量变产生质变
Emergent Abilities of Large Language Models
《Emergent Abilities of Large Language Models》
URL:
https://arxiv.org/abs/2206.07682
https://openreview.net/forum?id=yzkSU5zdwD
会议:TMLR 2022
单位:Google Research、Stanford University、DeepMind

1、定义: 涌现能力
论文作者将大语言模型的涌现能力定义为:
An ability is emergent if it is not present in smaller models but is present in larger models.
如果一种能力不存在于较小的模型中,但存在于较大的模型中,我们称它为 涌现能力(Emergent Ability)。
Today’s language models have been scaled primarily along three factors: amount of computation (计算量), number of model parameters (参数量), and training dataset size (数据集大小).
作者主要分析了训练时计算量(FLOPs)对 LLM 性能的影响。
同时,由于更大的计算量往往也需要更多的参数量,因此,作者也分析了参数量对 LLM 性能的影响。
从作者给出的结果图也可以看出,训练时计算量对 LLM 性能的影响曲线与参数量对 LLM 性能的影响曲线基本一致,
- 训练数据集大小也是一个重要因素,但我们不会针对它来分析对 LLM 性能的影响,因为许多 LLM 都使用固定数量的训练示例。
注意:
LLM 不仅与上面三个因素有关,还包括稀疏的模型、基于 MoE (Mixture-of-Experts) 的模型等~
LLM 的涌现能力是由多个因素导致的,而非单一的因素造成
- 例如,即使 LLM 的参数量较小,但是使用了更高质量的数据集,也可以导致 LLM 涌现能力的出现
这篇论文的目标不是描述或声称观察涌现能力需要特定的量表 (scale),而是旨在讨论 先前工作中出现的 LLM 涌现行为。
下面将从 few-shot prompting 和 augmented prompting strategies 两方面进行介绍。
2、Few-Shot Prompted Tasks
本部分主要讨论在 prompting 范式下的 emergent abilities, 该范式如下图所示:
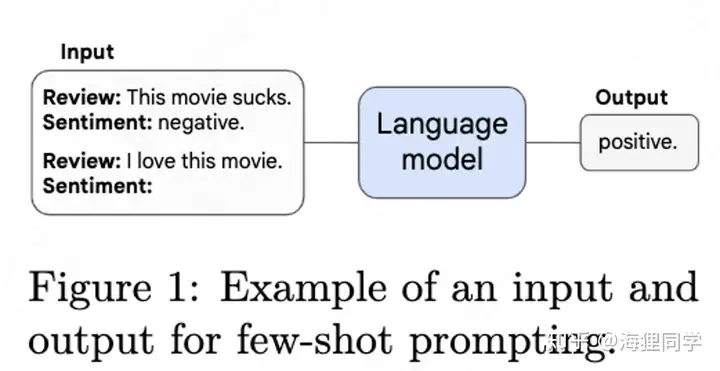
在达到一定规模之前语言模型只能达到随机性能,而当语言模型达到一定的规模之后,其性能显著提高 (远高于随机),通过小样本提示执行任务的能力就会出现。
