 | ERROR | stderr | INFO: Uvicorn running on http://0.0.0.0:20000 (Press CTRL+C to quit)
2024-01-03 21:12:16 | INFO | model_worker | Loading the model ['chatglm2-6b'] on worker b04125f3 ...
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
Loading checkpoint shards: 14%|███████▋ | 1/7 [00:01<00:09, 1.59s/it]
Loading checkpoint shards: 29%|███████████████▍ | 2/7 [00:03<00:08, 1.67s/it]
Loading checkpoint shards: 43%|███████████████████████▏ | 3/7 [00:04<00:06, 1.58s/it]
Loading checkpoint shards: 57%|██████████████████████████████▊ | 4/7 [00:06<00:04, 1.51s/it]
Loading checkpoint shards: 71%|██████████████████████████████████████▌ | 5/7 [00:07<00:03, 1.52s/it]
Loading checkpoint shards: 86%|██████████████████████████████████████████████▎ | 6/7 [00:09<00:01, 1.57s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████| 7/7 [00:10<00:00, 1.47s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████| 7/7 [00:10<00:00, 1.52s/it]
2024-01-03 21:12:29 | ERROR | stderr |
2024-01-03 21:12:42 | INFO | model_worker | Register to controller
INFO: Started server process [35662]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:7861 (Press CTRL+C to quit)
==============================Langchain-Chatchat Configuration==============================
操作系统:Linux-5.15.0-88-generic-x86_64-with-glibc2.31.
python版本:3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0]
项目版本:v0.2.9
langchain版本:0.0.352. fastchat版本:0.2.34
当前使用的分词器:ChineseRecursiveTextSplitter
当前启动的LLM模型:['chatglm2-6b'] @ cuda
{'device': 'cuda',
'host': '0.0.0.0',
'infer_turbo': False,
'model_path': '/workspace/why/cpx/code/Langchain-Chat/model/chatglm2-6b',
'model_path_exists': True,
'port': 20002}
当前Embbedings模型: m3e-base @ cuda
服务端运行信息:
OpenAI API Server: http://127.0.0.1:20000/v1
Chatchat API Server: http://127.0.0.1:7861
Chatchat WEBUI Server: http://0.0.0.0:8501
==============================Langchain-Chatchat Configuration==============================
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:8501
访问 127.0.0.1:8501,后台会输出信息:
2024-01-03 21:17:26,661 - _client.py[line:1013] - INFO: HTTP Request: POST http://127.0.0.1:20001/list_models "HTTP/1.1 200 OK"
INFO: 127.0.0.1:56380 - "POST /llm_model/list_running_models HTTP/1.1" 200 OK
2024-01-03 21:17:26,665 - _client.py[line:1013] - INFO: HTTP Request: POST http://127.0.0.1:7861/llm_model/list_running_models "HTTP/1.1 200 OK"
2024-01-03 21:17:26,823 - _client.py[line:1013] - INFO: HTTP Request: POST http://127.0.0.1:20001/list_models "HTTP/1.1 200 OK"
INFO: 127.0.0.1:56380 - "POST /llm_model/list_running_models HTTP/1.1" 200 OK
2024-01-03 21:17:26,826 - _client.py[line:1013] - INFO: HTTP Request: POST http://127.0.0.1:7861/llm_model/list_running_models "HTTP/1.1 200 OK"
INFO: 127.0.0.1:56380 - "POST /llm_model/list_config_models HTTP/1.1" 200 OK
2024-01-03 21:17:26,846 - _client.py[line:1013] - INFO: HTTP Request: POST http://127.0.0.1:7861/llm_model/list_config_models "HTTP/1.1 200 OK"
使用 duckduckgo-search 出现错误:
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", line 426, in run_asgi
result = await app( # type: ignore[func-returns-value]
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/uvicorn/middleware/proxy_headers.py", line 84, in __call__
return await self.app(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/fastapi/applications.py", line 1054, in __call__
await super().__call__(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/applications.py", line 122, in __call__
await self.middleware_stack(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/middleware/errors.py", line 184, in __call__
raise exc
