《VanillaNet: the Power of Minimalism in Deep Learning》
URL:https://arxiv.org/abs/2305.12972
Official Code:https://github.com/huawei-noah/vanillanet
单位:华为诺亚方舟实验室

VanillaNet 结构
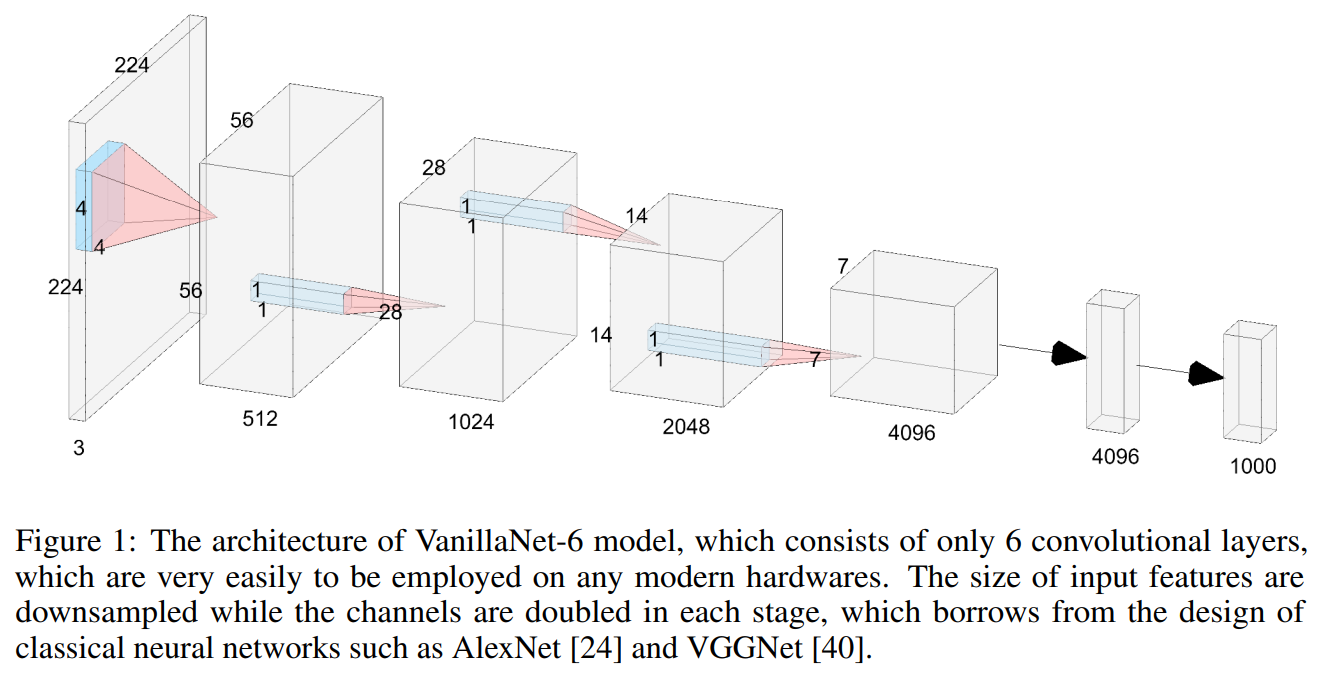
Most of the state-of-the-art image classification network architectures should consist of three parts: a stem block to transform the input images from 3 channels into multiple channels with downsampling, a main body to learn useful information, a fully connect layer for classification outputs.
主体通常有四个阶段,每个阶段都是通过堆叠相同的块来派生的。在每个阶段之后,特征的通道将扩展,而高度和宽度将减小。不同的网络利用和堆叠不同种类的块来构建深度模型。
我们遵循流行的神经网络设计,包括主干、主体和全连接层。与现有的深度网络不同,我们在每个阶段只使用一层,以建立一个尽可能少的层的极其简单的网络。
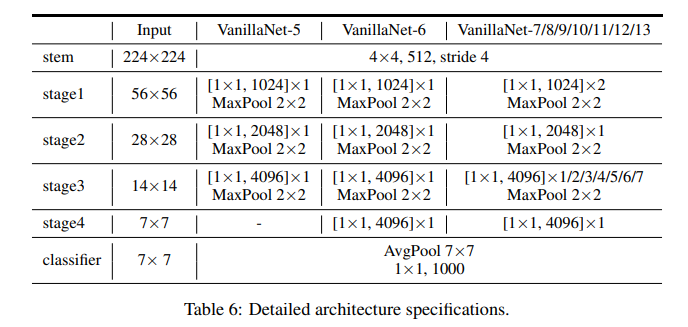
尽管 VanillaNet 的结构很简单且相对较浅,但其较弱的非线性也影响了性能,因此,我们提出了一系列解决问题的技术。
利用深度训练技术来提高所提出的 VanillaNet 在训练期间的能力
增强模型的非线性能力
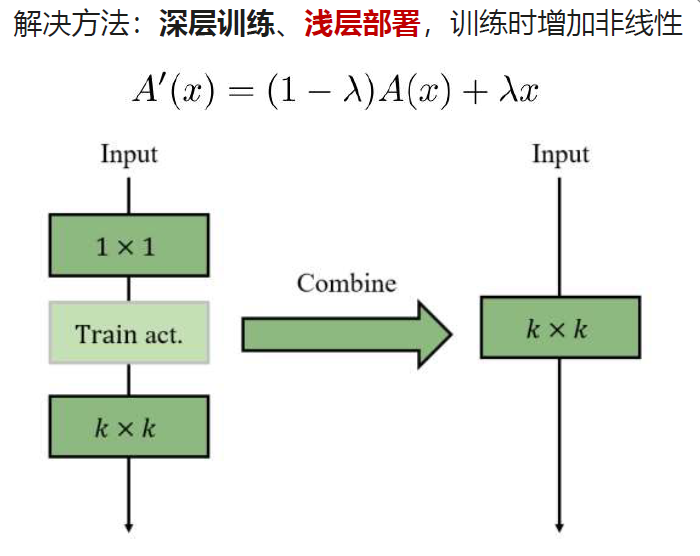
1)深层训练、浅层部署(Deep Training Strategy)
训练时的激活函数
深度训练策略的主要思想是在训练过程开始时训练两个具有激活函数的卷积层而不是单个卷积层。随着训练次数的增加,激活函数逐渐缩减为恒等映射。在训练结束时,两个卷积可以很容易地合并到一个卷积中,以减少推理时间。
对于激活函数 \(A(x)\)(可以是 ReLU 和 Tanh 等常用函数),我们将其 与恒等映射相结合,可以表示为:
其中,\(\lambda\) 是一个超参数,用于平衡修改后的激活函数 \(A^{\prime}(x)\) 的非线性。将当前 epoch 和深度训练 epoch 的数量分别表示为 \(e\) 和 \(E\)。
我们设 $$\lambda = \frac{e}{E},
在训练开始时(\(e = 0\)),\(\lambda=0\),\(A^{\prime}(x)= A(x)\),这意味着网络具有很强的非线性;
当训练收敛时,有 \(\lambda=1\),则 \(A^{\prime}(x) = x\),这意味着两个卷积层在中间没有激活函数;
