ChatGPT、GPT-4 带来了疯狂的三月,SAM、SegGPT 在 4 月带来了通用视觉的曙光。
疯狂的 2023 年,每一天都可能带来新的 AI “突破”。
SAM 和 SegGPT 几乎是 同时发布(2023.04.06) 的 通用图像分割基础模型,本文将介绍 SAM 这个模型,SegGPT 待后续再进行学习、更新。
Segment Anything
Our principal contributions are a new task (promptable segmentation), model (SAM), and dataset (SA-1B) that make this leap possible.

SAM(Segment Anything Model)
之前的分割模型是无法进行交互的,例如 “请把所有的苹果分割出来”。也就是说,Prompt 提供了人与模型交互的平台
大模型特征提取能力、通用能力非常强!必须要有交互!
ChatGPT 流行起来的原因之一:有交互性、有上下文(能一定的记忆)
视觉大模型中的 “大”:说的是包罗万象的大,不一定就是模型规模的大(SAM 在本地机就能跑起来)
SAM 还告诉我们一件事:视觉大模型的结构可以很简单,方法/算法可以很简单,那需要的究竟是什么呢?训练数据
视觉大模型首先在分割领域出现,有点不可思议。因为CV领域中目标检测需要的标注会更加简单(只需要标出物体的一个框)(以为视觉大模型会首先在目标检测领域出现),而分割则需要对物体进行更精确的标注。
一个物体的分割标注就是一个 Mask
1、Abstract
data collection loop(数据收集的循环)-> 人工标注一些,剩下的使用计算机(AI)来标注,最终得到包含有超过 1B 个 Mask、11M 张 Image 的 SA-1B 数据集,这比现有的任何分割数据集多 400 倍的 Mask。
transfer zero-shot to new image distributions and tasks
这种 zero-shot 的能力甚至比你专门的有监督模型的能力还要强
Facebook 全部公开(模型权重、数据集、生成数据集的方法)
2、Introduction
主要三个部分的内容:
Task:什么样的任务能够实现 Zero-Shot Transfer?
Model:需要什么样的模型架构?
Data:哪些数据可以为 Task 和 Model 提供支持?
遇到的最大问题:数据量不够
“牛生牛” -> “数据生数据” -> 自监督
10 亿 Mask 中可能仅有 500 万是人工校正的,其他都是 AI 标注的(一点一点迭代式生成)
以前的工作可能是针对一个小点去做的,例如解决遮挡现象、光照问题,而现在的人工智能是去解决所有问题(至少是一大类问题)
By separating SAM into an image encoder and a fast prompt encoder / mask decoder, the same image embedding can be reused (and its cost amortized) with different prompts.
fast prompt encoder:将 Prompt(Position、Rectangle/Box、Text 等)Embedding 成一个向量 Position:(0, 3) Rectangle/Box:左上角和右下角 这里 fast 的原因:需要进行用户交互,需要速度快!(50 ms)
mask decoder 与之前的工作 MaskFormer 很像
为了解决可能出现的歧义(ambiguity)问题,作者将模型设计为预测单个提示的多个 Mask。也就是说,给定一个 Prompt,SAM 会给出多个不同的 Mask 预测结果。
Data Engine
为了实现对新数据分布的强泛化,作者发现有必要在大量不同的掩码集上训练 SAM,而不是已经存在的任何分割数据集。
虽然现有的基础模型的数据大多是从网上获取的,但是对于分割任务而言显然不现实。因此,作者想出了一种替代方案——Data Engine。
Data Engine 共有三个阶段:
assisted-manual(助手,完全监督):【500 万+】
- 助手协助标注人员(annotators)进行 Mask 标注(交互式分割)
semi-automatic(半自动,半监督):【500 万+】
SAM 能够通过提示(可能的目标的位置)来自动生成 Mask
同时,标注人员专注于标注剩余的(没见过的)目标,以便提高 Mask 的多样性
fully automatic(全自动,自监督):
使用前景点的规则网格来提示 SAM
每张图片平均能产生大约 100 个高质量 Mask
3、Segment Anything Task
在 NLP 领域中,通常的基础模型是 next token prediction 在这一预训练任务中进行预训练的,然后通过 Prompt engineering 迁移到各种下游任务。
为了构建一个用于分割的基础模型,也需要定义一个类似的预训练任务。
将 Prompt 这个概念引入到分割任务中,可以是一些前景点、背景点,也可以是一些粗糙的 Box 或者 Mask,还可以是一些文本。更广泛的来说,Prompt 可以是任何能够指示要分割的内容/信息。
接着,作者定义了一个 promptable segmentation task:在给定任何提示的情况下,返回有效的分割 Mask(valid segmentation mask)。
We choose this task because it leads to a natural pre-training algorithm and a general method for zero-shot transfer to downstream segmentation tasks via prompting.