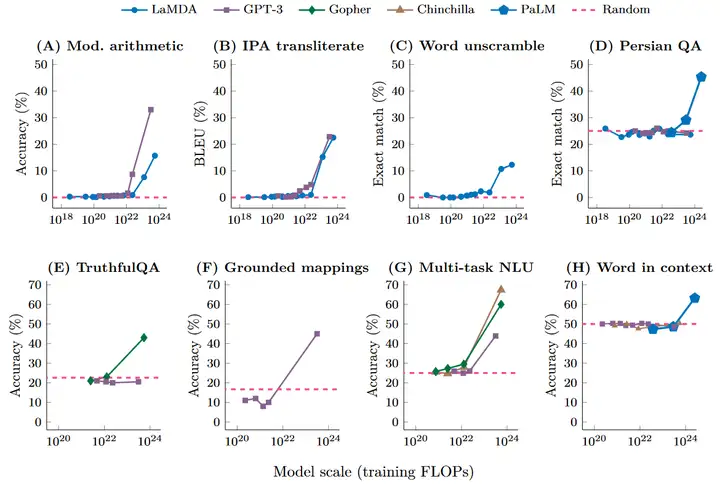
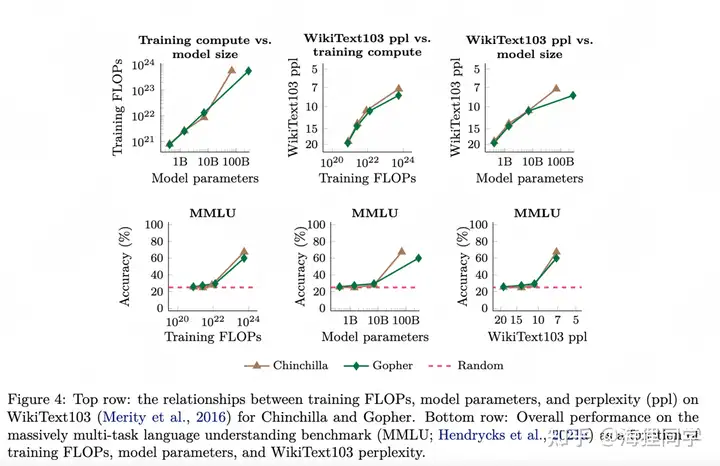
下图显示了来自不同工作的五个语言模型(LaMDA、GPT-3、Gopher、Chinchilla、PaLM)在八个 benchmark 上的能力。
3、Augmented Prompting Strategies
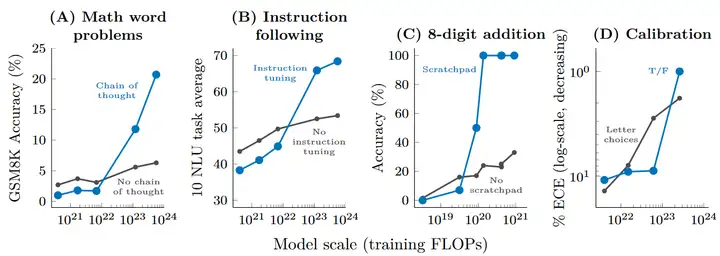
除了 few-shot prompting 以外,还有其他 prompting 或者 finetuning 策略可以进一步增加语言模型的能力。比如说对于涉及多步推理和计算的任务,如果让语言模型直接生成答案,往往效果不佳。但通过 prompting 时给出逐步思考的范例(chain of thought, CoT),亦或 finetune 模型来预测中间过程(scratchpad),都能大幅提高模型表现。
如下图所示,augmented prompting strategies 同样只在模型规模跨过一定阈值后起正面作用,对于小模型甚至起负面作用。
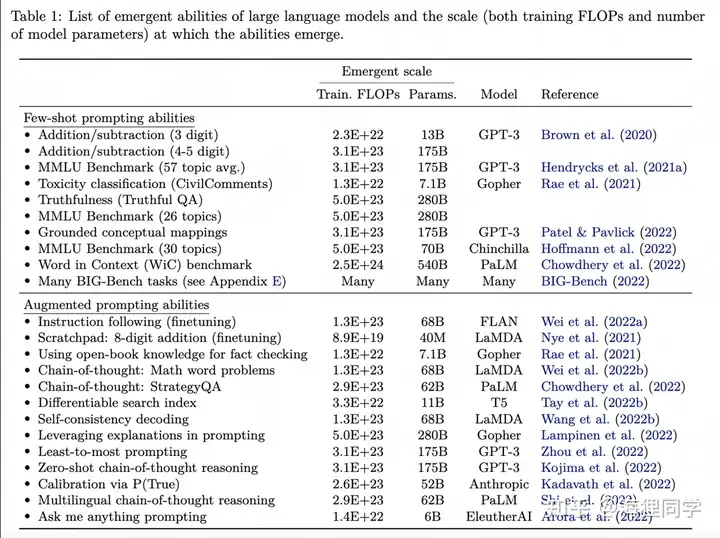
下表给出了 LLM 出现 emergent ablities 时的规模统计:
4、讨论
4.1、可能的解释
直觉上的解释:
对于一个多步推理任务,需要 \(l\) 个计算步骤,因此可能需要一个深度至少为 \(O(l)\) 层的模型。
假设更多的参数和训练能够让 LLM 实现更好的记忆,这可能有助于需要 world knowledge 的任务。
衡量 emergent abilities 的 evaluation metrics 也值得探究。仅仅使用最终的指标(如 acc 等)并不一定很好地反映 emergence
4.2、Beyond scaling
虽然本文主要探究模型超过一定规模后出现 emergent ability, 但模型仍然有可能通过数据,算法的改进在更小规模出现 emergence。
比如在 BIG-Bench 任务上,LaMDA 在 137B,GPT-3 在 175B 上出现 emergent ability,而 PaLM 在 62B 就可以出现。
4.3、涌现能力的另一种视角
虽然模型的规模与表现高度相关,但是模型的规模并不是观察到 emergent abilities 的唯一尺度。
如下图所示,模型的 emergent abilities 可以看成一系列相关变量的函数。
4.4、可能的未来工作
作者为未来研究大模型中的 emergent abilitie 提供了一些方向。
Further model scaling: 继续增加模型的规模探究模型的表现的提升。
Improved model architectures and training:从模型的结构和训练过程上提高模型的质量,从而使模型在较低的训练成本下就可以获得 emergent abilities.
