Foundation Models(基础模型)
《On the Opportunities and Risks of Foundation Models》
URL:https://arxiv.org/abs/2108.07258
单位:Center for Research on Foundation Models、斯坦福大学

摘要
AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character.
随着模型(例如 BERT、DALL-E、GPT-3)的兴起,AI 正在经历范式转变,这些模型在广泛的数据上进行大规模训练并可用于广泛的下游任务。我们称这些模型为 基础模型,以强调它们至关重要但不完整的特征。
This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties.
本报告全面介绍了基础模型的机会和风险,包括它们的能力(例如,语言、视觉、机器人、推理、人类交互)、技术原则(例如,模型架构、训练程序、数据、系统、安全性) 、评估、理论)、应用(例如,法律、医疗保健、教育)和社会影响(例如,不平等、滥用、经济和环境影响、法律和伦理考虑)。尽管基础模型基于标准的深度学习和迁移学习,但它们的规模会产生新的新兴能力,并且它们在众多任务中的有效性会激励 同质化。同质化提供了强大的杠杆作用,但需要谨慎,因为基础模型的缺陷会被下游的所有适应模型(adapted models)继承。尽管基础模型即将广泛部署,但我们目前对它们的工作原理、失败时间、涌现能力 甚至能够做什么还缺乏清晰的了解。
To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
为了解决这些问题,我们认为对基础模型的许多批判性研究将需要与其基本的社会技术性质相称的 深度跨学科合作。
1、引言
1.1、涌现和同质化(Emergence and homogenization)
基础模型的意义可以用两个词来概括:涌现(Emergence) 和 同质化(homogenization)。
涌现意味着系统的行为是隐式归纳而不是显式构造的;它既带来科学上的振奋,也引起了对意外后果的焦虑。
同质化指出了在广泛的应用中构建机器学习系统的方法论的合集;它为许多任务提供了强大的支撑,但也会产生故障点。
为了更好地理解涌现和同质化,让我们回顾一下过去 30 年来它们在人工智能研究中的崛起。
人工智能的故事一直是不断涌现或者不断同质化。
随着机器学习的引入,任务从例子中学习如何执行(自动推断);
通过深度学习,涌现了用于预测的高级特征;
有了基础模型,甚至涌现了上下文学习等高级功能;
与此同时,机器学习使 学习算法同质化(例如,逻辑回归),深度学习使 模型架构同质化(例如,卷积神经网络、Transformer),基础模型使模型本身同质化(例如,GPT-3)。如下图所示:

2018 年底,NLP 领域又一次迎来了翻天覆地的变化,标志着基础模型时代的开始。
在技术层面上,基础模型是通过迁移学习(Transfer Learning)和规模化(Scaling)实现的。迁移学习使基础模型成为可能,而规模化使它们更加强大。
迁移学习的思想是将从一项任务(例如,图像中的对象识别)中学到的 “知识” 应用到另一项任务(例如,视频中的行为识别)中。
规模化需要三个要素:
计算机硬件的改进:GPU 吞吐量和内存在过去四年中增加了 10 倍
Transformer 模型架构的开发
更多可用的训练数据
有趣的是,自监督学习在深度学习的早期占据主导地位,但十年来,随着标注数据集变得越来越大,它在很大程度上被纯粹的有监督学习所取代,被研究人员所忽视。
自监督学习在 NLP 领域的应用可以追溯到 WordEmbedding,此后不久,此后的基于自回归语言建模(Autoregression LM)的自监督学习(根据前一个词预测下一个词)开始流行,这产生了在上下文中表示单词的模型,例如 GPT、ELMo 和 ULMFiT。
自监督学习的下一波发展浪潮是:BERT、GPT-2、RoBERTa、T5、BART 等模型,扩展到更大的模型和数据集。
基础模型导致了前所未有的同质化水平:几乎所有最先进的 NLP 模型都源自少数基础模型之一,例如 BERT、GPT、RoBERTa、BART、T5 等。
这种同质化产生了极高的影响力(基础模型的任何改进都可以为所有 NLP 任务带来直接的好处);
但它也是一种负担:所有人工智能系统都可能 继承 一些与基础模型相同的 错误偏置
同时,也有越来越多的工作也表现出了跨模态/多模态模型的同质化,例如基于语言和视觉数据训练的基础模型。数据在某些领域天然是多模态的—例如医疗图像、结构化数据、医疗中的临床文本,因此,多模态基础模型是融合领域的所有相关信息并适配跨越多种模态任务的一种自然方法。如下图所示:

未来,我们将拥有一套 统一的工具 来 开发各种模态的基础模型。
涌现与同质化的关系
同质化和涌现以一种 可能难以预料 的方式相互作用。
同质化可能为许多限定任务领域提供巨大的收益,这些领域的数据通常非常缺乏。但与此同时,模型中的任何缺陷都会被所有适配好的模型盲目继承;
由于基础模型的力量来自于它们的涌现性质而不是它们的显式构造,现有的基础模型难以理解,并且具有难以预料的错误模式。
由于涌现对基础模型的能力和缺陷造成了很大的不确定性,对这些模型激进的同质化是有风险的。从伦理和人工智能安全的角度来看,去风险是进一步开发基础模型的核心挑战。
1.2、社会影响和基础模型生态系统
基础模型因其令人印象深刻的表现和能力而在科学上引起了兴趣,但使它们成为研究的关键是它们正在迅速被部署到现实的AI系统应用中,并对人们产生了深远的影响。例如,拥有 40 亿用户的 Google 搜索现在依赖于 BERT 等基础模型,参见 Google blog。
为了进一步理解基础模型的研究和部署,我们必须缩小范围并考虑这些基础模型所在的完整生态系统,从数据创建到实际部署。简而言之,我们可以从不同阶段的角度来考虑基础模型的生态系统,扩展之前的训练和适配阶段,如下图所示:

数据创建:数据创建从根本上讲是一个 以人为中心 的过程。所有数据都是由人创建的,并且大多数数据至少隐式的与人有关。
数据整理:将数据整理为数据集
训练:在这些整理好的数据集上训练基础模型是 AI 研究中的 核心部分
适配:在机器学习研究的背景下,适配是在某些 下游任务 上(例如,文档摘要),基于基础模型创建一个新模型。
部署:人工智能系统在部署供人类使用时,会产生直接的社会影响。尽管我们不想部署那些在有问题的数据上训练得到的有潜在危害的基础模型,但允许它们在研究中存在以促进科学理解,可能仍然是有价值的,但人们仍然必须谨慎行事。
虽然社会影响取决于整个生态系统,但考虑到许多研究人员和从业者的关注点仅限于训练阶段,因此推动基础模型的社会影响研究仍然很重要。
1.3、基础模型的未来
基础模型已经展示了初步潜力,但我们仍处于 早期阶段。尽管它们被部署到现实世界中,但这些模型在很大程度上还是研究原型,人们对其知之甚少。鉴于基础模型的未来充满不确定性,一个大的问题是:谁来决定这个未来?
学科多样性:基础模型背后的技术基于机器学习、优化、NLP、计算机视觉和其他领域数十年的研究,这些技术贡献来自学术界和工业界的研究实验室。然而,构建基础模型本身的研究几乎只发生在工业界,包括谷歌、Facebook、微软或华为等大型科技公司,以及 OpenAI、AI21 Labs 等初创公司。
激励:
可访问性的丧失:不幸的是,由于可访问性的丧失,学术界无法充分参与其中。
某些模型(例如 GPT-3)根本不会公开发布(只对少数人提供 API 访问权限)。甚至一些数据集(例如 GPT-2)也没有公开发布。虽然可以使用经过训练的模型(例如 BERT),但由于计算成本过高且工程要求复杂,绝大多数 AI 研究人员实际上无法对基础模型进行完整的训练。
虽然一些社区正在尝试训练大型基础模型,例如 EleutherAI 和 HuggingFace 的 BigScience 项目,然而 行业训练的私有模型与向社区开放的模型之间的差距可能仍然很大。此外,如今的初创公司(OpenAI、Anthropic、AI21 Labs 等)比学术界拥有更多资源,因此有能力训练最大规模的基础模型(例如 OpenAI 的 GPT-3)。
缩小资源缺口的一种方法是 政府 将其视为公共基础设施进行 投资。美国最新的 National Research Cloud 计划就是朝这个方向迈出的一步。
志愿计算 可以作为另一种 补充方案,该方案中数十亿计算设备(节点)中的任何一个都可以连接到中央服务器贡献算力。但是,节点之间的高延迟连接以及训练基础模型的高带宽要求使其成为一个开放的技术挑战。
1.4、概述