SAM 可以通过合适的 Prompt 迁移到下游分割任务。 分割是一个很宽泛的领域,包括有交互式分割、边缘检测、超像素化、目标提议生成、前景分割、语义分割、实例分割以及全景分割等。
SAM 这一 Promptable segment model 的目标是成为一个功能广泛的模型,能够通过提示工程适应现有和未来的分割任务。
这与现有的 多任务分割系统(multi-task segmentation systems)不同,
promptable segmentation model 可以作为一个组件,与其他模型进行组合(composition),从而解决目标任务。这类似于 CLIP 作为 DALL·E 图像生成系统中的文本图像对齐组件。
综上所述,prompting 和 composition 是强大的工具,可以对单个模型进行扩展,并解决原先模型无法解决的任务。
4、Segment Anything Model
4.1、Image Encoder
使用预训练的 MAE 模型(最低限度地)来处理高分辨率的输入图片。
The image encoder runs once per image and can be applied prior to prompting the model.
Image Encoder 只需要运行一次,就可以作为先验(prior)被 Prompt Encoder 反复使用。
4.2、Prompt encoder
作者考虑了两大类 Prompt:稀疏 (points, boxes, text) 和 稠密 (masks)。
points 和 boxes 表示为:position encoding + learnable embedding
text:CLIP text encoder
masks:convolutions embedding
所有的 Prompt 最终对会被编码成一个 256 维的向量。
选择 256 维 这个比较小的数目,是基于 实时交互 来进行考虑的。
4.3、Mask decoder
The mask decoder efficiently maps the image embedding, prompt embeddings, and an output token to a mask.
基本流程与 Maskformer 差不多
有一些不可思议的点:
Our modified decoder block uses prompt self-attention and cross-attention in two directions (prompt-to-image embedding and vice-versa) to update all embeddings.
- 双向的 Cross Attention
After running two blocks
作为一个视觉大模型,mask decoder 仅使用两个 blocks
目标检测模型 DETR 至少也使用了 6 个 block,并且效果一般
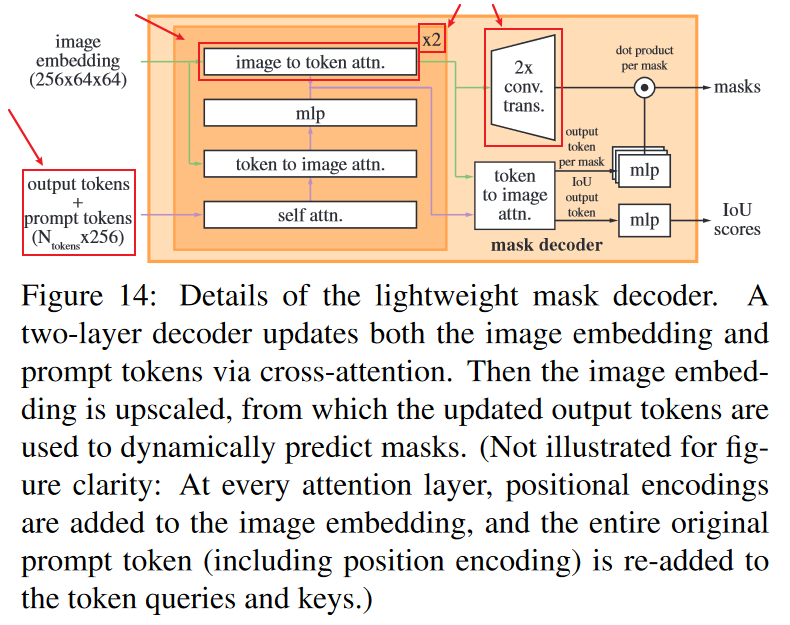
output_token: 0 号找飞机,1 号找坦克……
output_token 做 self-attention,0 号告诉其他人(1 号到 99 号)它要去找飞机,让其他人不要跟他抢
output_token-to-image embedding cross-attention:在image embedding 找到飞机token可能的位置
原始输入:1024x1024
Image Embedding:64x64
上采样之后:256x256(是原来图像大小的 1/4)
5、Segment Anything Data Engine
几个数据集在归一化之后的 mask 中心点的分布如下图所示:
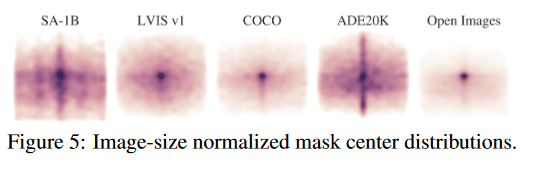
可以看出,SA-1B 的中心点分布涵盖更多地方,表明 SA-1B 中 mask 的数量和多样性更多、质量更好,而其他数据集(除了 ADE2K)的 mask 更加集中在位于中心的区域,多样性较差。
5.1、Assisted-manual stage
