现有的 LLM 大多采用 Decoder-Only 架构,这些 LLM 使用到了 Casual Mask(也成为 Casual Attention)。正是由于 Casual Mask,我们可以 通过将注意力中的 K 和 V 进行保存,以空间换时间,从而加快 LLM 的推理过程。
背景
生成式 LLM 的推理过程
一个典型的大模型生成式推断包含了两个阶段:
预填充(Prefill)阶段:输入一个 prompt 序列,为每个 transformer 层生成 key cache 和 value cache(KV cache)。
此时,KV Cache 是空的
存在大量的 gemm 操作,推理速度慢
一串输入生成一个 token
解码(Generate)阶段:使用并更新 KV cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词。这样不断反复,直到遇到终止符才停止(或者超过最大的生成长度)。
gemm 变为 gemv 操作,推理速度相对较快
一个 token 生成一个 token
KV Cache
示意图
KV Cache 的示意图如下所示:

图片来源:大模型推理加速:看图学 KV Cache
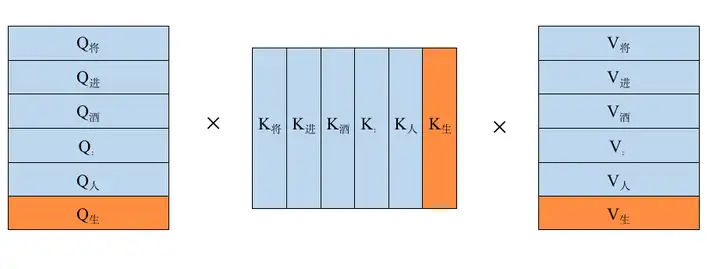
图片来源:Llama 2 详解
自己手画的 KV Cahce 示意图如下图所示,其中,橙色部分表示新生成的 token,作为输入参与下一个 token 的生成。
.png)
KV Cache 的出发点就在这里,缓存当前轮可重复利用的计算结果(避免重复的计算),下一轮计算时直接读取缓存结果,就是这么简单,不存在什么 Cache miss 问题。
这让我想到了计算机经典算法中的 DP(动态规划),也是类似的思想,以时间换空间。
具体的计算过程可以参见:大模型推理加速:看图学 KV Cache
显存占用
当 sequence 特别长的时候,KV Cache 其实还是个 Memory 刺客。
在推理时新增了 past_key_values 参数,该参数就会以追加方式保存每一轮的 K、V 值。kvcache 变量内容为 ((k,v), (k,v), ..., (k,v)),即有 \(n_{\text{layer}}\) 个 K、V 组成的一个元组,其中 k 和 v 的维度均为 \([b, n_{\text{head}}, s, \text{head}_{\text{dims}}]\)。
因此,可以计算出每轮推理(每生成一个新的 token)对应的 Cache 的数据量为 \(2 * b * s^\prime * \text{head}_{\text{dims}}\)。其中,\(s^\prime\) 表示当前轮次值。
比如 batch_size=32, head=32, layer=32, dim_size=4096, seq_length=2048, float32 类型(4 字节),则需要占用的显存为 \(2 * 32 * 4096 * 2048 * 32 * 4 / 1024/1024/1024 /1024 = 64G\)。
代码
目前各大深度学习框架都实现了 KV Cache。例如,HuggingFace 的 transformers 库中的 generate 函数已经将其封装,用户不需要手动传入 past_key_values 并默认开启(config.json 文件中 use_cache=True)。
下面以 HuggingFace Transformers 的 GPT-2 为例(具体代码链接)。
推理输出的 token 直接作为下一轮的输入(Query),不再拼接,因为上文信息已经在 KV Cache 中。
query = self._split_heads(query, self.num_heads, self.head_dim) # Q
key = self._split_heads(key, self.num_heads, self.head_dim) # K
value = self._split_heads(value, self.num_heads, self.head_dim) # V
if layer_past is not None: # 当输出第一个 token 后,layer_past 就是非 None 了
past_key, past_value = layer_past # 取出之前计算好的 key, value
key = torch.cat((past_key, key), dim=-2) # past_key 与当前 token 对应的 key 拼接
value = torch.cat((past_value, value), dim=-2) # past_value 与当前 token 对应的 value 拼接
if use_cache is True:
present = (key, value)
else:
present = None
结合 Llama 2 的代码来看看他们的具体实现(为了篇幅做了一些简化)。
代码比较长,这里暂时不展开~
小实战
我们通常认知的 GPT 推理过程:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, _ = model(in_tokens)
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = torch.cat((in_tokens, out_token), 0)
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text = tokenizer.decode(in_tokens)
print(f' Input: {in_text}')
print(f'Output: {out_text}')
输出:
step 0 input: Lionel Messi is a player
step 1 input: Lionel Messi is a player who
step 2 input: Lionel Messi is a player who has
step 3 input: Lionel Messi is a player who has been
step 4 input: Lionel Messi is a player who has been a
step 5 input: Lionel Messi is a player who has been a key
step 6 input: Lionel Messi is a player who has been a key part
step 7 input: Lionel Messi is a player who has been a key part of
step 8 input: Lionel Messi is a player who has been a key part of the
step 9 input: Lionel Messi is a player who has been a key part of the team
step 10 input: Lionel Messi is a player who has been a key part of the team's
step 11 input: Lionel Messi is a player who has been a key part of the team's success
step 12 input: Lionel Messi is a player who has been a key part of the team's success.
