论文:Revisiting Few-sample BERT Fine-tuning
《Revisiting Few-sample BERT Fine-tuning》
URL:https://arxiv.org/abs/2006.05987
Code:https://github.com/asappresearch/revisit-bert-finetuning
单位:ASAPP Inc & Stanford University
会议:ICLR 2021
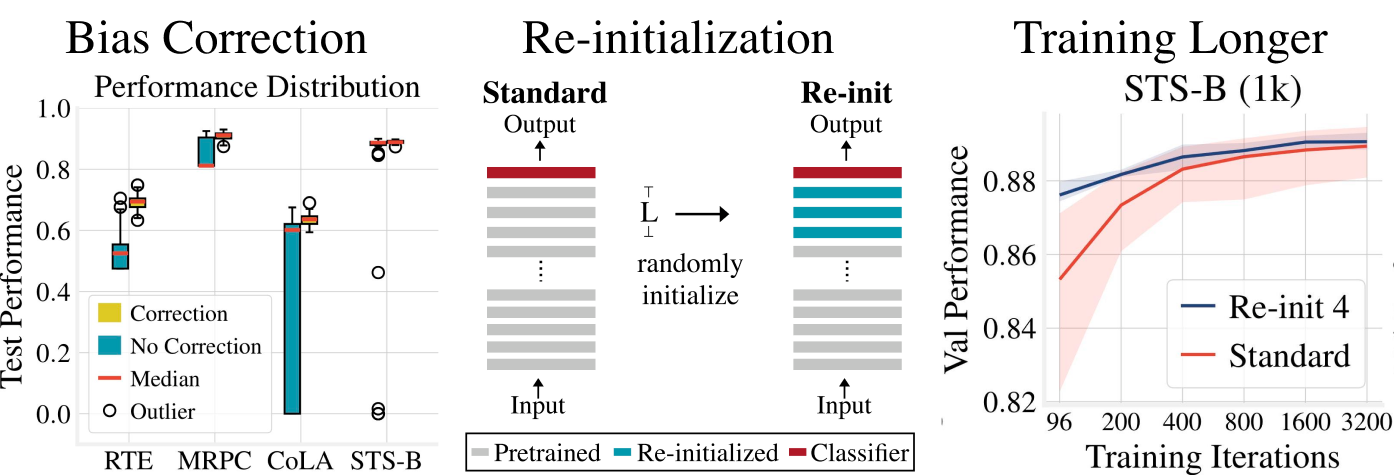
1、BERTAdam 的 debiasing 影响
在 BERTAdam 的实现中,并没有进行动量偏差修正,因此在模型训练初期以及指数衰减率超参数 \(\beta\) 很小的时候,动量估计值很容易往 0 的方向偏移。因此,作者做了个小的偏差修正,对梯度均值 \(m_t, v_t\) 进行偏差纠正,降低偏差(bias)对训练初期的影响,如下图所示:

也许在规模庞大的数据量和很多的训练步数下,偏差修正能起到的作用很小,模型会在训练后期趋于稳定。但是在实际做 finetune 任务中,训练样本较少,这种优化方案就会出现训练的不稳定。
为了验证这个结论,论文作者做了非常详细的对比试验,他们在四个不同的数据集上,尝试了50种不同的随机种子,分别用带偏移修正的原始 Adam 和不带修正的 BERTAdam 去做 finetune 任务。实验结果分别从不同角度来验证上述的观点,如下图所示:
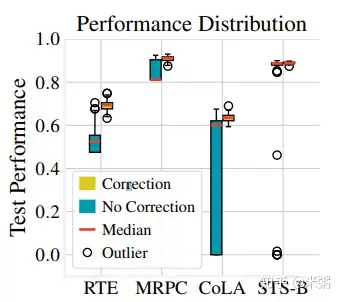
这是一个模型在不同数据集上的测试集效果 箱线图,图中表明在四个数据集上,使用偏移修正的 Adam 能够极大提升模型在测试集上的效果。
作者还通过 train loss 变化,突出偏差修正的好处,如下图所示:
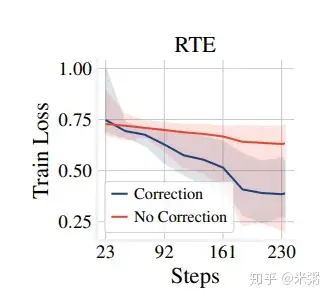
这张图反应了在小数据上,使用偏移修正进行 finetune,模型能够更快的达到收敛,获得更小的 train loss
2、权重参数再初始化
论文 《Revisiting Few-sample BERT Fine-tuning》 中提到的第二个优化点是 权重的重新初始化。
我们在做下游任务的 finetune 时,主流的做法是直接将预训练好的参数直接迁移过来,初始化模型的参数在训练,这样有助于将之前大量语料预训练的语言知识带到下游任务中。但存在一个问题,BERT 的层数较多,不同层学到的信息不一样,那 究竟哪些层的信息对下游任务会起到帮助?
