PEFT 动机
基于 Transformers 架构的大型语言模型(LLM),如 GPT、T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了最先进的结果。此外,还开始涉足其他领域,例如计算机视觉(VIT、Stable Diffusion、LayoutLM)和音频(Whisper、XLS-R)。传统的范式是对通用网络规模数据进行大规模预训练,然后对下游任务进行微调。与使用开箱即用的预训练 LLM(例如,零样本推理)相比,在下游数据集上微调这些预训练 LLM 会带来巨大的性能提升。
参数高效微调(PEFT)方法旨在解决下面两个问题:
随着模型变得越来越大,在消费级硬件上对模型 进行全部参数的微调变得不可行。
此外,为每个下游任务独立存储和部署微调模型变得 非常昂贵,因为微调模型与原始预训练模型的大小相同。
PEFT 方法仅 微调少量(额外)模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。这也 克服了灾难性遗忘的问题,这是在 LLM 的全参数微调期间观察到的一种现象。
PEFT 方法也显示出在低数据状态下比微调更好,可以 更好地泛化到域外场景。它可以应用于各种模态,例如图像分类以及 Stable diffusion dreambooth。
PEFT 方法还有助于提高轻便性,其中用户可以使用 PEFT 方法调整模型,以获得与完全微调的大型检查点相比,大小仅几 MB 的微小检查点。例如, bigscience/mt0-xxl 占用 40GB 的存储空间,全参数微调将导致每个下游数据集有对应 40GB 检查点。而使用 PEFT 方法,每个下游数据集只占用几 MB 的存储空间,同时实现与全参数微调相当的性能。来自 PEFT 方法的少量训练权重被添加到预训练 LLM 顶层。因此,同一个 LLM 可以通过添加小的权重来用于多个任务,而无需替换整个模型。
统计可训练的参数量
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
peft
State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods
LoRA
使用 HuggingFace peft 来进行 LoRA 微调,具体的例子如下所示:
$pip install transformers
$pip install peft
from transformers import BertForMaskedLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bert-base-uncased"
tokenizer_name_or_path = "bert-base-uncased"
peft_config = LoraConfig(
# task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
原始模型的信息如下:
model = BertForMaskedLM.from_pretrained(
model_name_or_path
)
for name, param in model.named_parameters():
print(name, ":", param.shape)
"""
bert.embeddings.word_embeddings.weight : torch.Size([30522, 768])
bert.embeddings.position_embeddings.weight : torch.Size([512, 768])
bert.embeddings.token_type_embeddings.weight : torch.Size([2, 768])
bert.embeddings.LayerNorm.weight : torch.Size([768])
bert.embeddings.LayerNorm.bias : torch.Size([768])
bert.encoder.layer.0.attention.self.query.weight : torch.Size([768, 768])
bert.encoder.layer.0.attention.self.query.bias : torch.Size([768])
bert.encoder.layer.0.attention.self.key.weight : torch.Size([768, 768])
bert.encoder.layer.0.attention.self.key.bias : torch.Size([768])
bert.encoder.layer.0.attention.self.value.weight : torch.Size([768, 768])
bert.encoder.layer.0.attention.self.value.bias : torch.Size([768])
bert.encoder.layer.0.attention.output.dense.weight : torch.Size([768, 768])
bert.encoder.layer.0.attention.output.dense.bias : torch.Size([768])
bert.encoder.layer.0.attention.output.LayerNorm.weight : torch.Size([768])
bert.encoder.layer.0.attention.output.LayerNorm.bias : torch.Size([768])
bert.encoder.layer.0.intermediate.dense.weight : torch.Size([3072, 768])
bert.encoder.layer.0.intermediate.dense.bias : torch.Size([3072])
bert.encoder.layer.0.output.dense.weight : torch.Size([768, 3072])
bert.encoder.layer.0.output.dense.bias : torch.Size([768])
bert.encoder.layer.0.output.LayerNorm.weight : torch.Size([768])
bert.encoder.layer.0.output.LayerNorm.bias : torch.Size([768])
...