step 13 input: Lionel Messi is a player who has been a key part of the team's success.
Input: Lionel Messi is a
Output: Lionel Messi is a player who has been a key part of the team's success.
使用了 KV Cache 之后的推理过程:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
kvcache = None
out_text = in_text
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, kvcache = model(in_tokens, past_key_values=kvcache) # 增加了一个 past_key_values 的参数
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = out_token # 输出 token 直接作为下一轮的输入,不再拼接
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text += text
print(f' Input: {in_text}')
print(f'Output: {out_text}')
小结
请尝试回答如下问题:
KV Cache 节省了 Self Attention 层中哪部分的计算?
KV Cache 对 MLP 层的计算量有影响吗?
KV Cache 对 block 间的数据传输量有影响吗?
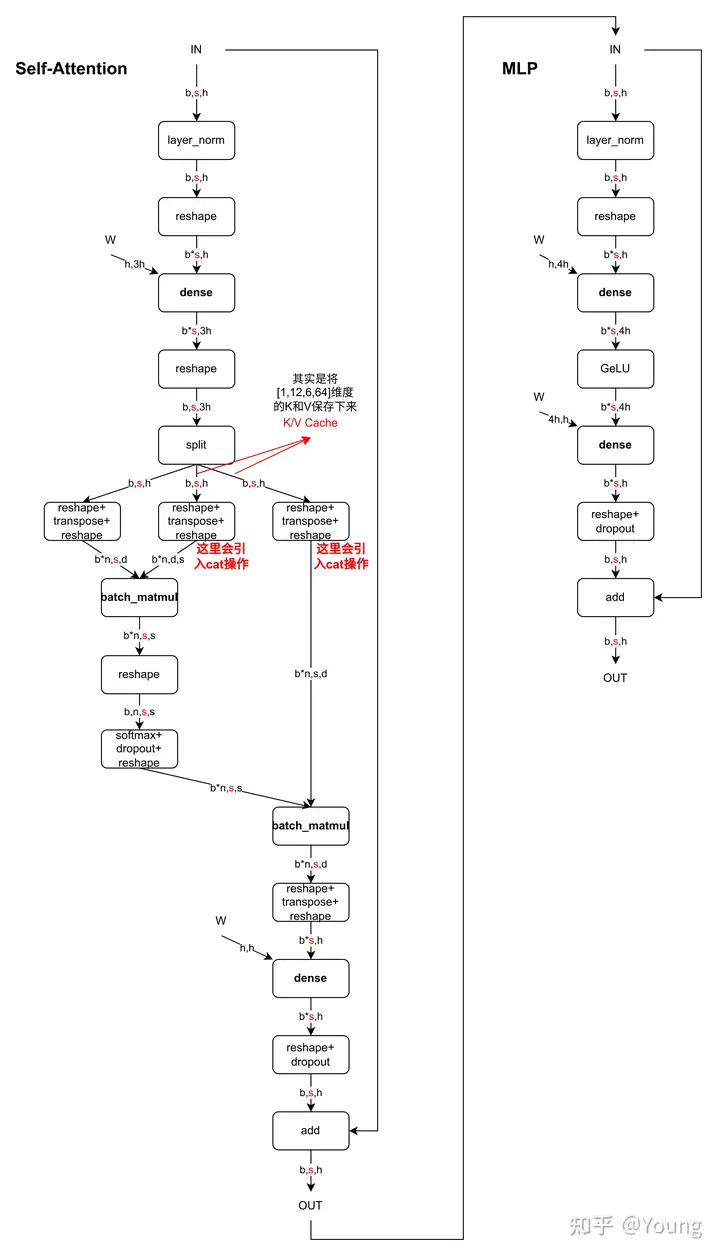
下图是一个 Decoder Block(仅以 MHA 为例),含有 Self-Attention 和 MLP,标红部分为 KV Cache 影响到的内容,即 KV Cache 开启后,标红的序列长度变为 1(此时只需要使用当前的 Query 即可)。当 batch_size = 1 时,Self-Attention 中的 2 个 dense 全都变为 gemv 操作,MLP 中的 dense 也全都变为 gemv 操作。看懂这个图就可以答对上面的 3 个问题啦。
图中数据维度相关字母的含义:
\(b\): batchsize
\(s\): sequence length,序列长度
\(h\): hidden_state 维度 = n * d
\(n\): head 个数
\(d\): head 维度
MQA & GQA
但你转念一想,可是 K、V 真的能缓存的了吗?