对于 BERT 模型中每层学到了哪些信息,在 ACL 2019 年的论文中 《What does BERT learn about the structure of language?》 进行了仔细的分析,其主要结论就是:
BERT 的低层网络就学习到了 短语级别 的信息表征
BERT 的中层网络就学习到了丰富的 语言学 特征
BERT 的高层网络则学习到了丰富的 语义信息 特征
也就是说,不同层的网络学到的信息存在差异,尤其在越高层,学到的信息越贴近下游任务。
预训练时主要的任务是 masked word prediction、next sentence prediction 任务的相关知识,这也就使得我们在做下游任务时,需要根据具体的实际任务场景,来选择网络层。如果我们的实际任务与预训练任务差距比较大(例如序列标注),那么使用预训练时高层学到的信息反而会拖累整体的 finetune 进程,使得模型在 finetune 初期产生不稳定。
论文作者做了以下实验进行了验证:重新初始化 BERT 的 pooler 层(文本分类会用到),同时尝试重新初始化 BERT 的 top-L 层参数的权重(\(1 \le L \le 6\)),如下图所示:
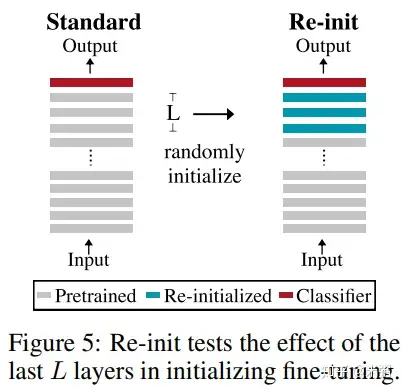
论文基于 12 层的 BERT,对 Top 6 层进行重新初始化(正态分布初始化),在 RTE、MRPC 等数据集上进行 finetune,结果如下表所示:

结果很明显,相对于完全使用 BERT 进行初始化,部分初始化对最后模型的性能都有一定程度的提升。
那么具体应该对多少层的权重做重新初始化呢,作者也做了些对比实验,如下图所示:
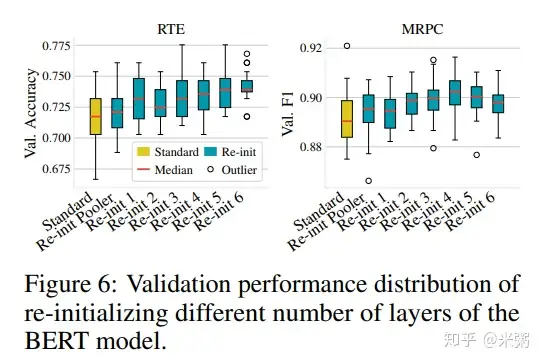
实验结果表明,并没有一个显著的规律,具体的层数与下游任务场景和数据集有关。
小总结

figture 6:说明随机初始化 top N(\(N<6\))层或多或少都能提升模型的性能;
figture 7:说明随机初始化 top N 某些层,能加快模型收敛速度;
figture 8:说明随机初始化 top N 某些层,对高层的参数改变的更小,但随着 \(N\) 的增大,比如 \(N=10\),会使得底层的参数改变严重;
3、finetune 更长的 step
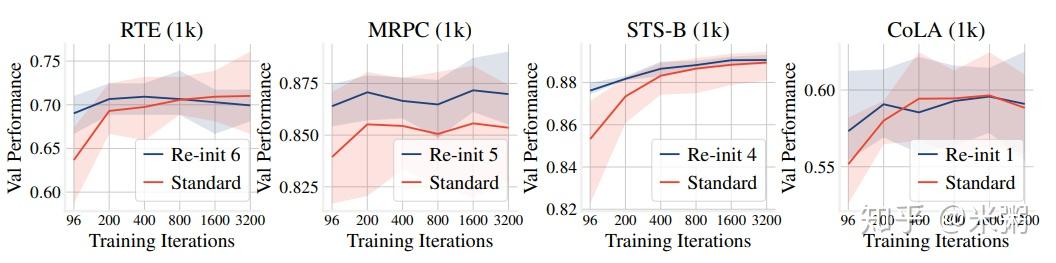
训练更长的时间有利于提高模型的性能,特别是数据集小于 1000 时,如下图所示:
代码
针对 BERT 模型的重新初始化(reinit),参考了论文 《Revisiting Few-sample BERT Fine-tuning》 的 原始代码,并进行了简化:
import torch
import torch.nn as nn
from transformers import (
AutoModelForSequenceClassification,
)
"""
一些参数
"""
model_type = "bert"
model_name_or_path = "bert-base-uncased"
cache_dir = "./pretrained"
reinit_pooler = True
reinit_layers = 5
"""
创建模型
"""
model = AutoModelForSequenceClassification.from_pretrained(
model_name_or_path,
from_tf=bool(".ckpt" in model_name_or_path),
# config=config,
cache_dir=cache_dir if cache_dir else None,
)
# re_init pooler
# 使用正态分布对 weight 进行初始化,对 bias 使用全零初始化
if reinit_pooler:
if model_type in ["bert", "roberta"]:
encoder_temp = getattr(model, model_type)
encoder_temp.pooler.dense.weight.data.normal_(mean=0.0, std=encoder_temp.config.initializer_range)
encoder_temp.pooler.dense.bias.data.zero_()
# 重新训练 pooler
for p in encoder_temp.pooler.parameters():
p.requires_grad = True