2、能力(Capabilities)
3、应用(Applications)
3.1、医疗保健和生物医学

3.2、法律

3.3、教育
教育领域的基础模型可以在多个数据源上进行训练,以学习教育所需的能力:对各种主题的理解和不同的教学技术。这些基础模型可以以通用的方式应用于一系列的任务和目标,如了解学生、协助教师和生成教育内容。如下图所示:

该图说明了一个将各种模态(图像、语音、手势、文字)和语言的信号嵌入一个通用的特征空间的系统。这样一个特征空间允许思想在不同的模态和语言之间被联系起来。与教学相关的链接类型包括类比(不同语言间的相似性)和对比(不同语言间的不同概念),这两种类型都可以发生在同一模态或不同模态间。
4、技术(Technology)
4.4、
4.5、
4.6、
5、社会影响(Society)

定义:基础模型的社会影响
The societal impact of foundation models, referring both to the construction of the models themselves and their role in developing applications, requires careful examination(需要被仔细检查)。
5.1、不公平与公平(Inequity and fairness)
使用包含有偏见的训练源(training bias sources)来训练基础模型,会不可避免地导致基础模型存在一定的内在偏见(intrinsic biases)。而在基础模型迁移(adaptation)到下游任务的过程中,这种内在偏见会变现为用户受到的外在伤害(extrinsic harms)。如下图所示:
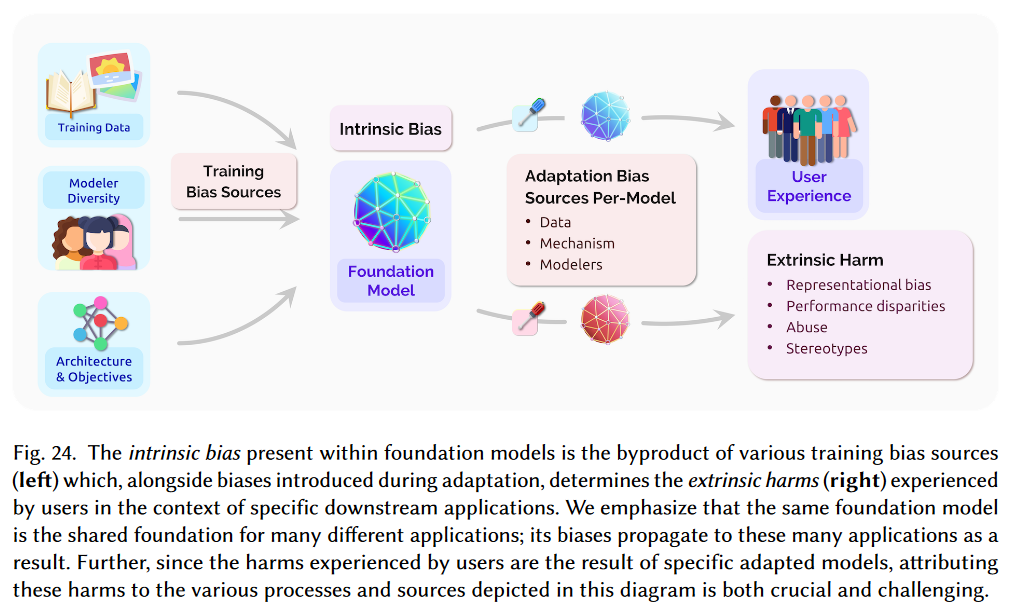
具体来说,有偏见的训练源主要包含以下三个方面:
训练数据(Data)
模型多样性(Modelers Diversity)
建模决策(Modeling,Mechanism)
模型结构(model architecture)
训练目标(training objective)
迁移方法(adaptation method)
而具体的外部伤害有四个方面:
表示的偏见(representation bias)
- 例如,信息检索系统对黑人女性的性描述
滥用(abuse)
- 基于基础模型的对话有毒内容攻击
刻板印象(stereotypes)
性能差距(performance disparities)
- 例如,基础模型无法检测到肤色较深的人的脸部
基础模型可以通过产生不公平的结果,将技术的负面影响分配给被边缘化的人,从而加剧现有的不平等现象。
因此,我们需要采取主动(proactive methods)+ 被动(reactive methods)两种方式来减轻、解决基础模型可能造成的不平等现象。
具体来说,通常使用 主动干预(intervention) 的主动方法,再结合 追溯(recourse) 的被动方法,来减轻、解决基础模型的不平等现象。
