1、从 0 开始的学习路线
参考:
列一下个人觉得从 0 开始的最佳学习路线:
首先看文章,公式推导和 Tiling 细节强烈这篇文章:From online softmax to FlashAttention,写的非常好,由浅入深,公式推导这块看完这篇其他都不用看了。然后辅助看一些知乎文章把不明白的地方搞清楚。
理解 From online softmax to FlashAttention 需要四个步骤:
softmax
safe softmax
online softmax Tiling
FlashAttention Tiling
总之:FlashAttention 之所以可以省显存(显存开销随 Seq length 线性增加),是因为解开了 softmax 以及后面 GEMM 的行方向依赖,并且通过辅助数组保存的辅助信息 re-scale 到正确的数值。
其次,了解一些背景信息,这里附一下其他可能便于理解 FlashAttention 项目发展的背景信息:
FlashAttention V1 在 NVIDIA apex fmha 基础上实现(最早的FlashAttention Alpha Realease),V2 基于 CUTLASS 3.0 & CUTE 重构(CUTE 真是个好东西)
Flash Attention 目前最方便的调库途径主要有两个:
pip install flash-attn,官方的库,编译时间稍长,基于 CUTLASS 有大量的模板,如果想进一步魔改(比如加 bias 或者加 mask,或者稀疏化等)学习和 Debug 成本比较大使用 Triton 的实现,性能实测非常不错
最新实现在 ops 里面
稳定的实现在 tutorial 里面
最后,看代码,跑代码,Profile Kernel with Nsight Compute,改代码…
这里我推荐基于 Triton FlashAttention 上手,原因如下:
Tri-Dao 的 FlashAttention 基于 CUTLASS 3.0 重构,新手小白想要编译跑起来首先要搞定几个环境问题;里面一个头文件几千行,想看懂需要首先搞懂 CUTLASS 的基本用法,想改代码更需要一些模板猿编程 debug 技巧,想优化性能的话…你得学学 CUTE,再学学各种 GPU Features…如果你只是想学习一下 FlashAttention,或者只是想基于这个 Fusion idea 定制你自己的 kernel,没必要从 CUTLASS 开始。CUTLASS 适合 CUDA 熟手并且期望拿到 Peak Performance 的玩家。
Triton 语法很容易上手,方便魔改你自己的 Attention Kernel,或者你有其他的想法也很容易实践实验。例子:FlagAttention,Sparse Flash Attention (所以非常适合发 paper 啦,至少迭代 CUDA kernel 速度直接飙升,加快 idea 的反馈。从实验时间成本来说,用 CUDA 写半个月的 Kernel + 调一个月性能 » 用 CUTLASS 写一周 Kenrel + 调两天性能 » 用Triton 写 3 天 Kernel + 调 1 天性能)
Triton FlashAttention 在 Hopper-Triton PR 之后,目前 main 分支已经集成了大量的 Hopper 相关的优化 Pass,相比官方库还没有稳定实现 Hopper features 来说,在某些 problem size 下可能有优势。
关于 Triton 推荐阅读:杨军:谈谈对 OpenAI Triton 的一些理解,杨军:OpenAI Triton Conference 参会随感兼谈 Triton Hopper
2、背景
参考:猛猿的回答
2.1、Flash-Attention 做了什么事?
我们知道,对于 Transformer 类的模型,假设其输入序列长度为 $N$,那么其计算复杂度和消耗的存储空间都为 \(O(N^{2})\)。也就是说,随着输入序列的变长,将给计算和存储带来极大的压力。
因此,我们迫切需要一种办法,能解决 Transformer 模型的 \(O(N^{2})\) 复杂度问题。如果能降到 \(O(N)\),那是最好的,即使做不到,逼近 \(O(N)\) 那也是可以的。所以,Flash Attention 就作为一种行之有效的解决方案出现了。
Flash Attention 在做的事情,其实都包含在它的命名中了(Fast and Memory Efficient Exact Attention with IO-Awareness),我们逐一来看:
Fast(with IO-Awareness),计算快。在 Flash-Attention 之前,也出现过一些加速 Transformer 计算的方法,这些方法的着眼点是 “减少计算量FLOPs”,例如用一个稀疏 Attention 做近似计算。但是 Flash-Attention 就不一样了,它并没有减少总的计算量,因为它发现:计算慢的卡点不在运算能力,而是在读写速度上。所以它通过 降低对显存(HBM)的访问次数来加快整体运算速度,这种方法又被称为 IO-Awareness。在后文中,我们会详细来看 Flash-Attention 是如何通过分块计算(tiling)和核函数融合(kernel fusion)来降低对显存的访问。
Memory Efficient,节省显存。在标准 Attention 场景中,forward时我们会计算并保存 \(N\times N\) 大小的注意力矩阵;在 backward 时我们又会读取它做梯度计算,这就给硬件造成了 \(O(N^{2})\) 的存储压力。在 Flash Attention 中,则巧妙避开了这点,使得存储压力降至 \(O(N)\)。
Exact Attention,精确注意力。在(1)中我们说过,之前的办法会采用类似于 “稀疏 Attention” 的方法做近似。这样虽然能减少计算量,但算出来的结果并不完全等同于标准 Attention 下的结果。但是 Flash Attention 却做到了 完全等同于标准 Attention 的实现方式,这也是后文我们讲述的要点。
2.2、计算限制与内存限制
在第一部分中我们提过,Flash Attention 一个很重要的改进点是:由于它发现 Transformer 的计算瓶颈不在运算能力,而在读写速度上。因此它着手降低了对显存数据的访问次数,这才把整体计算效率提了上来。所以现在我们要问了:它是怎么知道卡点在读写速度上的?
