GPT-2 论文
Language Model are Unsupervised Multitask learners(LM 是一个多任务学习器)
给定一个句子,Today is a good day,and the captial of China is Beijing。
当我们去预测
Beijing这个词的时候,可以看作是一个 知识获取 的任务当我们去预测
day这个词的时候,可以看作是另外一种任务(预测名词的任务)当我们去预测
good这个词的时候,可以看作是一种 情绪识别 的任务
因此,虽然同样都是预测下一个词,但是可以对应不同的任务。也就是说,通过预测下一个词,(无监督)训练的 LM 实际上学习到了很多的任务,而非(有监督)一种特定的任务。这也对应了论文标题。
使用 BPE tokenizer
与 GPT-1 相比,使用了 Pre-Norm
优化目标
语言模型的优化目标是最大化下面的似然值:
\[p(x)=\prod_{i=1}^np(s_n|s_1,...,s_{n-1})\]即:
\[L(\mathcal{S})=\sum_i\log P(s_i|s_{i-n},\ldots,s_{i-1};\Theta)\]其中,\(n\) 是滑动窗口(上下文)大小;\(S = \{s_1, ..., s_n\}\);\(\Theta\) 是模型参数;
nanoGPT

权重共享(weight sharing / tying)
在 nanoGPT 的代码中,使用到了 weight tying 这个 trick。即:将 GPT-2 模型最后的 Linear 层(n_embd to vocab_size)的 权重共享 给 wte 层(vocab_size to n_embd)。
具体的代码位置见这里。
import torch
import torch.nn as nn
vocab_size = 50304
n_embd = 768
wte = nn.Embedding(vocab_size, n_embd)
lm_head = nn.Linear(n_embd, vocab_size, bias=False)
print(wte.weight.shape) # (vocab_size, n_embd) -> (50304, 768)
print(lm_head.weight.shape) # (vocab_size, n_embd) -> (50304, 768)
wte.weight = lm_head.weight # 权重共享
根据 nanoGPT 中的说明,这个 trick 最初是在论文《Using the Output Embedding to Improve Language Models》中提出的。而在 paperwithcode 中,也被称为 weight tying(权重绑定)。
这个 trick 在后来的一些 LLM 模型中也有使用,例如:
- PaLM 中的 Shared Input-Output Embeddings
参考:【论文阅读笔记】Using the Output Embedding to Improve Language Model
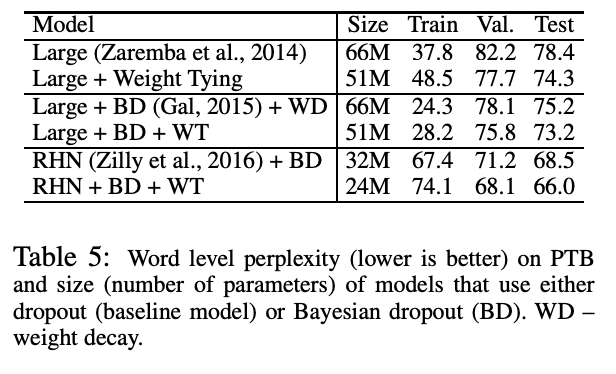
设 Word2Vec 等词向量训练模型的输入词向量为 \(U\),输出词向量为 \(V\),通常模型训练完成后,只是用 \(U\) 作为预训练词向量给其他上游模型使用,\(V\) 通常忽略,本文探讨了 \(U\) 和 \(V\) 使用的效果,以及联合使用 \(U\) 和 \(V\) 的效果,得出以下结论:
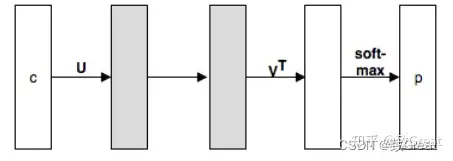
在 Word2Vec Skipgram 模型中,输出词向量与输入词向量的效果相比稍差。
在基于 RNN 的语言模型中,输入词向量比输入词向量想过更好。
通过将这两种嵌入结合在一起,即强制 \(U = V\),联合嵌入的效果更类似于输出嵌入,而不是未绑定模型的输入嵌入。
将输入和输出嵌入绑在一起,可以降低各种语言模型的困惑度。
当不使用 dropout 时,建议在 \(V\) 之前添加一个额外的投影 \(P\),并对 \(P\) 应用正则化。
神经翻译模型中的权值绑定可以在不影响性能的前提下,将它们的大小 (参数数量)减少 到原来大小的一半以下。
为什么 nn.Linear() 权重的形状是 (out_dim, in_dim)
为什么 nn.Linear() 权重的形状是 (out_dim, in_dim),而不是 (in_dim, out_dim)?
这里给出简洁的回答:
正常的计算过程:\(Y = XW + B\)
PyTorch 中的计算过程:\(Y = XW^T + B = WX + B\)
由于 PyTorch 中对权重 \(W\) 进行了 转置 操作,此时权重 \(W\) 的形状就变为了 (out_dim, in_dim)
具体的代码分析,可以参考 pytorch 中 Linear 类中 weight 的形状问题源码探讨
TODO 代码
model.py train.py sample.py(inference)
【model.py】 block_size:上下文信息的长度 / 大小,只有在这个范围内的文本序列才会参与 Self-Attention 的计算
wte:word table embedding
wpe:word position embedding
configure_optimizers() 函数: 任何二维参数都将进行权重衰减,否则不会 decay_params:维度 shape 大于 2个,例如(B,T,n_dim) nodecay_params:维度 shape 小于 2
self.transformer.wte.weight = self.lm_head.weight (vocab_size, n_dim) (n_dim, vocab_size)
top-k mask:只对前 top-k 个 token 进行处理(计算 softmax,然后降序),对 top-k 之后的 token mask 掉(负无穷大)【321 行】
然后根据 softmax 计算出来的 logits 值,采样出一个对应的 index(下一个预测词在词典中的 index 值)
temperature 越小,分布越高瘦,确定性越大;temperature 越大,分布越矮胖,确定性越小【318 行】
前向
参考 nanoGPT 的 model.py
训练
参考 nanoGPT 的 train.py
数据集
输入 \(X\):block_size 大小的 token 序列
目标 \(Y\):\(X\) 后移一位
# poor man's data loader
data_dir = os.path.join('data', dataset)
train_data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')
val_data = np.memmap(os.path.join(data_dir, 'val.bin'), dtype=np.uint16, mode='r')
def get_batch(split):
data = train_data if split == 'train' else val_data
# 从 [0, data_len - block_size) 的任意一个位置作为起点
# 生成 batch_size 个起点
ix = torch.randint(len(data) - block_size, (batch_size,))
# 输入 [i,i+block_size) 位置的 token
x = torch.stack([torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix])
# 目标 [i+1,i+block_size] 位置的 token
# 输入后移一个 token
y = torch.stack([torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix])
if device_type == 'cuda':
# pin arrays x,y, which allows us to move them to GPU asynchronously (non_blocking=True)
x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)
else:
x, y = x.to(device), y.to(device)
return x, y
训练
config = GPTConfig()
model = GPT(config)
logits, loss = model(x, target=y)
推理
参考 nanoGPT 的 sample.py
小结
自己在 Colab 上面关于 nanoGPT 的代码:nanoGPT.ipynb
参考
bilibili:
deep_thoughts:72、爆火的 GPT-2 论文讲解
deep_thoughts:73、爆火必看的 nano-GPT2 Pytorch 经典代码逐行讲解
Github:nanoGPT
论文:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/12/24/gpt-2/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)