部署
下面演示了在模型部署阶段,如何合并这两个卷积层。
1)融合 Conv + BN
首先,将 VanillaNet 中的每一个 Batch Normalization 层与它前面的卷积层进行融合:
2)融合两个 \(1\times 1\) 卷积
注意:
- 在这两个 \(1\times 1\) 卷积之间,是 没有激活函数 的
2)并行叠加激活函数(Series Informed Activation Function)
实际上,改善神经网络的非线性有两种方法:
堆叠非线性激活层(stacking the non-linear activation layers)
增加每个激活层的非线性(increase the non-linearity of each activation layer)
而现有网络大多数都选择前者,导致模型的延迟很高,并且无法充分利用硬件的并行计算能力。
改善激活层非线性的一种直接想法是 堆叠。激活函数的串行堆叠 是深度网络的关键思想。
相反,我们转向 并行堆叠激活函数。将神经网络中输入 \(x\) 的单个激活函数表示为 \(A(x)\),可以是 ReLU 和 Tanh 等常用的激活函数。\(A(x)\) 的并行堆叠可以表示为:
其中,\(n\) 表示堆叠激活函数的数量,\(a_i\) 和 \(b_i\) 是每个激活的规模和偏置(bias),以避免简单累积。通过并发堆叠可以大大增强激活函数的非线性。式 5 可以看作是数学中的 级数,是很多量相加的运算。

为了进一步丰富级数的逼近能力,我们使基于级数的函数能够通过改变其邻居的输入来学习全局信息,这与 BNET 类似。具体来说,给定一个输入特征 \(x\in R^{H\times W\times C}\) ,其中 \(H\)、\(W\) 和 \(C\) 是其宽度、高度和通道的数量,激活函数表示为:
\[\]实验
1)Deep Training 和 Series Activation 的有效性
提出的级数激活函数和深度训练策略在不同网络的效果:

仅对简单的浅网络有效,而对复杂的网络没有提升。
2)Shortcut 对 VanillaNet 没有帮助

3)在 ImageNet-1K 上的分类结果

无需残差等复杂模块,VanillaNet-13 在 ImageNet 上达到 83% 的精度

6 层的 VanillaNet 性能超越 34 层的 ResNet,速度提升一倍以上
13 层的 VanillaNet 性能超越近百层的 Swin-S,速度提升一倍以上
代码
更多:一份 PDF
参考
VanillaNet 论文:《VanillaNet: the Power of Minimalism in Deep Learning》
作者的知乎文章:卷积的尽头不是Transformer,极简架构潜力无限
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/06/03/VanillaNet/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)