我们来算笔账,以 Llama 7B 模型为例,hidden_size 为 4096,也就说每个 K、V 有 4096 个数据,假设是半精度浮点数据 float16,一个 Transformer Block 中就有 \(4096* 2 *2 = 16KB\) 的单序列 K、V 缓存空间,而 Llama 2 一共 32 个 Transformer Block,所以单序列整个模型需要 \(16 * 32 = 512KB\) 的缓存空间。
那多序列呢?如果此时句子长度为 1024,那是不是就得 \(1024 * 512KB = 512MB\) 的缓存空间了。而现在英伟达最好的卡 H100 的 SRAM 缓存大概是 50MB,而 A100 则是 40MB. 而 7B 模型都这样,175B 模型就更不用说了。
谈到 SRAM 顺便多提一句,Flash Attention 就是通过一定的手段实现 Attention 在 SRAM 中进行计算~

既然 SRAM 放不下,我们放到 DRAM(GPU 显存)行不行呢?答案是可以,但要牺牲性能。如果学过计算机组成原理,我们会知道全局内存(GPU 显存)的读写速度要要远低于共享内存和寄存器。因此,便会导致一个问题: Memory Wall(内存墙)。所谓内存墙简单点说就是你处理器 ALU 计算太快,但是你内存读写速度太慢跟不上,这就会导致 ALU 计算完之后在那等着你数据搬运过来,进而影响性能。
也就是会出现 memory-bound

那么该如何解决呢?答案无非是从硬件层面和软件层面来说:
从硬件层面,可以使用 HBM(高速带宽内存)提高读取速度,或者抛弃冯诺依曼架构,改变计算单元从内存读数据的方式,不再以计算单元为中心,而以存储为中心,做成计算和存储一体的 “存内计算”,比如”忆阻器”。
从软件层面就是优化算法,由此便引入 Llama 2 所使用的 GQA (Group Query Attention)
首先,我们给出 MHA(Multi-Head Attention)、(Multi Query Attention)与 GQA(Group Query Attention)的示意图:
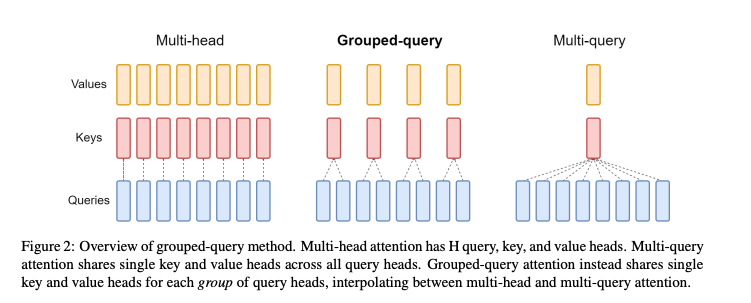
图片来源于 GQA 论文
1)MQA(Multi Query Attention)
MQA 提出时间挺早的,是 Noam Shazeer 这位谷歌老哥 2019 年提出的。而 Noam 也是 Transformer 结构提出者之一,现在也就理所当然地早就不在 Google,是 Character.ai 的合伙人。

这位老哥对 Transformer 提出过好几种结构改进,比如 Talking-Heads、GLU 激活、还有这里谈的 MQA,他这些论文都简单粗暴,上方法看效果,不玩虚的,主打一个好用。MQA 提出时,并没获得太大关注,而且作者可能也没太当一回事,论文从头到脚都能看到两个字,随意。
最近才越来越多被提到,包括 Falcon,Star Coder,还有最近的 Llama 2 都有用到。
原始的 MHA(Multi-Head Attention),Q、K、V 三部分有相同数量的头,且一一对应。每次做 Attention,head1 的 Q、K、V 就做好自己运算就可以,输出时各个头加起来就行。
而 MQA 则是,让 Q 仍然保持原来的头数,但 K 和 V 共享一个头,相当于 所有的 Q 头共享一组 K 和 V 头,所以叫做 Multi-Query 了。
实现改变了会不会影响效果呢?确实会影响但相对它能带来的收益,性能的些微降低是可以接受的。能带来多大的收益呢,实验发现一般能提高 30%-40% 的吞吐。