Data scaling: 增大数据集的规模
Better techniques for and understanding of prompting:更好地发挥 prompt 在模型中的作用
Frontier tasks: 仍然有些任务无法出现 emerent abilities,这也是值得探究的。
Understanding emergence: 关于 emergent abilities 为什么会在语言模型中发生仍然是未知的。
5、关于 Scale 的思考
5.1、更大
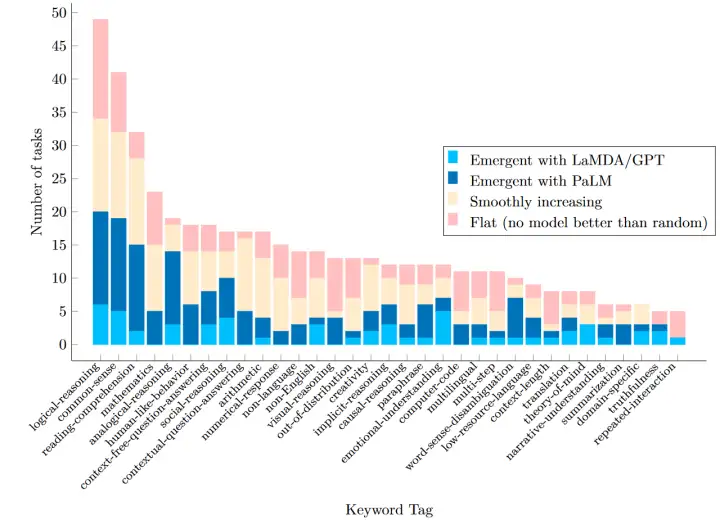
BIG-Bench 是一个包含超过 200 个任务的用于评测语言模型的数据集,其中并非所有的任务都会发生涌现(如下图所示)。有的任务表现随 scale up 而平滑增加,而有的任务至今为止还没有通过 scale up 超过随机表现。比如同为算术类任务,simple arithmetic 会平滑增加,modified arithmetic 发生了涌现,multistep arithmetic 还没有超过随机表现。
这些未解决的任务会是进一步研究的对象。这些问题是否能单纯靠 scale up 解决?涌现的原因是什么?涌现之后 scale up 是否有性能上限?即使 scale up 在性能提升上不会遇到瓶颈,计算的负载也会成为巨大的问题。
5.2、更小
影响模型能力的不仅有 模型的规模,还有 数据、模型结构 或是 训练方法。在更好的数据、模型结构、训练方法下,我们可以在同样甚至更小的模型规模下实现更好的效果。
使用更好的数据可以在更低的模型规模下实现涌现:如 PaLM 62B 以更少的模型参数与更低的 FLOPs,突破了 LaMDA 137B 和 GPT-3 175B 只能取得随机表现的多个任务。虽然因为高昂的训练成本,不可能进行详尽的消融实验,但一个可能的原因是 PaLM 使用了更好的数据(如多语言数据、代码数据)。
数据本身可能也是涌现的原因,如数据中的长程依赖、稀有类别与 few-shot prompting 的涌现有关,chain of thought 能力可能来自于代码数据。
更好的模型结构也可以降低涌现的阈值。
如 encoder-decoder 模型要更适合于 instruction finetuning。
对于 decoder 模型,instruction finetuning 仅对 68B 以上参数量的模型有效;但 encoder-decoder 模型仅需要 11B。
更多信息可以参考论文 《What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?》
AIM (Adapter Image Model) 中的 Adapter 定义:
参考:taoyang1122/adapt-image-models/mmaction/models/backbones/vit_imagenet.py
import torch
from torch import nn
class Adapter(nn.Module):
def __init__(self, D_features, mlp_ratio=0.25, act_layer=nn.GELU, skip_connect=True):
"""
- D_features: 输入的特征维度 (Feature Dimension)
- mlp_ratio: 降维的比例, 默认是 0.25
- act_layer: 激活函数
- skip_connect: 是否存在 Residual Connection
"""
super().__init__()
self.skip_connect = skip_connect
D_hidden_features = int(D_features * mlp_ratio)
self.act = act_layer()
self.D_fc1 = nn.Linear(D_features, D_hidden_features) # Down
self.D_fc2 = nn.Linear(D_hidden_features, D_features) # Up
def forward(self, x):
# x is (BT, HW+1, D)
xs = self.D_fc1(x)
xs = self.act(xs)
xs = self.D_fc2(xs)
if self.skip_connect:
x = x + xs
else:
x = xs
return x
self.MLP_Adapter = Adapter(dim, skip_connect=False) # MLP-adapter, no skip connection
self.S_Adapter = Adapter(dim) # with skip connection
self.scale = scale # default is 0.5
self.T_Adapter = Adapter(dim, skip_connect=False) # no skip connection
if num_tadapter == 2:
self.T_Adapter_in = Adapter(dim)
参考:taoyang1122/adapt-image-models/mmaction/models/backbones/swin2d_adapter.py
class SAdapter2(nn.Module):