为了解答这个问题,我们先来看几个重要概念:
\(\pi\):硬件算力上限。指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。
\(\beta\):硬件带宽上限。指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是 Byte/s。
\(\pi_{t}\):某个算法所需的总运算量,单位是 FLOPs。下标 \(t\) 表示total。
\(\beta_{t}\):某个算法所需的总数据读取存储量,单位是 Byte。下标 \(t\) 表示 total。
这里再强调一下对 FLOPS 和 FLOPs 的解释:
FLOPS:等同于 FLOP/s,表示Floating Point Operations Per Second,即每秒执行的浮点数操作次数,用于衡量硬件计算性能。
FLOPs:表示 Floating Point Operations,表示某个算法的总计算量(即总浮点运算次数),用于衡量一个算法的复杂度。
我们知道,在执行运算的过程中,时间不仅花在计算本身上,也花在数据读取存储上,所以现在我们定义:
\(T_{cal}\):对某个算法而言,计算所耗费的时间,单位为 s,下标 cal 表示 calculate。其满足 \(T_{cal} =\frac{\pi_{t}}{\pi}\)
\(T_{load}\):对某个算法而言,读取存储数据所耗费的时间,单位为 s。其满足 \(T_{load} = \frac{\beta_{t}}{\beta}\)
我们知道,数据在读取的同时,可以计算;在计算的同时也可以读取,所以我们有:
\(T\):对某个算法而言,完成整个计算所耗费的总时间,单位为 s。其满足 \(T = max(T_{cal}, T_{load})\)
也就是说,最终一个算法运行的总时间,取决于计算时间和数据读取时间中的最大值。
1)计算限制
当 \(T_{cal} > T_{load}\) 时,算法运行的瓶颈在计算上,我们称这种情况为 计算限制(math-bound)。此时我们有: \(\frac{\pi_{t}}{\pi} > \frac{\beta_{t}}{\beta}\),即 \(\frac{\pi_{t}}{\beta_{t}} > \frac{\pi}{\beta}\)
2)内存限制
当 \(T_{cal} < T_{load}\) 时,算法运行的瓶颈在数据读取上,我们称这种情况为 内存限制(memory-bound)。此时我们有 \(\frac{\pi_{t}}{\pi} <\frac{\beta_{t}}{\beta}\),即 \(\frac{\pi_{t}}{\beta_{t}} <\frac{\pi}{\beta}\)
我们称 \(\frac{\pi_{t}}{\beta_{t}}\) 为算法的 计算强度(Operational Intensity)
2.3、Attention 中的计算限制与内存限制
本节内容参考自:回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力
现在我们可以来分析影响 Transformer 计算效率的因素到底是什么了。我们把目光聚焦到 Attention 矩阵的计算上,其计算复杂度为 \(O(N^{2})\),是 Transformer 计算耗时的大头。
假设我们现在采用的硬件为 A100-40GB SXM,同时采用混合精度训练(可理解为训练过程中的计算和存储都是 fp16 形式的,一个元素占用 2 byte)
机器总的计算强度为:
\[\frac{\pi}{\beta} = \frac{312 \times 10^{12}}{1555 \times 10^{9}} = 201 FLOPs / byte\]假定我们现在有矩阵 ,其中 \(\) 为序列长度,\(d\) 为 embedding dim。现在我们要计算 ,则有:
\[\frac{\pi_t}{\beta_t} = \frac{2N^2d}{2Nd + 2Nd + 2N^2} = \frac{N^2d}{2Nd + N^2}\]不同 \(N, d\) 取值下的受限类型如下:
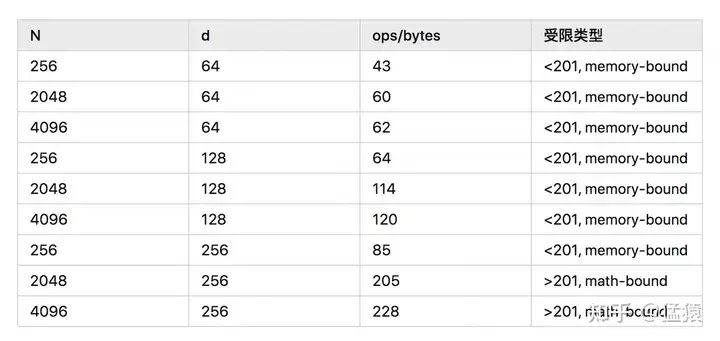
根据这个表格,我们可以来做下总结:
计算限制(math-bound):大矩阵乘法(\(N\) 和 \(d\) 都非常大)、通道数很大的卷积运算。相对而言,读得快,算得慢。
内存限制(memory-bound):逐点运算操作。例如:激活函数、dropout、mask、softmax、BN 和 LN。相对而言,算得快,读得慢。