5.2、滥用(Misuse)
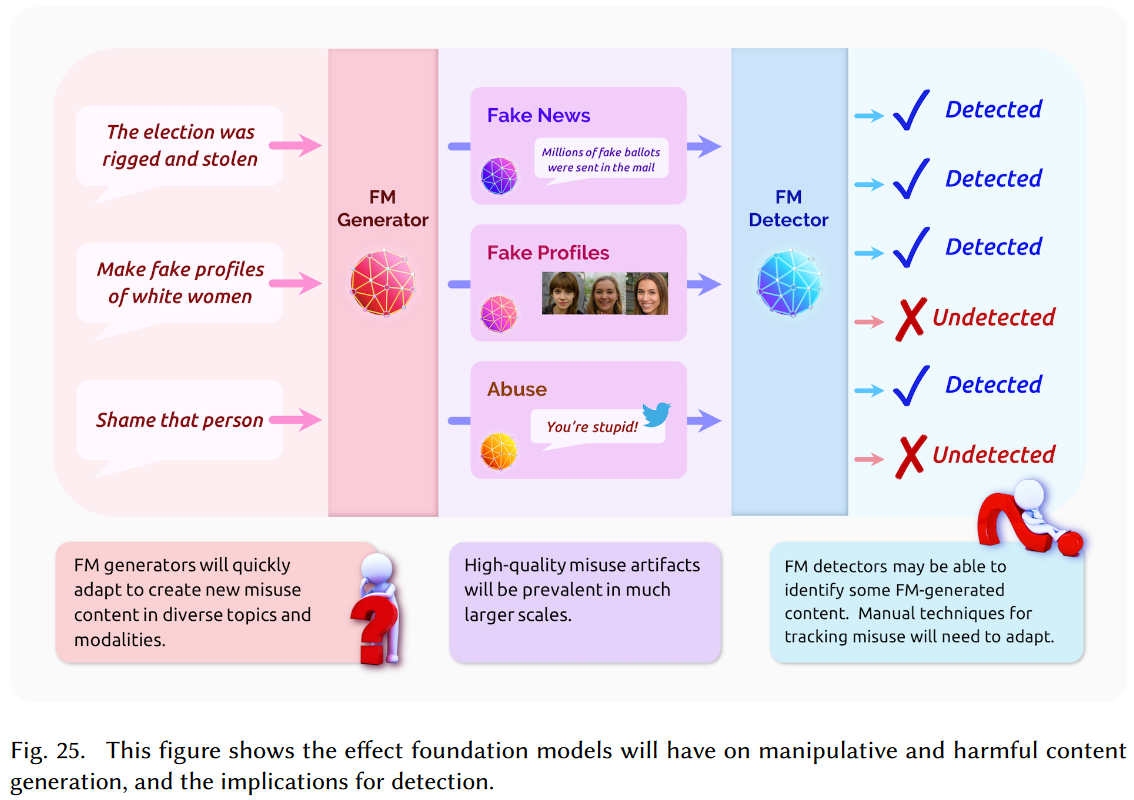
基于基础模型(FM)的生成器(Generator)将快速适应在不同的主题和模式中创建新的滥用内容,例如:
选举被操纵和窃取(The election was rigged and stolen)
制作白人女性的假资料(Make fake profiles of white women)
羞辱某个人(Shame that person)
基于基础模型的检测器(Detector)可能能够识别某些 FM 生成的内容,但是也可能检测不到(可能需要进行迁移)。
5.3、环境(Environment)
部署基础模型的成本-效益分析(cost-benefit analysis)如下图所示:
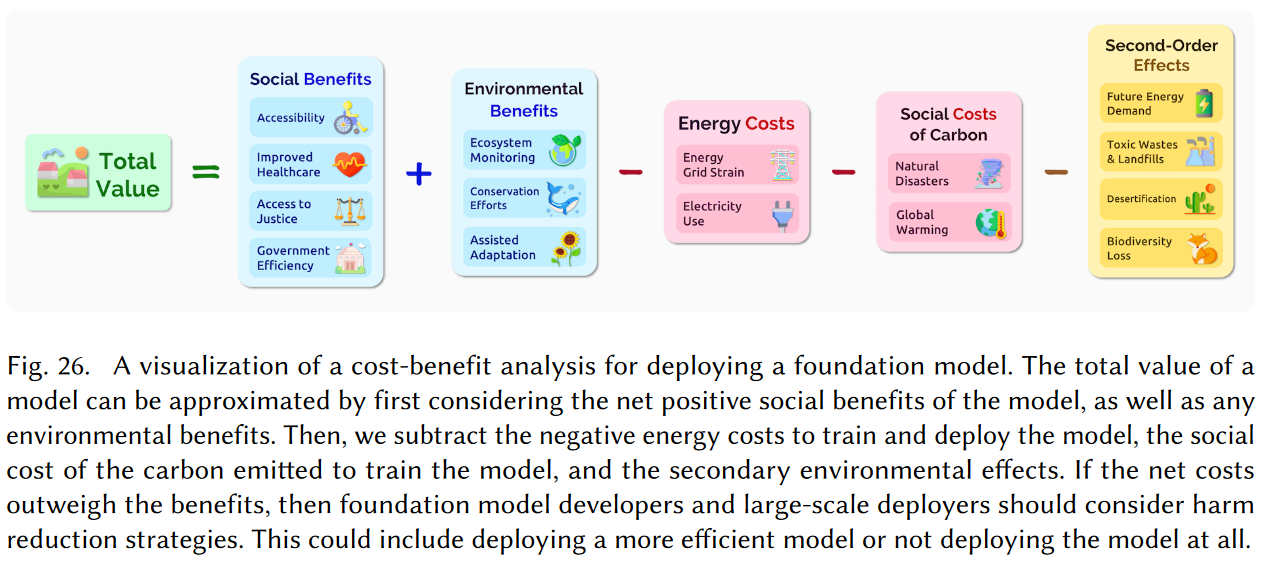
总收益 = 模型的社会效益 + 环境效益 - 能量消耗 - 碳排放带来的社会成本 - 二次环境影响
5.4、合法性(Legality)
5.5、经济(Economics)
5.6、伦理(Ethics)
参考
哈工大 SCIR 译文:基础模型的机遇与风险(共八个部分)
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/17/survey-of-foundation-model/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)