收益主要就是由降低了 KV cache 带来的。实际上 MQA 运算量和 MHA 是差不多的,可理解为读取一组 KV 头之后,给所有 Q 头用,但因为之前提到的内存和计算的不对称,所以是有利的。
2)GQA (Group Query Attention)
GQA 则是前段时间 Google 提出的 MQA 变种,全称 Group-Query Attention。
GQA 是 MHA 和 MQA 的 折衷方案,既不想损失性能太多,又想获得 MQA 带来的推理加速好处。具体思想是,不是所有 Q 头共享一组 K、V,而是分组一定头数 Q 共享一组 K、V,比如上面图片就是两组 Q 共享一组 K、V。
Llama 2 中给出了效果对比,可以看到相比起 MQA,GQA 的指标看起来还是要好些的。

同时,GQA 在推理上的加速还和 MQA 类似:

3)提前小结
MQA 和 GQA 形式在推理加速方面,主要是通过两方面来完成:
降低了从内存中读取的数据量,所以也就减少了计算单元等待时间,提高了计算利用率;
- 在一定程度上避免了内存墙
KV cache 变小了 head_num 倍,也就是显存中需要保存的 tensor 变小了,空出来空间就可以加大 batch size,从而又能提高利用率。
如果要用 MQA 和 GQA,可以是 从头训练的时候就加上,也可以像 GQA 论文里面一样,用已有的开源模型,挑一些头取个 mean 用来初始化 MQA 或 GQA 继续训练一段时间。
4)MQA 推导
参考:安迪的写作间:为什么现在大家都在用 MQA 和 GQA?
TODO MQA 推导
5)Llama 2 的 GQA 简化代码
参考:Llama 2 详解
结合 Llama 2 的代码来看看他们的具体实现(为了篇幅做了一些简化)
TODO GQA 代码
6)为什么现在都在用 MQA 和 GQA?
MQA、GQA 的想法很简单,但是也需要时代的机遇。
Transformer 发展:从开山之作(Encoder-Decoder),到 BERT(Encoder-Only),再到 GPT 系列等 LLM(Decoder-Only);从 BERT 的小模型,到 GPT-3、GPT-4 等大模型;从实验室到应用落地。
看到这,大概也能明白为什么要用 MQA 了,以及为什么 MQA 最近才突然火起来。
主要就是因为 大规模 GPT 式生成模型的落地需求 导致的。
而在以前根本不需要关心这些,LSTM 只用维护一个状态,不存在要保留 Cache 什么。
到了 Transformer 提出后,虽然最早 Transformer 提出时是用在 Seq2Seq 任务上,也就是 Encoder 和 Decoder 都用,但可能模型量级不大,也没有太多落地需求,所以没引起太大关注。之后火了两年的 BERT 又是 Encoder 结构,直接前向一把过。
也只有到最近 GPT 大模型得到广泛应用时,才发现推理的这个瓶颈,于是大家翻出几年前的 trick,应用起来,发现非常好用。
同样原因,GPT 推理加速这块最近引起很多关注,大家都在想各种方法来提高推理效率。Huggingface 这两天也给 text-generation-inference 库的 license 给改了,应该也是想用这个挣点钱。
事物的发展总是螺旋上升~
扩展阅读
Flash Attention v1、v2
KV Cache 的升级版:PagedAttention
参考
知乎:
安迪的写作间:为什么现在大家都在用 MQA 和 GQA?
论文:
代码
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/12/17/kv-cache/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)