"""
经过 LoRA 改造之后的模型信息如下:
peft_model = get_peft_model(model, peft_config)
for name, param in peft_model.named_parameters():
print(name, ":", param.shape)
"""
base_model.model.bert.embeddings.word_embeddings.weight : torch.Size([30522, 768])
base_model.model.bert.embeddings.position_embeddings.weight : torch.Size([512, 768])
base_model.model.bert.embeddings.token_type_embeddings.weight : torch.Size([2, 768])
base_model.model.bert.embeddings.LayerNorm.weight : torch.Size([768])
base_model.model.bert.embeddings.LayerNorm.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.self.query.weight : torch.Size([768, 768])
base_model.model.bert.encoder.layer.0.attention.self.query.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.self.query.lora_A.weight : torch.Size([8, 768])
base_model.model.bert.encoder.layer.0.attention.self.query.lora_B.weight : torch.Size([768, 8])
base_model.model.bert.encoder.layer.0.attention.self.key.weight : torch.Size([768, 768])
base_model.model.bert.encoder.layer.0.attention.self.key.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.self.value.weight : torch.Size([768, 768])
base_model.model.bert.encoder.layer.0.attention.self.value.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.self.value.lora_A.weight : torch.Size([8, 768])
base_model.model.bert.encoder.layer.0.attention.self.value.lora_B.weight : torch.Size([768, 8])
base_model.model.bert.encoder.layer.0.attention.output.dense.weight : torch.Size([768, 768])
base_model.model.bert.encoder.layer.0.attention.output.dense.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.weight : torch.Size([768])
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.intermediate.dense.weight : torch.Size([3072, 768])
base_model.model.bert.encoder.layer.0.intermediate.dense.bias : torch.Size([3072])
base_model.model.bert.encoder.layer.0.output.dense.weight : torch.Size([768, 3072])
base_model.model.bert.encoder.layer.0.output.dense.bias : torch.Size([768])
base_model.model.bert.encoder.layer.0.output.LayerNorm.weight : torch.Size([768])
base_model.model.bert.encoder.layer.0.output.LayerNorm.bias : torch.Size([768])
...
"""
PeftType 和 TaskType 的定义如下:
class PeftType(str, enum.Enum):
PROMPT_TUNING = "PROMPT_TUNING"
P_TUNING = "P_TUNING"
PREFIX_TUNING = "PREFIX_TUNING"
LORA = "LORA"
ADALORA = "ADALORA"
class TaskType(str, enum.Enum):
SEQ_CLS = "SEQ_CLS"
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"
CAUSAL_LM = "CAUSAL_LM"
TOKEN_CLS = "TOKEN_CLS"
LoraConfig 的定义如下所示:
class LoraConfig(PeftConfig):
"""
This is the configuration class to store the configuration of a [`LoraModel`].
Args:
r (`int`): Lora attention dimension.
target_modules (`Union[List[str],str]`): The names of the modules to apply Lora to.
lora_alpha (`float`): The alpha parameter for Lora scaling.
lora_dropout (`float`): The dropout probability for Lora layers.
fan_in_fan_out (`bool`): Set this to True if the layer to replace stores weight like (fan_in, fan_out).
For example, gpt-2 uses `Conv1D` which stores weights like (fan_in, fan_out) and hence this should be set to `True`.:
bias (`str`): Bias type for Lora. Can be 'none', 'all' or 'lora_only'
modules_to_save (`List[str]`):List of modules apart from LoRA layers to be set as trainable
and saved in the final checkpoint.
"""
r: int = field(default=8, metadata={"help": "Lora attention dimension"}) # 默认值 8
target_modules: Optional[Union[List[str], str]] = field(
default=None,
metadata={
"help": "List of module names or regex expression of the module names to replace with Lora."
"For example, ['q', 'v'] or '.*decoder.*(SelfAttention|EncDecAttention).*(q|v)$' "
},
) # 默认值 None
lora_alpha: int = field(default=None, metadata={"help": "Lora alpha"}) # 默认值 None
lora_dropout: float = field(default=None, metadata={"help": "Lora dropout"}) # 默认值 None
fan_in_fan_out: bool = field(
default=False,
metadata={"help": "Set this to True if the layer to replace stores weight like (fan_in, fan_out)"},
) # 默认值 False
bias: str = field(default="none", metadata={"help": "Bias type for Lora. Can be 'none', 'all' or 'lora_only'"}) # m默认值 none
modules_to_save: Optional[List[str]] = field(
default=None,
metadata={
"help": "List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint. "
"For example, in Sequence Classification or Token Classification tasks, "
"the final layer `classifier/score` are randomly initialized and as such need to be trainable and saved."
