语言模型是根据已知文本生成未知文本的模型。自 GPT-3 以来,大型语言模型展现出了惊人的 zero-shot 和 few-shot 能力,即不改变参数仅改变输入的 in-context learning。这是与此前流行的 finetune 范式截然不同的新范式。近期的 ChatGPT,更是让文本生成从以前人们眼中的玩具,逐渐展现出了生产力工具的潜质。
型语言模型的强大能力离不开其对知识的记忆:比如模型想要回答 "中国的首都是哪座城市?",就必须在某种意义上记住 "中国的首都是北京" 这个知识。Transformer 并没有外接显式的数据库,记忆只能隐式地表达在参数当中。
本文介绍的几篇文章指出,相比 Attention,不那么引人注意的 FFN (Feed Forward Network) 承担了 Transformer 中 记忆 的功能。
1、Key-Value Memory
《End to end memory networks》
URL:https://arxiv.org/abs/1503.08895
Official Code:https://github.com/facebookarchive/MemNN
会议:NeurIPS 2015
单位:Facebook
在模型训练时输入数据有三部分:一个连续的输入 \(x_1, x_2, x_3...\)(这部分相当于 doc 的内容,知识库),query \(q\),还有 answer \(a\)。
先是获取 \(\{x_i\}\) 与 query \(q\) 的一个表示(attention),然后这个表示经过多层的 MLP 网络,最后得到输出 answer \(a\)。最后再用 pred 与 \(a\) 的差值通过反向传播来不断训练模型。
论文作者提出了两种 Key-Value Memory 网络,包括:单层结构和多层结构,如下图所示。

矩阵 \(A \in {d\times V}\)
矩阵 \(B \in {d\times V}\)
1.1、单层结构