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/middleware/errors.py", line 162, in __call__
await self.app(scope, receive, _send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/middleware/cors.py", line 83, in __call__
await self.app(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 79, in __call__
raise exc
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 68, in __call__
await self.app(scope, receive, sender)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/routing.py", line 718, in __call__
await route.handle(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/routing.py", line 276, in handle
await self.app(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/routing.py", line 69, in app
await response(scope, receive, send)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/sse_starlette/sse.py", line 255, in __call__
async with anyio.create_task_group() as task_group:
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 597, in __aexit__
raise exceptions[0]
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/sse_starlette/sse.py", line 258, in wrap
await func()
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/sse_starlette/sse.py", line 245, in stream_response
async for data in self.body_iterator:
File "/workspace/why/cpx/code/Langchain-Chat/server/chat/search_engine_chat.py", line 162, in search_engine_chat_iterator
docs = await lookup_search_engine(query, search_engine_name, top_k, split_result=split_result)
File "/workspace/why/cpx/code/Langchain-Chat/server/chat/search_engine_chat.py", line 112, in lookup_search_engine
results = await run_in_threadpool(search_engine, query, result_len=top_k, split_result=split_result)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/starlette/concurrency.py", line 41, in run_in_threadpool
return await anyio.to_thread.run_sync(func, *args)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/anyio/to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 807, in run
result = context.run(func, *args)
File "/workspace/why/cpx/code/Langchain-Chat/server/chat/search_engine_chat.py", line 37, in duckduckgo_search
return search.results(text, result_len)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/langchain_community/utilities/duckduckgo_search.py", line 111, in results
for r in self._ddgs_text(query, max_results=max_results)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/langchain_community/utilities/duckduckgo_search.py", line 57, in _ddgs_text
return [r for r in ddgs_gen]
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/langchain_community/utilities/duckduckgo_search.py", line 57, in <listcomp>
return [r for r in ddgs_gen]
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/duckduckgo_search/duckduckgo_search.py", line 91, in text
for i, result in enumerate(results, start=1):
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/duckduckgo_search/duckduckgo_search.py", line 119, in _text_api
vqd = self._get_vqd(keywords)
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/duckduckgo_search/duckduckgo_search.py", line 54, in _get_vqd
resp = self._get_url("POST", "https://duckduckgo.com", data={"q": keywords})
File "/opt/conda/envs/Chatchat/lib/python3.10/site-packages/duckduckgo_search/duckduckgo_search.py", line 50, in _get_url
raise DuckDuckGoSearchException(f"_get_url() {url} {type(ex).__name__}: {ex}")
duckduckgo_search.exceptions.DuckDuckGoSearchException: _get_url() https://duckduckgo.com RequestsError: Failed to perform, ErrCode: 35, Reason: 'BoringSSL SSL_connect: Connection reset by peer in connection to duckduckgo.com:443 '. This may be a libcurl error, See https://curl.se/libcurl/c/libcurl-errors.html first for more details.