},
)
init_lora_weights: bool = field(
default=True,
metadata={"help": "Whether to initialize the weights of the Lora layers."},
)
打印模型的参数量信息
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"""
output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
"""
inference_mode 设置
LoraConfig 中的 inference_mode 默认值是 False,表示模型的 requires_grad 都是 True。如果将 inference_mode 设置为 True,则只有 LoRA 等 PEFT 方法对应的 modules 的 requires_grad 是 True,其他的都为 False。如下所示:
from transformers import BertForMaskedLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bert-base-uncased"
peft_config = LoraConfig(
# task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=True, # 设置为 True
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = BertForMaskedLM.from_pretrained(
model_name_or_path
)
for name, param in peft_model.named_parameters():
print(name, ":", param.shape, "/", param.requires_grad)
"""
base_model.model.bert.embeddings.word_embeddings.weight : torch.Size([30522, 768]) / False
base_model.model.bert.embeddings.position_embeddings.weight : torch.Size([512, 768]) / False
base_model.model.bert.embeddings.token_type_embeddings.weight : torch.Size([2, 768]) / False
base_model.model.bert.embeddings.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.embeddings.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.lora_A.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.query.lora_B.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.lora_A.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.lora_B.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.weight : torch.Size([3072, 768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.bias : torch.Size([3072]) / False
base_model.model.bert.encoder.layer.0.output.dense.weight : torch.Size([768, 3072]) / False
base_model.model.bert.encoder.layer.0.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.LayerNorm.bias : torch.Size([768]) / False
...
"""
LoRA 应用的位置
原始的 LoRA 论文 只将 LoRA 应用到 \(W_q, W_v\) 这两个参数权重矩阵中,peft 默认也是将 LoRA 应用到 Query 和 Key 中,可以参考上面的 LoRA 代码。但是,AdaLoRA 论文 中通过实验表明,将 LoRA 应用到所有的参数权重矩阵中(包括 \(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\)),可以进一步提升模型性能。
在 peft 中,可以通过 target_modules 来确定 LoRA 应用的位置,可以通过下面的代码将 LoRA 应用到所有的参数权重矩阵中:
from transformers import BertForMaskedLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bert-base-uncased"
tokenizer_name_or_path = "bert-base-uncased"
peft_config = LoraConfig(
# task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
target_modules=["query", "key", "value", "dense"],
lora_alpha=32,
lora_dropout=0.1
)
model = BertForMaskedLM.from_pretrained(
model_name_or_path
)
peft_model = get_peft_model(model, peft_config)
for name, param in peft_model.named_parameters():
print(name, ":", param.shape, "/", param.requires_grad)
"""
base_model.model.bert.embeddings.word_embeddings.weight : torch.Size([30522, 768]) / False
base_model.model.bert.embeddings.position_embeddings.weight : torch.Size([512, 768]) / False
base_model.model.bert.embeddings.token_type_embeddings.weight : torch.Size([2, 768]) / False
base_model.model.bert.embeddings.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.embeddings.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.lora_A.default.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.query.lora_B.default.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.lora_A.default.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.lora_B.default.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.lora_A.default.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.lora_B.default.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.lora_A.default.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.lora_B.default.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.weight : torch.Size([3072, 768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.bias : torch.Size([3072]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.lora_A.default.weight : torch.Size([8, 768]) / True
base_model.model.bert.encoder.layer.0.intermediate.dense.lora_B.default.weight : torch.Size([3072, 8]) / True
base_model.model.bert.encoder.layer.0.output.dense.weight : torch.Size([768, 3072]) / False
base_model.model.bert.encoder.layer.0.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.dense.lora_A.default.weight : torch.Size([8, 3072]) / True
base_model.model.bert.encoder.layer.0.output.dense.lora_B.default.weight : torch.Size([768, 8]) / True
base_model.model.bert.encoder.layer.0.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.LayerNorm.bias : torch.Size([768]) / False
...