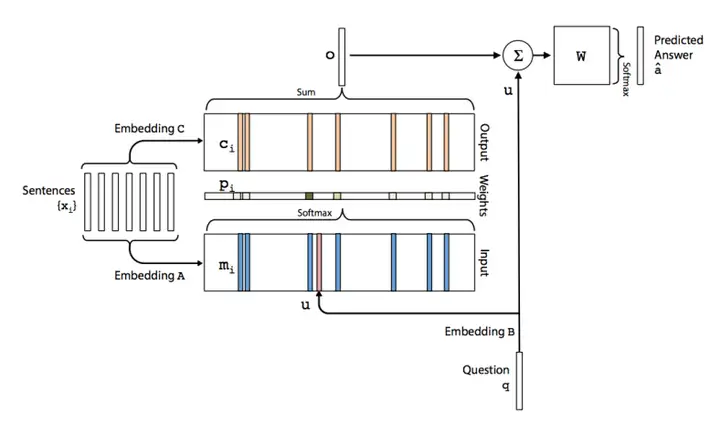
首先,将 Question 的句子级表示 \(q\) 通过 Embedding \(B\) 矩阵,得到向量表示 \(u\);
然后将 \(u\) 与 doc 中的每个词 \(m_i\) 进行内积运算,再经过 Softmax 层(进行归一化),得到 Attention 表示(Attention 具体含义是 query 对于 doc 中的每个词的注意力分配大小,即概率值)。
\[p_i = \text{Softmax}(u^T m_i)\]接着,得到 query “眼中” 的 doc 表示:将归一化后的概率值乘以 doc 表示:
\[o = \sum_i p_i c_i\]最终,将得到的 \(o\) (query 眼中的 doc 表示) 与 query 的 emb 相加后在经过一个 Softmax 层得到 answer 的 pred 值:
\[\hat{a} = \text{Softmax}(W(o + u))\]1.2、多层结构
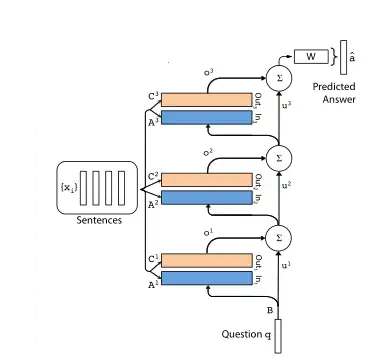
多层结构中每层的输入:
\[u^{k+1}=u^{k} +o^{k}\]其中,\(u^k\) 代表的是第 \(k\) 层的 query 的 emb 表示,而 \(o^k\) 表示的是第 \(k\) 层的 attention 后的输出。然后将他们加和得到第 \(k+1\) 层的输入(这里也不一定都要用加和的方式)。
在最后一层做预测时,将 \(u^{k+1}\) 经过 Softmax 处理后,再进行预测:
\[\hat{a} = \text{Softmax}(Wu^{k+1}) = \text{Softmax}(W(o^k + u^k))\]同时,作者探索了两种类型的多层结构:
相邻(Adjacent):\(A^{k+1}=C^K\)
RNN-like:\(A^1=A^2=...=A^K, C^1=C^2=...=C^K\)
论文中一般采用 3 跳网络邻接模型