At the start of this stage, SAM was trained using common public segmentation datasets.
随着收集到的 masks 越来越多,image encoder 也从 ViT-B 转为 ViT-H,in total we retrained our model 6 times.
Overall, we collected 4.3M masks from 120k images in this stage.
5.2、Semi-automatic stage
这个阶段主要是提高 masks 的 多样性(diversity),从而提高模型 Segment Anything 的能力
首先使用模型自动得到一些 masks;
- 作者训练了一个 bounding box detector
然后向标注人员展示这些 masks,并要求标注人员对未给出的其他物体进行标注;
During this stage we collected an additional 5.9M masks in 180k images
作者在这一阶段对模型进行了 5 次重训练
5.3、Fully automatic stage
能够使用模型自动进行 mask 自动标注,作者认为可行的原因是:
在前面的两个阶段已经收集了大量的 masks 来改进模型(此时的模型已经是非常不错的)
开发了一个歧义感知的模型。即使是在模棱两可的情况下,模型也能给出有效的 mask
We applied fully automatic mask generation to all 11M images in our dataset, producing a total of 1.1B high-quality masks.
6、Segment Anything Dataset: SA-1B
11 M images, 1.1 B masks
Meta 还发布了一个图像注释数据集 Segment Anything 1-Billion (SA-1B),据称这是有史以来最大的分割数据集。该数据集可用于研究目的,并且 Segment Anything Model 在开放许可 (Apache 2.0) 下可用。


7、Segment Anything RAI Analysis
负责任的 AI(Responsible AI,RAI)
8、Zero-Shot Transfer Experiments
在五个任务上进行 Zero-Shot 实验,分别是:
Single Point Valid Mask Evaluation
Edge Detection(边缘检测)
Object Proposals
Instance Segmentation(实例分割)
Text-to-Mask (segmenting objects from free-form text)
9、Discussion
9.1、Foundation models(基础模型)
9.2、Compositionality(组合性)
可以向组件一样被组合到其他模型/系统中,具备很强的扩展性!
9.3、Limitations(局限性)
10、代码
github repo: segment-anything
更多
下面介绍一些 SAM 的二创。
Grounded-SAM
github repo: Grounded-Segment-Anything
![]()
Grouded-SAM 主要包含的功能有:
Grounded-SAM 的结构示意图如下图所示:


基础模型(Foundation Models)
《On the Opportunities and Risks of Foundation Models》
李飞飞 和 100 多位学者联名发表一份 200 多页的研究报告
具体的解读笔记参见:综述:基础模型(Foundation Models)
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/11/SAM/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)