
ImageBind
拥有「多种感官」的多模态 AI 模型 ImageBind,能够将文本、音频、深度图、热红外以及 IMU 数据,嵌入到一个向量空间中。
多模态「千脑智能」ImageBind 能够像人一样 结合不同的感官。从多种维度理解世界。

《ImageBind: One Embedding Space To Bind Them All》
- URL:
- https://arxiv.org/abs/2305.05665
- https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
- Official Code:https://github.com/facebookresearch/ImageBind(不能商用)
- 单位:Meta AI
- 会议:CVPR 2023 以 图像(Image)为基准点,将 文本(text)、音频(audio)、深度图(depth)、红外热图(thermal)、IMU(Inertial Measurement Unit,惯性测量单元)数据 这几种模态的数据嵌入到 一个联合的空间中(joint embedding space)。

ImageBind 只需要经过很少的训练,就能够在 三种应用 上开箱即用(out-of-the-box),分别是(如上图所示):
跨模态检索(cross-modal retrieval)
在 Image-Text pair 上训练
具备很强的 涌现对齐能力:能够 隐式对齐 audio、depth、thermal 等模态数据(即使训练时并没有给模型看过)
- 例如,假设训练数据中没有 (text, audio) 的配对数据,而你需要对 text 和 audio 进行对齐,之前的方法无法做到这一点,而通过 ImageBind 则能够对 text 和 audio 进行对齐
模态算数组合运算(composing modalities with arithmetic)
由于模态数据被嵌入到一个联合空间中,因此可以对联合空间中的嵌入向量进行算数组合运算(例如加法和减法)
与 Word Embedding 类似,例如
皇后 - 女人 + 男人 = 皇上
跨模态检测和生成(cross-modal detection and generation)
detecting audio sources in images
Audio to Image Generation:通过音频生成对应的图像
1、Motivation
一张图片可以将许多体验结合在一起,例如:一张海滩图片可以让我们想起海浪的声音、沙子的质地、微风,甚至可以激发一首诗的灵感。图像的这种 “绑定” 属性 通过将它们与与图像相关的任何感官体验对齐,为学习视觉特征提供了许多监督来源。
理想情况下,对于单个联合嵌入空间,视觉特征应该通过与所有这些传感器对齐来学习。然而,这需要用同一组图像获取所有类型和组合的配对数据,这是不可行的。
最近,许多方法学习与文本、音频等对齐的图像特征。这些方法使用一对模态或者,充其量是一些视觉模式。然而,最终的嵌入仅限于用于训练的模态对。因此,视频-音频嵌入不能直接用于图像-文本任务,反之亦然。
学习真正的联合嵌入的一个 主要障碍 是 缺乏大量包含所有模态的多模态数据。
ImageBind 利用 多种类型的图像配对数据 来学习单个共享的联合表示空间。这种方法不需要使用所有模态都同时出现的数据,而是以 Image 为 基准点(参照物),使用 Image-Text 配对数据来进行训练,并扩展到其他模态。文章的实验表示:只需将每个模态的嵌入与图像嵌入进行对齐,就能够使所有的模态数据进行 隐式对齐(emergent alignment)。如下图所示:

作者使用大规模的 (image, text) 网络数据和自然发生(naturally occurring)的配对数据 (video, audio)、(image, depth),来学习一个联合的嵌入空间。
ImageBind 强大的 scaling 表现使该模型能够替代或增强许多人工智能模型,使它们能够使用其他模态。例如虽然 Make-A-Scene 可以通过使用文本 prompt 生成图像,但 ImageBind 可以将其升级为使用音频生成图像,如笑声或雨声。
2、方法
ImageBind 的整体概览图如下所示:

通过 Image / Video 这个参照物,ImageBind 能够将其他模态的数据联合嵌入到单个空间中,从而实现其他模态数据之间的隐式对齐。
与此同时,研究者表示 ImageBind 可以使用 大规模视觉语言模型(如 CLIP) 进行 初始化,从而利用这些模型的丰富图像和文本表示。因此,ImageBind 只需要很少的训练 就可以应用于各种不同的模态和任务。
ImageBind 是 Meta 致力于创建多模态 AI 系统的一部分,从而实现从所有相关类型数据中学习。随着模态数量的增加,ImageBind 为研究人员打开了尝试开发全新整体性系统的闸门,例如结合 3D 和 IMU 传感器来设计或体验身临其境的虚拟世界。此外它还可以提供一种 丰富的探索记忆方式,即 组合使用文本、视频和图像来搜索图像、视频、音频文件或文本信息。
2.1、通过 Image 绑定 (bind) 其他模态数据
假设有一个配对的多模态数据 \((I, M)\),给定一个图像 \(I_i\) 以及相应的配对模态数据 \(M_i\),使用独立的编码器对两者进行编码,分别得到 \(q_i = f(I_i)\) 和 \(k_i = g(M_i)\)。
使用 InfoNCE Loss 来对齐 \(I\) 和 \(M\),即:
\[\begin{align} L_{I, M} = -log \frac{exp(q_i^Tk_i/\tau)}{exp(q_i^Tk_i/\tau) + \sum_{j \neq i} exp(q_i^Tk_j/\tau)} \end{align}\]其中,\(\tau\) 是控制 softmax 分布平滑程度的温度标量;\(j\) 表示负样本。
同时,与其他的工作一样,使用对称的 InfoNCE Loss,即
\[L = L_{I, M} + L_{M, I}\]ImageBind 表明,图像配对数据足以将这六种模态绑定在一起。该模型可以更全面地解释内容,使不同的模态可以相互「对话」,并在没有同时观察它们的情况下找到它们之间的联系。例如,ImageBind 可以在没有一起观察音频和文本的情况下将二者联系起来。这使得其他模型能够「理解」新的模态,而不需要任何资源密集型的训练。
更公式化的来说:ImageBind 仅在 \((I, M_1)\) 和 \((I, M_2)\) 的配对数据上进行训练,并且无法直接获取到 \((M_1, M_2)\) 这样的数据。但是通过 ImageBind 强大的对齐能力,使得能够将 \(M_1\) 和 \(M_2)\) 隐式地 进行对齐,即:
\[\begin{align} (I, M_1)_\text{align} + (I, M_2)_\text{align} => (M_1, M_2)_\text{align} \end{align}\]2.2、实现细节
我们对图像、文本、音频、热图像、深度图像和 IMU 使用 单独的编码器。我们在每个编码器上添加一个模态特定的线性投影头以获得 固定大小的 \(d\) 维嵌入,该嵌入被 归一化 并用于 InfoNCE 损失的计算。
此外,对于 Image 和 Text 数据,我们还可以使用预训练的模型(例如 CLIP、OpenCLIP)来初始化相应的编码器。
3、实验
Meta 的分析表明,ImageBind 的 scaling 行为随着图像编码器的强度而提高。换句话说,ImageBind 对齐模态的能力随着视觉模型的能力和大小而提升。这表明,更大的视觉模型对非视觉任务有利,如音频分类,而且训练这种模型的好处超出了计算机视觉任务的范畴。
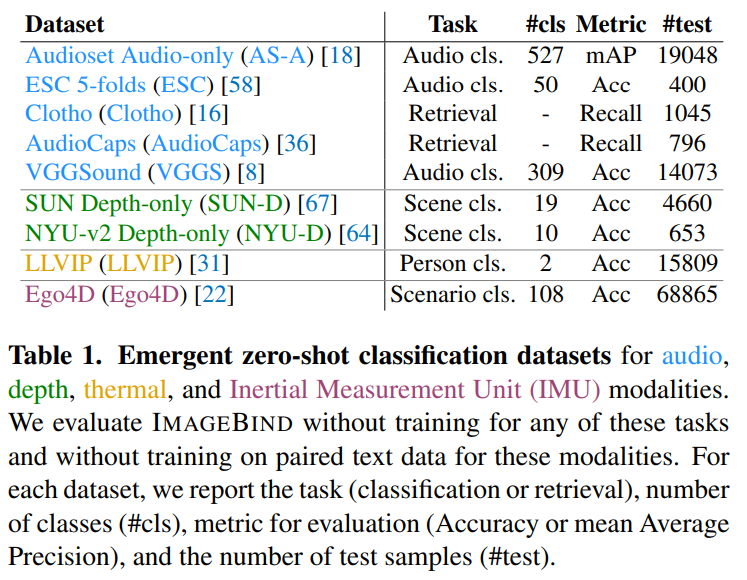
测试时使用的数据集如下图所示:(更加详细的介绍可以看论文附录)
3.1、Few-shot 分类

3.2、应用

根据音频来对图像进行目标检测,如下图所示:

4、消融实验
作者进行了详细的消融实验,包括
扩大 Image Encoder
训练损失和结构
对比损失(InfoNCE)的温度超参数
投影头
训练的 epoch 数
配对的图像数据增强
depth 编码器的选择
audio 编码器的选择
depth、audio 编码器的容量
batch size 的选择
4.1、扩大 Image Encoder
在扩大 Image Encoder 的过程中,始终保持其他模态编码器的容量不变。
我们测量了深度图、音频、热红外图和 IMU 模态的紧急零样本分类的性能。扩大图像编码器可 显著改善 零样本的分类结果,这表明 更强的视觉表示可以改善模态的 “绑定”。如下图所示:
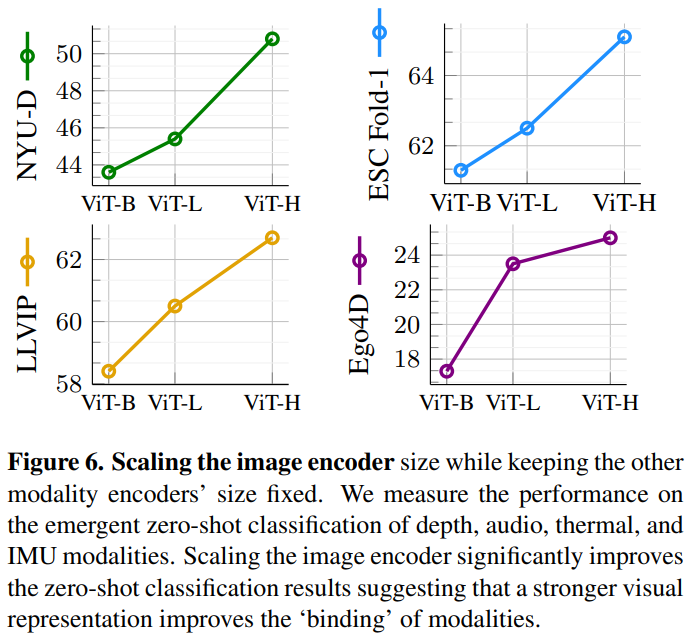
其中,
ViT-B、ViT-L 来源于 CLIP
ViT-H 来源于 OpenCLIP
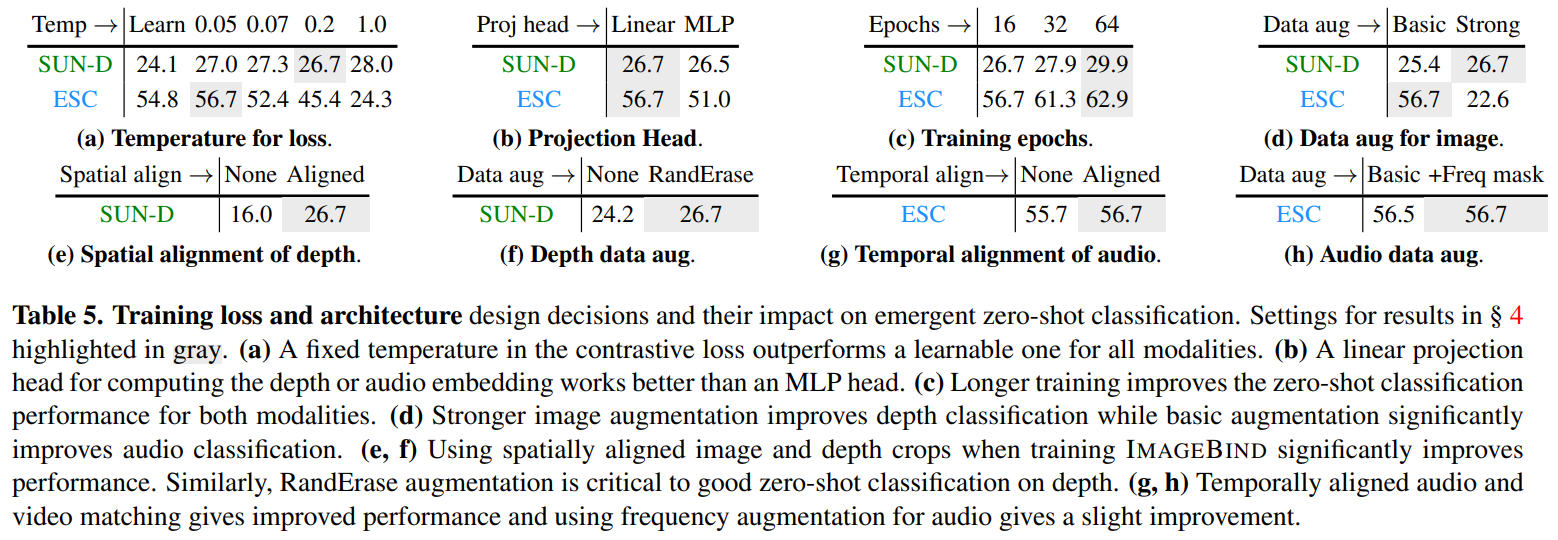
4.2、训练损失和模型结构
作者对训练的损失函数和模型结构进行了详细的消融实验,如下图所示:
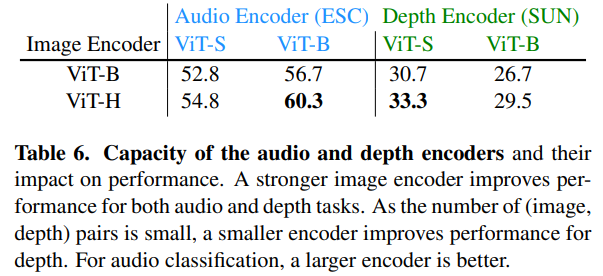
作者扩大 Audio 和 Depth 编码器的容量,其实验结果如下所示:
作者发现对比损失的最佳批量大小因任务而异,如下图所示:
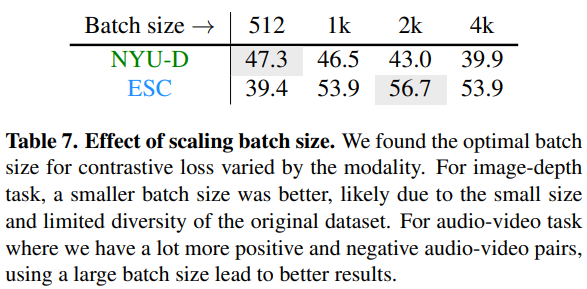
对于图像深度(image-depth)任务,batch size 越小越好,这可能是由于原始数据集的大小和多样性有限。
对于有更多正、负音频-视频对的音频-视频(audio-video)任务,使用大的 batch size 会带来更好的结果。
4.3、ImageBind 能够作为评估预训练视觉模型的工具
我们使用预训练模型初始化视觉编码器并保持固定。我们使用图像配对数据(image paired data)来对齐和训练文本、音频和深度编码器。