2、 FFN 与 Key-Value Memory 的对应关系
在神经网络中添加记忆模块并不是一个新的想法。早在 2015 年的 End-To-End Memory Networks 中,就提出了 key-value memory的结构:将 个需要存储的信息分别映射为 维的key向量与value向量,query 向量与 memory 交互即为与 key、value 进行 Attention 操作。
对于 \(K,V \in R^{d_m\times d}\),有
\[\text{MN}(x) = \text{Softmax}(x\cdot K^T)\cdot V\]与 FFN 对比,对于 \(W_1, W_2 \in R^{d_m\times d}\),FFN 的形式为:
\[\text{FFN}(x) = f(x\cdot W_1^T)\cdot W_2\]可以看出,FFN 几乎与 key-value memory 相同。第一层权重对应 key 矩阵,第二层权重对应 value 矩阵,中间层维度对应 memory token 数量(或许是中间层维度需要较大的一种解释)。
唯一的区别在于 FFN 的激活函数并不要求归一化(即 不要求是 Softmax 函数)
3、FFN 中 key 与 value 的意义
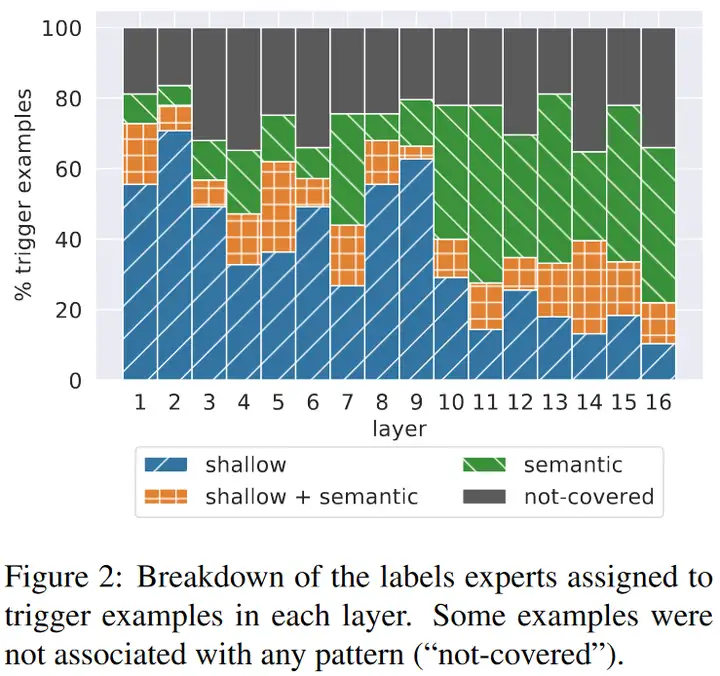
输入中的一些 pattern 会触发对应的 key。
对训练集中所有的 prefix 计算其对第 \(l\) 层第 \(i\) 个 key 的系数(\(f(x^l\cdot k_i^l)\)),对系数最大的 25 个 prefix 人工分析其共有的 pattern。
实验结果表明,每个 key 对应的 prefix 都可以找到至少一个其共有的 pattern。如下图所示,低层的 pattern 往往更 “浅”(如共同的结尾词),高层的 pattern 往往更具有语义性(如与 TV show 相关)。
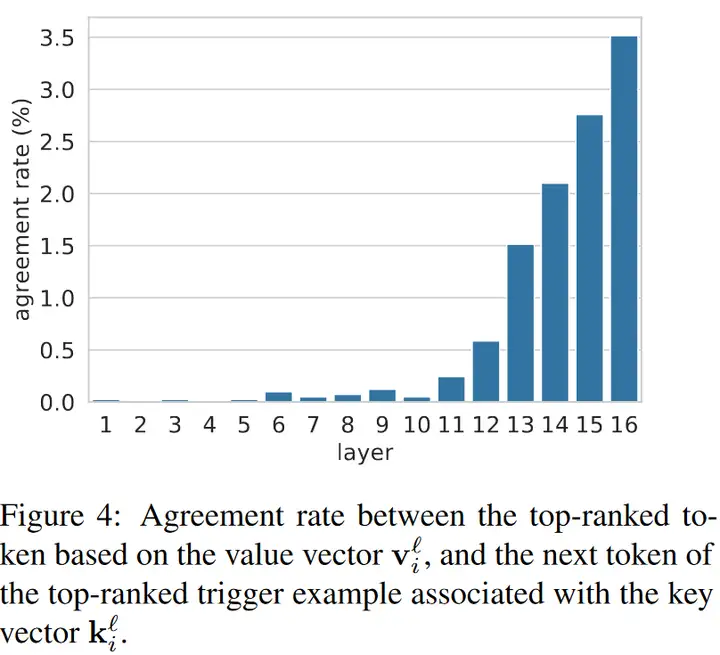