"""
LoRA Bias
The weight matrix is scaled by
lora_alpha/r, and a higher lora_alpha value assigns more weight to the LoRA activations.For performance, we recommend setting
biastoNonefirst, and thenlora_only, before tryingall.- 首先将
bias设置为"none",再设置为"lora_only",最后设置为"all"
- 首先将
Element-wise 操作
element-wise product = element-wise multiplication = Hadamard product
含义:两个矩阵对应位置元素进行乘积,如下图所示:
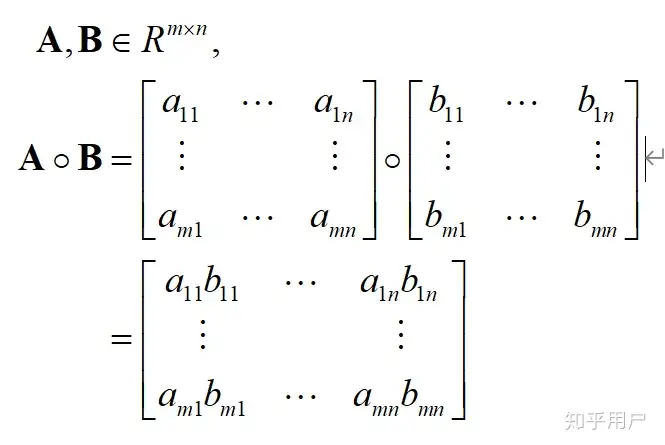
矩阵的 element-wise 操作可以理解为对两个矩阵中对应位置上的元素进行相同的操作,比如加法、减法、乘法、除法等。这些操作可以很自然地 并行化,使得计算速度得到提升。
具体地,我们可以将两个矩阵分别划分成若干个小块,每个小块内部的元素可以同时进行操作,从而实现并行化。这里需要注意的是,在矩阵的 element-wise 操作中,每个元素之间都是互相独立的,因此可以并行计算,不需要考虑数据之间的依赖关系。
下面以矩阵加法为例进行说明。假设有两个矩阵 \(A\) 和 \(B\),它们的大小均为 \(m\times n\)。为了并行化,我们可以将每个矩阵划分成 \(p\times q\) 个小块,每个小块的大小为 \((m/p)\times (n/q)\),其中 \(p\) 和 \(q\) 都应该是整数。这样,两个矩阵就可以被分成共 \(p\times q\) 个小块,每个小块内的元素可以并行地进行相加操作。
在实际运算中,我们可以利用多线程或者分布式计算等技术来实现这种并行化操作。例如,在使用多线程时,可以将每个小块的计算分配给不同的线程来完成,从而实现并行化计算。在使用分布式计算时,可以将每个小块分配给不同的计算节点来完成,并集成到整体计算中。这些技术的实现细节需要根据具体的应用场景和系统架构进行设计和优化。
总之,矩阵的 element-wise 操作可以很自然地实现并行化,从而提高计算的效率和速度。
AdaLoRA
《Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning》
URL:https://arxiv.org/abs/2303.10512
Official Code:https://github.com/QingruZhang/AdaLoRA
会议:ICLR 2023
单位:佐治亚理工学院 & 微软
论文
论文中的 final total rank / budget 预算 \(b^{(T)}\) of AdaLoRA from \(\{72, 144, 288, 576\}\)
由于 AdaLoRA 针对 \(W_q, W_k, W_v, W_o, W_{f_1}, W_{f_2}\) 的参数矩阵进行 SVD 分解,因此共需要对这 6 个参数矩阵进行分解。
针对 DeBERTaV3-base 模型(12 layers、12 heads、768 hidden dimension):
总预算 72:\(72 / 6 / 12 = 1\)
相当于模型中每个参数权重的秩最多为 1,即 \(r \le 1\)
相当于 LoRA 中 \(r = 1\) 的场景
总预算 144:\(144 / 6 / 12 = 2\)
相当于模型中每个参数权重的秩最多为 2,即 \(r \le 2\)
相当于 LoRA 中 \(r = 2\) 的场景
总预算 288:\(72 / 6 / 12 = 4\)
相当于模型中每个参数权重的秩最多为 4,即 \(r \le 4\)
相当于 LoRA 中 \(r = 4\) 的场景
总预算 576:\(72 / 6 / 12 = 8\)
相当于模型中每个参数权重的秩最多为 8,即 \(r \le 8\)
相当于 LoRA 中 \(r = 8\) 的场景
AdaLoRA 最终的 rank 分配结果如下图所示:
![]()
作者发现:AdaLoRA 总是倾向于将更多的预算分配给 FFN 和顶层。这种行为与我们在下图中得出的经验结论一致,即 FFN 模型和顶层的权重矩阵对于模型性能更为重要。因此,它验证了我们提出的重要性指标可以指导 AdaLoRA 专注于关键模块。
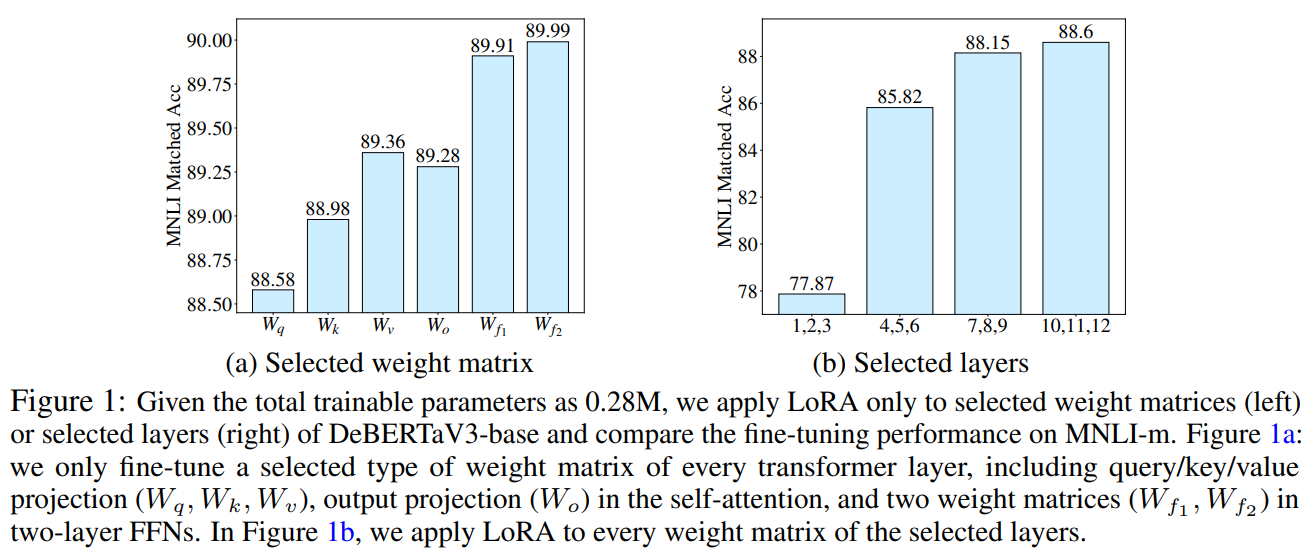
同时,AdaLoRA 生成的排名分布在不同的预算水平、任务和模型中是一致的。这意味着剩余参数的数量与 \(b^{(T)}\) 成线性比例关系,因此我们可以调整 \(b^{(T)}\) 来控制剩余参数。
如第 1 节所述,调整秩自然是在低秩自适应的情况下控制参数预算。因此,我们将预算 \(b^{(t)}\) 定义为所有增量矩阵的总秩,即总奇异值的数量。回想一下,预算分配是在微调期间迭代进行的。为了促进模型的训练,我们提出了一个 全球预算调度程序。具体来说,我们从略高于目标预算 \(b^{(T)}\) 的初始预算 \(b^{(0)}\) 开始(例如,\(b^{(T)}\) 的 1.5 倍)。我们将每个增量矩阵的初始秩设置为 \(r = b^{(0)}/n\)。我们预热 \(t_i\) 步的训练,然后按照立方计划减少预算 \(b^{(t)}\) 直到达到 \(b^{(T)}\)。最后,我们修复了最终的预算分配并微调 \(t_f\) 步骤的模型。预算表的确切方程式在附录 A 中给出。这允许 AdaLoRA 首先探索参数空间,然后再关注最重要的权重。
LoRA 通过 \(α/r\) 缩放 \(Δx\),其中 \(α\) 是 \(r\) 中的常数。结果,在给定不同的 \(r\) 的情况下,输出的大小可以保持一致。当改变 \(r\) 时,它减少了重新调整学习率的努力。通常 \(α\) 设置为 16 或 32,并且从未调整过(Hu et al., 2022; Yang & Hu, 2020)。在 LoRA 之后,我们为 (3) 式添加与 LoRA 相同的缩放比例并将 \(α\) 固定。此外,在算法 1 中,我们 每隔 \(ΔT\) 步骤(例如,\(ΔT = 100\))修剪奇异值,这样修剪后的三元组仍然可以在这些间隔内得到更新,并可能在未来的迭代中重新激活。