与有监督的 DeiT 模型相比,自监督的 DINO 模型在 深度图和音频模态 上的 涌现的 zero-shot 分类能力 更强。如下图所示:
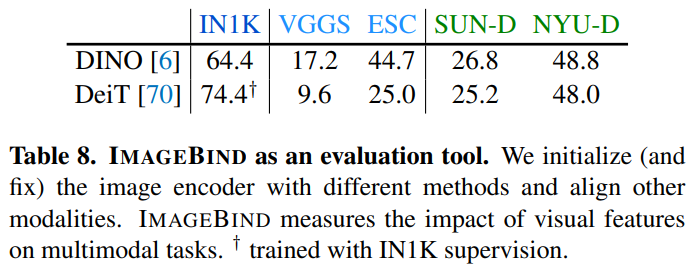
此外,涌现的 zero-shot 能力与 ImageNet 上的纯视觉能力无关,也就是说,虽然 DINO 在 ImageNet 上的性能不如 DeiT,但是 DINO 在其他模态上的 zero-shot 能力强于 DeiT。因此,ImageBind 可以作为一种有价值的工具,用来衡量视觉模型在多模式应用程序中的性能。
Demo 演示
Meta AI 开放了模型部分演示检索和生成 Demo,包括:
检索
Image > Audio(使用图像检索音频)
Audio > Image(使用音频检索图像)
Text > Image & Audio(使用文本检索图像和音频)
Audio & Image > Image(使用音频和图像去检索相关图像)
生成
- Audio > (使用音频生成图像)
代码
参考:https://github.com/facebookresearch/ImageBind
- 提供了 ImageBind-Huge 的 模型权重
提取不同模态数据的特征,并比较两两之间的距离(例如 Image、Text、Audio):
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])
参考
Meta AI
github:ImageBind
demo:https://imagebind.metademolab.com/demo
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/05/11/ImageBind/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)