value 对应于输出词汇的分布,其倾向于补全对应 key 的 prefix 的下一个词。
对于输出 embedding 矩阵 \(E\),计算第 \(l\) 层第 \(i\) 个 value 对应的词汇分布(\(\text{Softmax}(v_i^l\cdot E)\)),统计分布中最大概率的单词与 prefix 的下一个词的 一致率。
如下图所示,低层的一致率几乎为 0,而高层的一致率迅速提高。这可能是因为高层的 embedding 空间更接近输出的 embedding 空间。
4、FFN 层内与层间的交互
FFN 不单是激活一个 key 及其 value,而是多个 value 的加权和。
FFN 的输出对应的词汇有超过 60% 的比例与该层任何一个 value 对应的词汇都不一致。
每一层的输出又进一步是 FFN 的输出与残差的组合,大部分时候,每层的输出与残差的输出一致(下图蓝色与黄色),有时同时不与残差与 FFN 一致,呈现出残差与 FFN 的组合(下图绿色),但几乎不会与 FFN 一致(下图中的红色与黄色)。
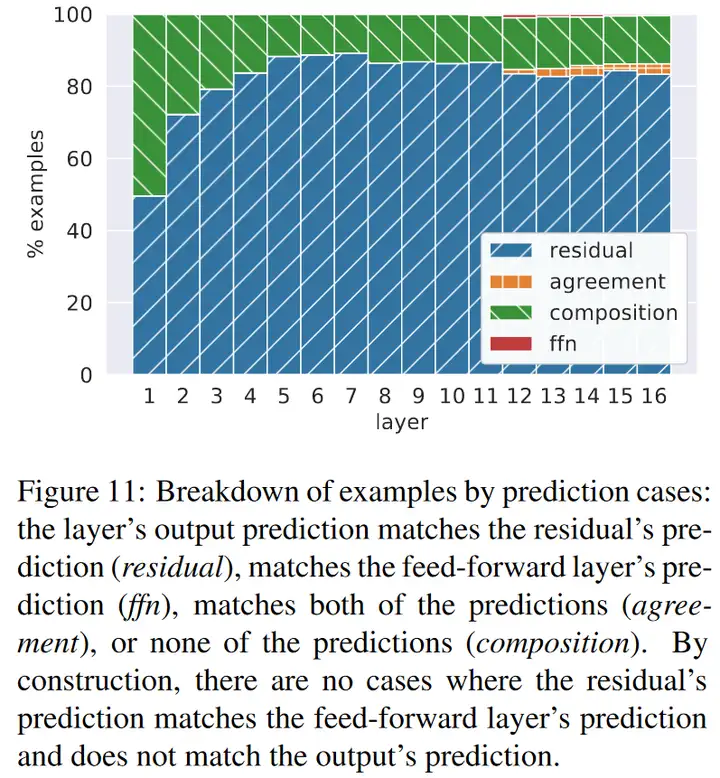
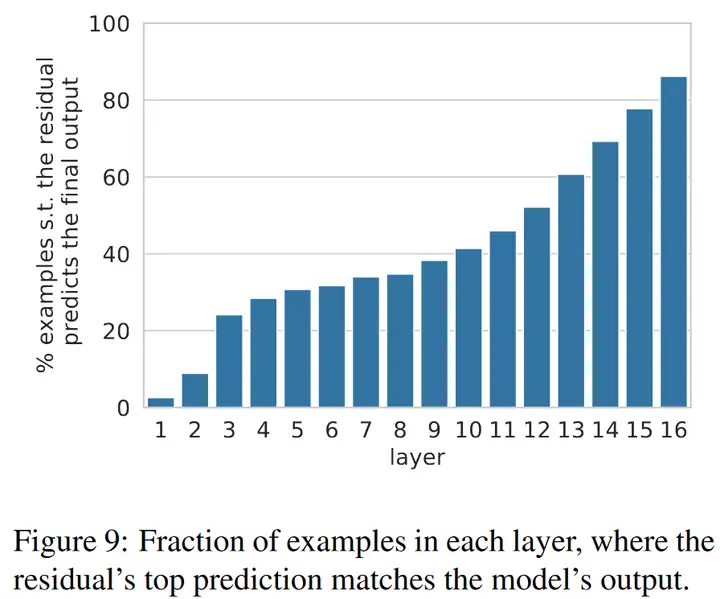
在各层之间,残差使得模型的输出被逐步改善。统计各层残差对应的词汇与最终输出的 一致率,在 低层 可以决定将近三分之一的最终输出,这可能对应 简单预测。而在 十层以后,一致率开始快速提高,这可能对应 困难预测。如下图所示:
5、应用
Knowledge Neurons in Pretrained Transformers 提出了一种关系类事实对应的 FFN 中间神经元的方法。其构造补全关系类事实的填空任务,用答案关于 FFN 中间神经元的 梯度 来确定存储知识的神经元,梯度大意味着该神经元对输出答案的影响大。
实验中,平均每个关系类事实对应 4.13 个知识神经元,同种关系的不同事实平均共享 1.23 个知识神经元,而不同关系几乎不共享知识神经元。