应用到 Query、Value
应用到所有 Weight Matrix
import torch
from transformers import BertForMaskedLM
from peft import get_peft_config, get_peft_model, AdaLoraConfig, TaskType
model_name_or_path = "bert-base-uncased"
tokenizer_name_or_path = "bert-base-uncased"
# 使用默认配置
peft_config = AdaLoraConfig(
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "key", "value", "dense"]
)
model = BertForMaskedLM.from_pretrained(
model_name_or_path
)
peft_model = get_peft_model(model, peft_config)
for name, param in peft_model.named_parameters():
print(name, ":", param.shape, "/", param.requires_grad)
"""
base_model.model.bert.embeddings.word_embeddings.weight : torch.Size([30522, 768]) / False
base_model.model.bert.embeddings.position_embeddings.weight : torch.Size([512, 768]) / False
base_model.model.bert.embeddings.token_type_embeddings.weight : torch.Size([2, 768]) / False
base_model.model.bert.embeddings.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.embeddings.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.query.lora_A.default : torch.Size([12, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.query.lora_B.default : torch.Size([768, 12]) / True
base_model.model.bert.encoder.layer.0.attention.self.query.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.attention.self.query.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.key.lora_A.default : torch.Size([12, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.lora_B.default : torch.Size([768, 12]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.attention.self.key.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.self.value.lora_A.default : torch.Size([12, 768]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.lora_B.default : torch.Size([768, 12]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.attention.self.value.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.weight : torch.Size([768, 768]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.dense.lora_A.default : torch.Size([12, 768]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.lora_B.default : torch.Size([768, 12]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.attention.output.dense.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.attention.output.LayerNorm.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.weight : torch.Size([3072, 768]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.bias : torch.Size([3072]) / False
base_model.model.bert.encoder.layer.0.intermediate.dense.lora_A.default : torch.Size([12, 768]) / True
base_model.model.bert.encoder.layer.0.intermediate.dense.lora_B.default : torch.Size([3072, 12]) / True