所以,我们第一部分中所说,“Transformer 计算受限于数据读取” 也不是绝对的,要综合硬件本身和模型大小来综合判断。但从表中的结果我们可知,memory-bound 的情况还是普遍存在的,所以 Flash-Attention 的改进思想在很多场景下依然适用。
在 Flash-Attention 中,计算注意力矩阵时的 softmax 计算就受到了内存限制,这也是 Flash-Attention 的重点优化对象,我们会在下文来详细看这一点。
2.4、roof-line 模型
参考:
一个算法运行的效率是离不开硬件本身的。我们往往想知道:对于一个运算量为 \(\pi_t\),数据读取存储量为 \(\beta_t\) 的算法,它在算力上限为 \(\pi\),带宽上限为 \(\beta\) 的硬件上,能达到的最大性能 $P$ (Attanable Performance) 是多少?
这里最大性能 $P$ 指的是当前算法实际运行在硬件上时,每秒最多能达到的计算次数,单位是 FLOP/s。
Roof-line 模型就是为了解答这一问题而提出的,它能直观帮我们看到算法在硬件上能跑得多快,模型见下图。
如图,横坐标 $I$ 表示计算强度,满足 \(I = \frac{\pi_t}{\beta_t}\);纵坐标 \(P\) 表示算法运行在硬件上的性能。算法的运行性能不会超过硬件本身的计算上限,所以 $P$ 的最大值取到 $\pi$。根据我们之前的分析,
当 \(I > \frac{\pi}{\beta}\) 时,存在计算限制;
当 \(I < \frac{\pi}{\beta}\) 时,存在内存限制。
3、Flash-Attention v1
3.1、Forward 过程
TODO 待更
1)普通 Softmax
2)安全 Softmax
3)Online Softmax
4)Kernel 融合

图片来源:https://www.bilibili.com/video/BV1Zz4y1q7FX/
3.2、Backward 过程
TODO 待更
4、代码
4.1、Flash-Attention
仓库:
- GitHub:https://github.com/Dao-AILab/flash-attention

支持的 GPU
目前,支持的 GPU 包括:
Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon, please use FlashAttention 1.x for Turing GPUs for now.
Datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs).
All head dimensions up to 256. Head dim > 192 backward requires A100/A800 or H100/H800.
根据这个 Issue 可以得知,目前的 Flash-Attention 暂不支持 V100 GPU,作者预计会在明年(2024 年)的 6 月份提供对 V100 GPU 的支持。
4.2、HuggingFace

图片来源:https://huggingface.co/docs/text-generation-inference/conceptual/flash_attention
参考
GitHub:https://github.com/Dao-AILab/flash-attention
HuggingFace:https://huggingface.co/docs/text-generation-inference/conceptual/flash_attention
Flash-Attention v1 论文:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Flash-Attention v2 论文:FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flash-Attention v3:FlashDecoding
Flash-Attention v4:FlashDecoding++
Flash Attention 前向推导:From online softmax to FlashAttention【推荐】
知乎:
- Austin:FlashAttention图解(如何加速Attention)【推荐】
CSDN:
扩展阅读
Page-Attention、MQA(Multi Query Attention)、GQA(Group-Query Attention)
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/12/13/flash-attention/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)