2024-01-03 21:32:16,157 - utils.py[line:192] - ERROR: RemoteProtocolError: API通信遇到错误:peer closed connection without sending complete message body (incomplete chunked read)
排除了 duckduckgo-search 依赖未安装的情况,应该是代理的问题。根据 一只叛逆的鸭子——DuckDuckGo 简介 的说法,DuckDuckGo 目前无法在国内直接访问(后面自己亲测, 确实无法访问)。
在 startup.py 中添加代理:
# 添加代理
try:
os.environ['http_proxy'] = 'http://127.0.0.1:7890'
os.environ['https_proxy'] = 'http://127.0.0.1:7890'
except:
pass
重新启动:
$ CUDA_VISIBLE_DEVICES=7 python startup.py -a
发现可以通过 duckduckgo 进行正常的问答。
1.5、前端页面展示
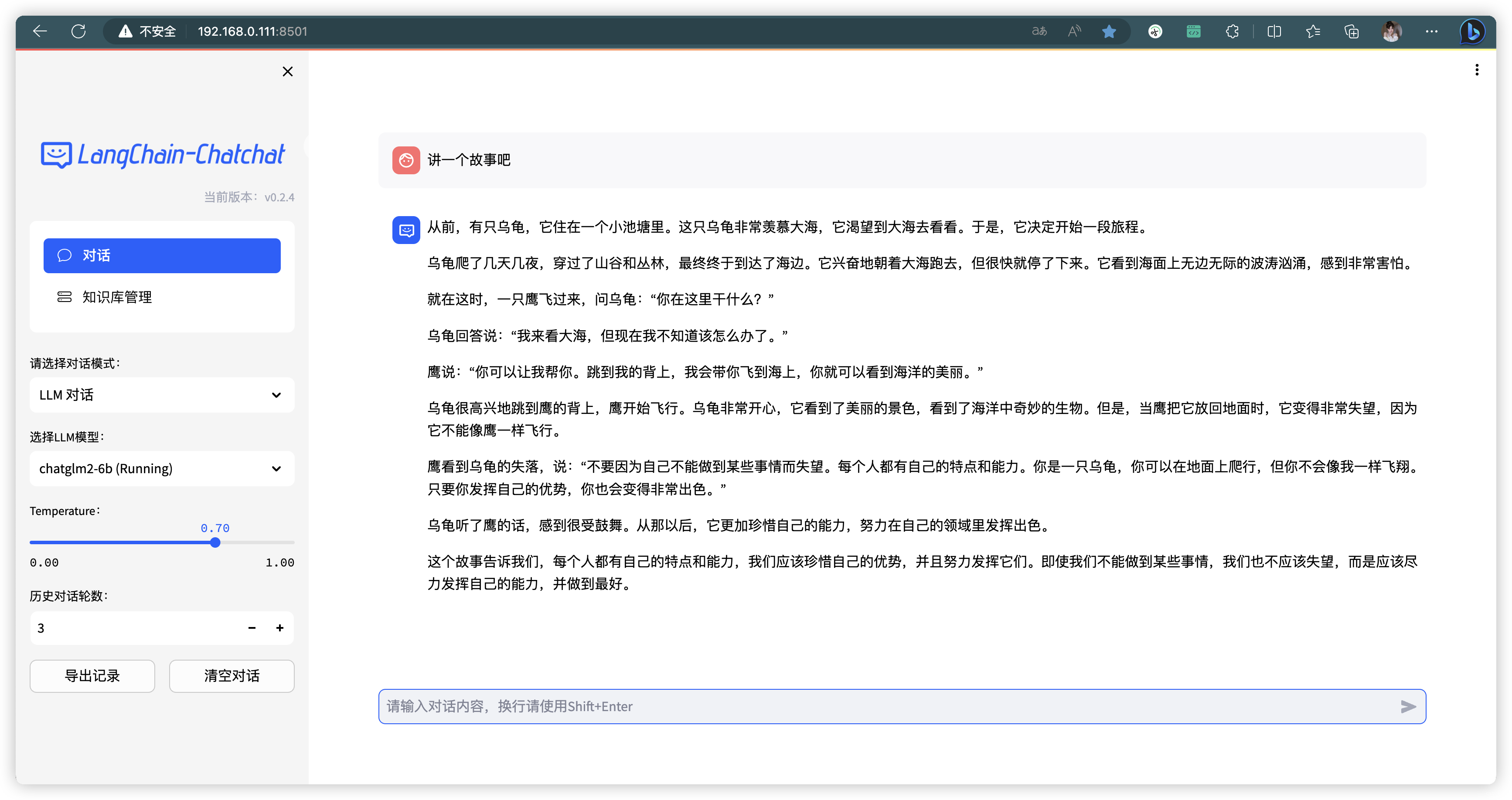
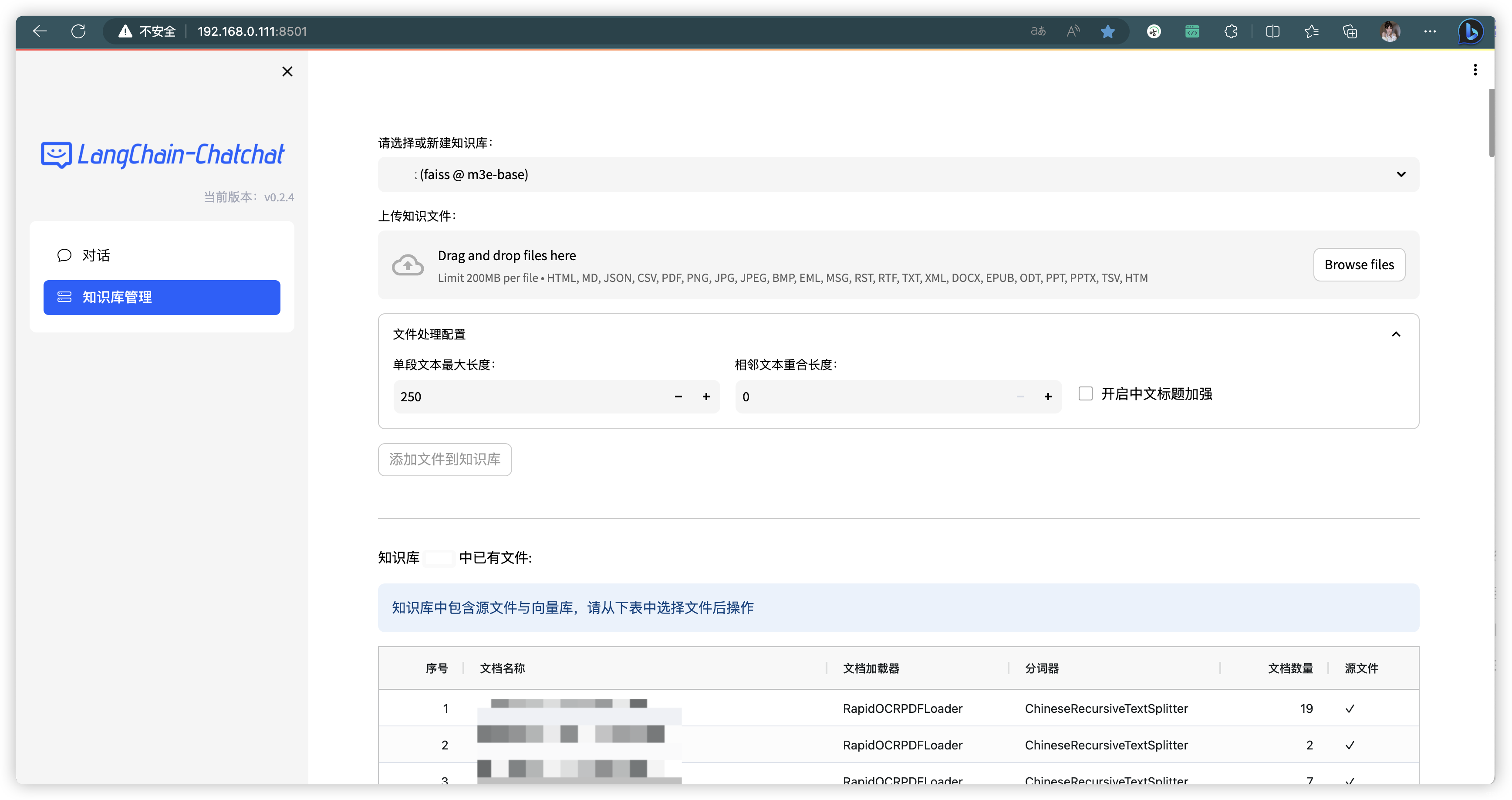
2、深入
TODO
调用 FastChat
参考:
- Github:fastchat 调用实现教程
LangChain
AutoGPT -> LangChain
Compomenets
Models
- Prompts Chain-of-Thought Reasoning(ReAct)
- Thought:
- Action:
- Observation:
- Parsers
- output parser(str -> json)
- Memory
- ConversationBufferMemory -> 直接将对话 history 保存在缓冲区(内存)中,每次对话的 prompt 都会携带上之前的 history【程序退出,history 也会相应的被清除掉】-> 随着对话轮次的增加,所需要携带的 history 也会不断增加,比较浪费 token
- ConversationBufferWindowMemory -> 只保存一定轮次(window 数)的对话 history ->
- ConversationTokenBufferMemory -> 只保存一定 tokens 数量的 history(限制包括 input text + history 的 prompt 总 token 的数量)