base_model.model.bert.encoder.layer.0.intermediate.dense.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.intermediate.dense.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.output.dense.weight : torch.Size([768, 3072]) / False
base_model.model.bert.encoder.layer.0.output.dense.bias : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.dense.lora_A.default : torch.Size([12, 3072]) / True
base_model.model.bert.encoder.layer.0.output.dense.lora_B.default : torch.Size([768, 12]) / True
base_model.model.bert.encoder.layer.0.output.dense.lora_E.default : torch.Size([12, 1]) / True
base_model.model.bert.encoder.layer.0.output.dense.ranknum.default : torch.Size([1]) / False
base_model.model.bert.encoder.layer.0.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.0.output.LayerNorm.bias : torch.Size([768]) / False
...
base_model.model.bert.encoder.layer.11.output.LayerNorm.weight : torch.Size([768]) / False
base_model.model.bert.encoder.layer.11.output.LayerNorm.bias : torch.Size([768]) / False
base_model.model.cls.predictions.bias : torch.Size([30522]) / False
base_model.model.cls.predictions.transform.dense.weight : torch.Size([768, 768]) / False
base_model.model.cls.predictions.transform.dense.bias : torch.Size([768]) / False
base_model.model.cls.predictions.transform.dense.lora_A.default : torch.Size([12, 768]) / True
base_model.model.cls.predictions.transform.dense.lora_B.default : torch.Size([768, 12]) / True
base_model.model.cls.predictions.transform.dense.lora_E.default : torch.Size([12, 1]) / True
base_model.model.cls.predictions.transform.dense.ranknum.default : torch.Size([1]) / False
base_model.model.cls.predictions.transform.LayerNorm.weight : torch.Size([768]) / False
base_model.model.cls.predictions.transform.LayerNorm.bias : torch.Size([768]) / False
"""
adapter-transformers

A friendly fork of HuggingFace’s Transformers, adding Adapters to PyTorch language models
adapter-transformers是 HuggingFace 的 Transformers 库的扩展,它通过合并 AdapterHub(预训练适配器模块的中央存储库)将适配器集成到最先进的语言模型中。adapter-transformers可用作 HuggingFace Transformers 的 直接替代品,并定期同步 HuggingFace Transformers 新的上游更改。因此,此存储库中的大多数文件都是 HuggingFace Transformers 源的 直接副本,仅根据适配器实现所需的更改进行了修改。adapter-transformers目前支持 Python 3.8+ 和 PyTorch 1.12.1+。
安装
可以通过下面的方式进行安装:
pip install -U adapter-transformers
也可以通过 clone 仓库从源代码进行安装:
git clone https://github.com/adapter-hub/adapter-transformers.git
cd adapter-transformers
pip install .
更多
AdapterHub 主页:https://adapterhub.ml/
A central repository for pre-trained adapter modules
预训练适配器模块的中央存储库
adapter-transformers文档:https://docs.adapterhub.ml/
ChatGLM
参考
HuggingFace GitHub repo: peft
HuggingFace Blog:PEFT: 在低资源硬件上对十亿规模模型进行参数高效微调
HuggingFace PEFT 文档:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/16/peft-packages/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)