if reinit_layers > 0:
if model_type in ["bert", "roberta", "electra"]:
# 从深层到浅层,选择 reinit_layers 层进行重新初始化
for layer in encoder_temp.encoder.layer[-reinit_layers :]:
for module in layer.modules():
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=encoder_temp.config.initializer_range)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_() # bias 全零
module.weight.data.fill_(1.0) # weight 全 1
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_() # bias 全零
# 打印重新初始化之后的 model
for name, param in model.named_parameters():
print(name, ": ", param)
print("=====" * 10)
更多
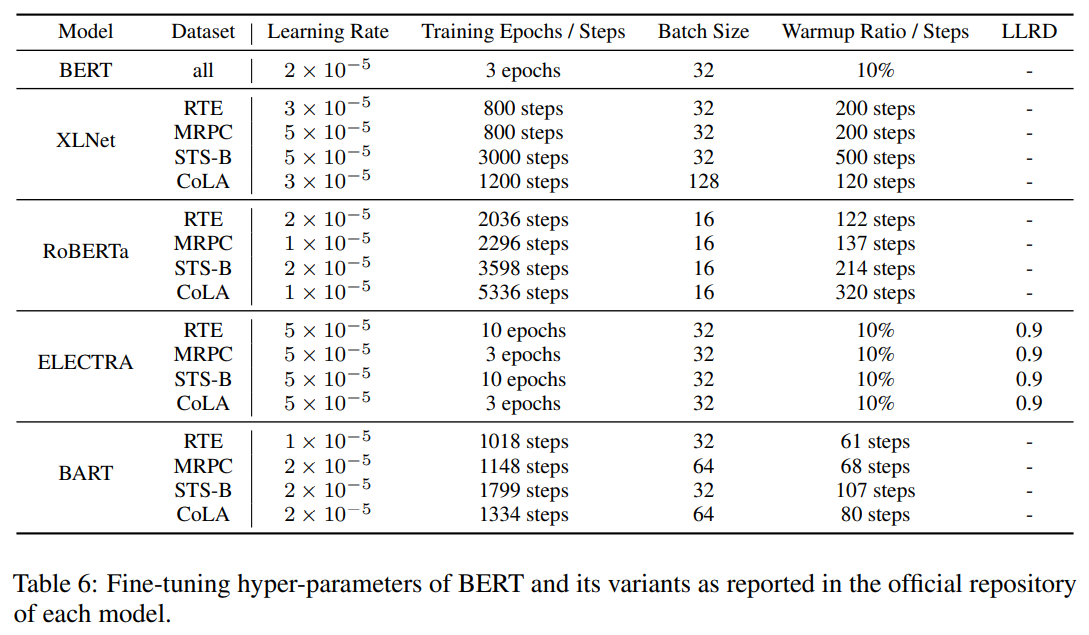
1、具体的超参数设置
论文中具体的超参数设置如下图所示:
2、其他稳定微调的方法
除了上面的几种稳定微调的方法,还有一些其他的方法,例如 Warmup、Learning Rate Decay、Weight Decay 以及 Frzone Parameters 等。
论文 《Revisiting Few-sample BERT Fine-tuning》 中也使用 Warmup 和 Linear LR Decay。
1)Weight Decay (L2 正则化)
由于在 BERT 官方的代码中对于 bias 项、LayerNorm.bias、LayerNorm.weight 项是 免于正则化 的。因此,经常在 BERT 的训练中会采用与 BERT 原训练方式一致的做法,也就是下面这段代码:
param_optimizer = list(multi_classification_model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer
if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer
if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = transformers.AdamW(optimizer_grouped_parameters, lr=config.lr, correct_bias=not config.bertadam)
注意:实践出真知,具体需不需要加,以实际的实验、任务为主!
2)冻结部分层参数(Frozen Parameters)
冻结参数经常在一些大模型的训练中使用,主要是对于一些参数较多的模型,冻结部分参数在不太影响结果精度的情况下,可以减少参数的迭代计算,加快训练速度。
在 BERT 中 fine-tune 中也常用到这种措施,一般会 冻结的是 BERT 前几层,因为有研究 BERT 结构的论文表明,BERT 前面几层冻结是不太影响模型最终结果表现的。
这个就有点类似与图像类的深度网络,模型前面层学习的都是一些通用且广泛的知识(比如一些基础的线、点形状类似),这类知识都差不多。
关于冻结参数主要有下面两种方法:
# 方法 1: 设置requires_grad = False
for param in model.parameters():
param.requires_grad = False
# 方法 2: torch.no_grad()
class net(nn.Module):
def __init__():
......
def forward(self.x):
with torch.no_grad(): # no_grad下参数不会迭代
x = self.layer(x)
......
x = self.fc(x)
return x
参考
知乎:
CSDN:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/05/30/fine-tune-bert/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)