def __init__(self, D_features, mlp_ratio=0.25, act_layer=nn.GELU):
super().__init__()
D_hidden_features = int(D_features * mlp_ratio)
self.D_fc1 = nn.Linear(D_features, D_hidden_features)
self.D_fc2 = nn.Linear(D_hidden_features, D_features)
self.act = act_layer()
def forward(self, x):
xs = self.D_fc1(x)
xs = self.act(xs)
xs = self.D_fc2(xs)
x = x + xs
# x = rearrange(x, 'B N T D -> (B T) N D')
return x
class T_Adapter(nn.Module):
def __init__(self, D_features, mlp_ratio=0.25, act_layer=nn.GELU):
super().__init__()
D_hidden_features = int(D_features * mlp_ratio)
self.D_fc1 = nn.Linear(D_features, D_hidden_features)
self.D_fc2 = nn.Linear(D_hidden_features, D_features)
self.act = act_layer()
def forward(self, x):
xs = self.D_fc1(x)
xs = self.act(xs)
xs = self.D_fc2(xs)
x = xs
# x = rearrange(x, 'B N T D -> (B T) N D')
return x
# 初始化
def init_weights(self, pretrained=None):
def _init_weights(m):
# 初始化 Linear
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# 初始化 LayerNorm
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
# 对 Spatial Adapter 的 FC_2 层进行特殊的初始化,置为 0
for n, m in self.layers.named_modules():
if 'S_Adapter' in n:
for n2, m2 in m.named_modules():
if 'D_fc2' in n2:
if isinstance(m2, nn.Linear):
nn.init.constant_(m2.weight, 0)
nn.init.constant_(m2.bias, 0)
# 对 Temporal Adapter 的 FC_2 层进行特殊的初始化,置为 0
for n, m in self.layers.named_modules():
if 'T_Adapter' in n:
for n2, m2 in m.named_modules():
if 'D_fc2' in n2:
if isinstance(m2, nn.Linear):
nn.init.constant_(m2.weight, 0)
nn.init.constant_(m2.bias, 0)
## initialize MLP Adapter
for n, m in self.blocks.named_modules():
if 'MLP_Adapter' in n:
for n2, m2 in m.named_modules():
if 'D_fc2' in n2:
if isinstance(m2, nn.Linear):
nn.init.constant_(m2.weight, 0)
nn.init.constant_(m2.bias, 0)
位置:./mmaction/models/backbones/timesformer.py
class TimeSformer:
# 这里的 width 其实就是 Transformer 中的 d_model
scale = width ** -0.5
# Random
self.class_embedding = nn.Parameter(scale * torch.randn(width))
# Random
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.tadapter = False
self.num_frames = num_frames
# Temporal Embedding
if attn_type == 'tadapter':
self.temporal_embedding = nn.Parameter(torch.zeros(1, num_frames, width))
self.tadapter = True
class ResidualAttentionBlock:
pass
更多
参考
论文:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/08/emergent-abilities-of-llm/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)