ConversationSummaryBufferMemory -> 会将你的 history 进行 summary(使用 LLM),然后在进行存储,以便减少长文本对 token 的消耗 -> 设置一个最长的 token 数,查过这个 token 数的部分将会进行 summary
- vector data memoty
- entity memories
- conventional database(MySQL、Redis)
- Chains
- LLMChain
- Sequential Chain:combine multiple chains (chain_1 -> chain_2 -> finished)
- SimpleSequentialChain:Single input / output
- SequentialChain:multiple inputs / outputs
- Router Chain:根据一定的条件,选择某一个 chain 继续执行下去(例如,在一个包含有物理、生物以及数学等不同科目的 prompt 中,Router Chain 能够根据不同的输入选择对应科目的 prompt,从而准确地回答不同科目的问题)
- MultiPromptChain
- LLMRouterChain
- RouterOutputParser 运行:chain.run(some variables in prompt)
Question Answering over Documents:【Embeddings + Vector Database】 针对文件库、文件集进行索引(最初没有在 LLM 中被训练的数据)
- RetrievalQA
- DocArrayInMemorySearch:内部的一个向量数据库,不需要连接任务的外部数据库
- VectorStoreIndexCreator 1)Stuff Method:将所有的数据输入到 prompt 中【最简单的方式】 2)Map_reduce:将每个文档都视为一个独立的文档,使用独立的 LLM 处理每一个文档【可并行,但需要多次调用 LLM】 3)Refine:第一个文档在调用完 LLM 之后,其结果会作为第二个文档的输入【累加迭代】【相比 Map_reduce 需要更多的时间,并且不能并行,因为后一个的输入依赖于上一个输出;需要与 Map_reduce 相同的 LLM 调用次数】 4)Map_rerank:独立调用 LLM 对每一个文档进行提取,并对其进行打分排序(Rank)
评估(Evaluation) 如何评估一个基于 LLM 的应用程序?