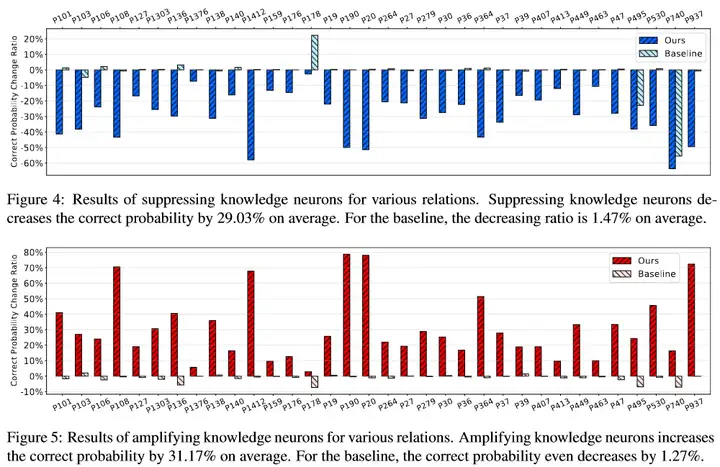
定位知识神经元以后就可以对相关神经元进行操作。如下图所示,将知识神经元的 激活置 0 或翻倍 可以有效 抑制或增强 相关知识的表达。在具体操作上,应避开同种关系共用的神经元,以减小对其他事实的影响。
6、VLMo 模型
《VLMO: Unifified Vision-Language Pre-Training with Mixture-of-Modality-Experts》
URL:https://arxiv.org/abs/2111.02358
单位:微软
Official Code:https://github.com/microsoft/unilm/tree/master/vlmo

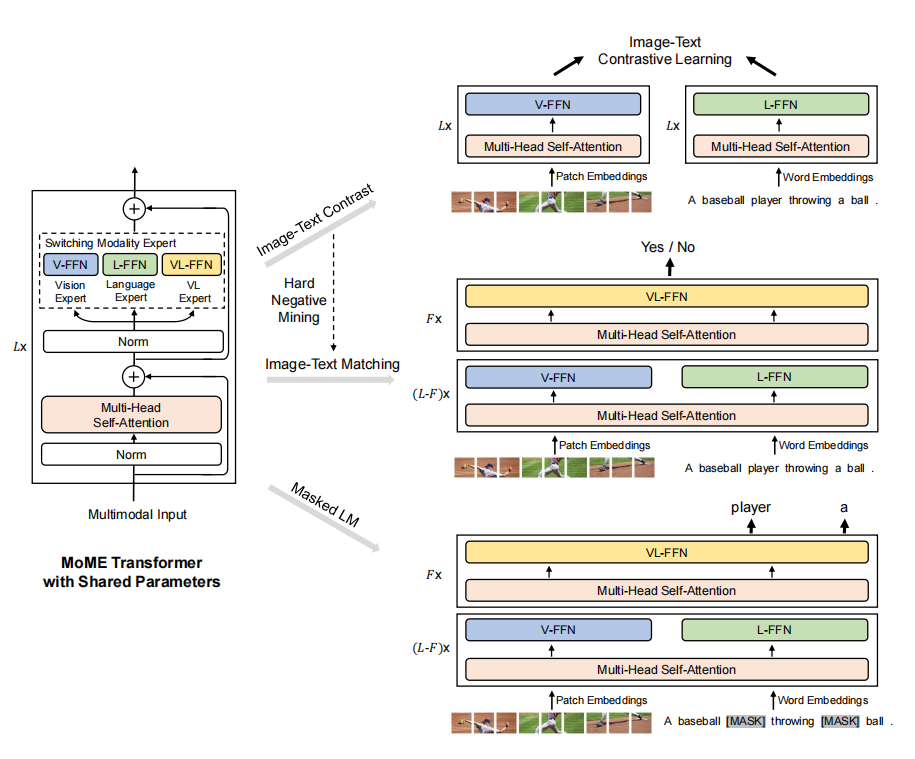
VLMo 模型使用 MoE (Mixture of Experts) 的思想,使用了三种不同的 FFN 网络,包括:V-FFN、L-FFN 以及 VL-FFN 来处理不同的模态数据,并且共享 Multi-Head Self-Attention 模块。
总结
End-To-End Memory Networks 一文提出了 End-To-End 的 Memory Network;
Transformer Feed-Forward Layers Are Key-Value Memories 一文指出了 FFN 的记忆作用;
Knowledge Neurons in Pretrained Transformers 一文给出了操作知识神经元的应用方式;
这些工作对于去除现有语言模型的错误知识,或将新知识注入现有语言模型可能带来帮助。
参考
论文:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/08/ffn-memory-in-transformer/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)