- 使用 QAGenerateChain 调用 LLM 来自动生成一些 QA 问题,从而评估创建的这个 QA Chain。
- LLM 生成 Question 和 Answer,作为 Ground Truth
- 使用 LangChain 调用之后生成的 Predicted Answer
- GT Answer 与 Predicted Answer 可能长得完全不一样,该如何判断这两个 Answer 属于同一个答案 -> 使用 LLM 判断这两个 Answer 是否属于同一个 Answer(Correct or Not Correct)
- 使用 LangChain.debug = True,来打开 LangChain 的调试模式。从而可以看到每一个 Chain 的输入、输出结果,从而更有利于进行调试
LangChainPlus 可视化平台
- Agents:代理人 agent = initialize_agent() tools = load_tools([‘llm-math’, ‘wikipedia’], llm=llm) agent = create_python_agent() # 执行 Python 代码 自定义一个 tool: @tool def time(text: str) -> str: return str(date.today())
ChatGLM + LangChain 实战:
网络结果 + 本地知识库 -> 技术上可行 -> 关键是 Prompt 长度的问题 -> Token 长度
LangChain-Chatchat v0.2.9
FastChat 加载大多数的 LLM 模型 https://github.com/lm-sys/FastChat/blob/main/fastchat/model/model_adapter.py#L185
Find the start time and end time of the query below from the video.
| ps -aux | grep git |
MemGPT: Towards LLMs as Operating Systems
参考
Langchain-Chatchat 官方:
Github:
视频讲解:
CSDN:
博客:
少数派:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2024/01/04/langchain-chatchat/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)