Toolformer
Toolformer: Language Models Can Teach Themselves to Use Tools
URL:http://arxiv.org/abs/2302.04761
单位:Meta AI Research
Unofficial Code:https://github.com/xrsrke/toolformer
TODO List:
具体的步骤
具体的训练、推理过程
具体的外部工具 API 调用代码
具体的训练代码使用
前言
大语言模型已经在许多的 NLP 任务上取得了不错的 few-shot 和 zero-shot 性能,但是,LLM 仍然存在很多的局限性(现有方法最多可以通过扩展 LLM 来部分解决),例如:
LLM 无法获取近期事件的最新信息(无法联网)
LLM 会不切实际的 “胡编乱造” (hallucinate facts)
LLM 对 小语种 的理解仍比较困难
LLM 缺乏精确计算的 数学技能(数学能力差)
LLM 没有 时间 概念(无法给出当前的准确日期和时间)
A simple way to overcome these limitations of today’s language models is to give them the ability to use external tools such as search engines, calculators, or calendars. 然而,现有工作要么需要依赖大量的人工标注数据,要么将工具的使用局限在特定的任务,阻碍了 LMs 更加广泛地使用工具。
因此,作者提出了 Toolformer,通过一个新的方式来使得 LM 能够使用工具。具体来说,Toolformer 需要满足以下 需求:
不需要大量的人工标注:模型以 自监督(self-supervised) 的方式进行学习
- 这不仅是因为人工标注的成本昂贵,还因为人类认为的 “有用” 与模型认为的 “有用” 不同
LMs 不应失去任何通用性 (generality),并且应该能够 自行决定 (decide for itself) 何时以及如何 (when and how) 使用哪种工具。
Our approach for achieving these goals is based on the recent idea of using large LMs with in-context learning to generate entire datasets from scratch.
我们实现这些目标的方法基于最近的想法,即,使用具有 上下文学习 的大型 LM 从头开始生成整个数据集。
先给 Toolformer 提供少量已经手动标注好的例子,然后让语言模型在实践中 生成一个更大的包含示例的数据集。

Origin:新英格兰医学杂志是 MMS 协会的注册会员
New:新英格兰医学杂志是 【QA(谁是新英格兰医学杂志的出版商->Massachusetts Medical Society)】MMS 协会的注册会员
使用外部 QA 系统返回的数据,来增强对 MMS 的解释
Origin:在 1400 参与者中,400 人通过了考试
New:在 1400 参与者中,400【or Calculator(400 / 1400 -> 0.29) 29%】人通过了考试

The model autonomously decides(自主的决定) to call different APIs (a question answering system, a calculator, a machine translation system, and a Wikipedia search engine) to obtain information that is useful for completing a piece of text.


三个主要的步骤
Toolformer 主要包括三个主要的步骤,包括:
Sampling API Calls
- 采样一个工具 API 调用
Executing API Calls
- 执行工具 API 调用
Filtering API Calls
- 根据自监督的损失函数来过滤工具 API 调用
这三个步骤的示意图如下图所示。
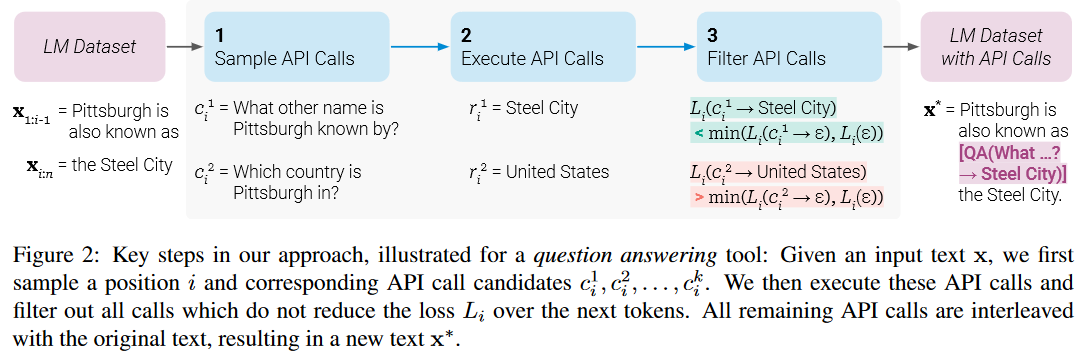
具体用来生成 API 调用的 Few-Shot Prompt 示例如下图所示:

We using special tokens to mark the start and end of each such call. 使用特殊的 Token 来标记 API 调用结果在文本序列的开始位置和结束位置。
模型微调与推断
Finetune
Inference
外部工具
We explore a variety of tools to address different shortcomings of regular LMs.
对于工具的要求:
工具的 输入和输出 能够被表示成文本序列(text sequences)的形式
we can obtain a few demonstrations of their intended use. (能够预先知道工具的用途)
作者探索了五种外部工具,包括:
Question Answering
基于 LM 的问答系统
具体来说,使用 Atlas 模型
Calculator
使用只支持四种基本算术运行的计算器
返回结果始终四舍五入到小数点后两位
Wikipedia Search
给定一个搜索词(search term),返回来自维基百科的短文本
需要模型自己来提取相关的信息
Machine Translation System
基于 LM 的机器翻译系统
具体来说,使用 600 M 参数的 NLLB 模型(能够翻译超过 200 种语言)
同时,使用 fastText 分类器来自动检测源语言,并且始终将英语作为目标语言
Calendar
- 调用时,在不接受任何输入的情况下,返回当前的日期信息
局限性
虽然本文的工作能够让 LM 以自监督的方式来学习如何使用各种外部工具,但是仍然存在一些局限性。
Toolformer 无法使用工具链 (cannot use tools in a chain),即 将一个工具的输出作为另一个工具的输入
- 这是因为每个工具的 API 调用都是 独立生成 的,因此微调的数据集中没有使用 chained tool 的示例
Toolormer 无法 让 LM 以 交互 的方式(例如 ChatGPT 对话的交互形式)来使用工具
尤其是搜索引擎等工具,可能会返回数百个不同的结果,使 LM 能够浏览这些结果或优化搜索查询
作者还发现:Toolformer 在决定是否调用 API 时通常对其输入的确切措辞很敏感
- 这不足为奇,因为已有的许多工作也都发现了 LM 对于 Prompt 非常敏感 的现象(LM 普遍的通病)
Toolformer 采样效率比较低
例如,处理超过一百万个文档只会产生几千个对计算器 API 的有用调用示例
一种可能的解决方法是使用 BootStrapping 重采样方法,迭代地进行采样
Toolformer 目前 没有考虑 调用 API 所需要花费的 计算成本
- 未来:将计算成本也列入到 LM 模型的 Loss 中
结论
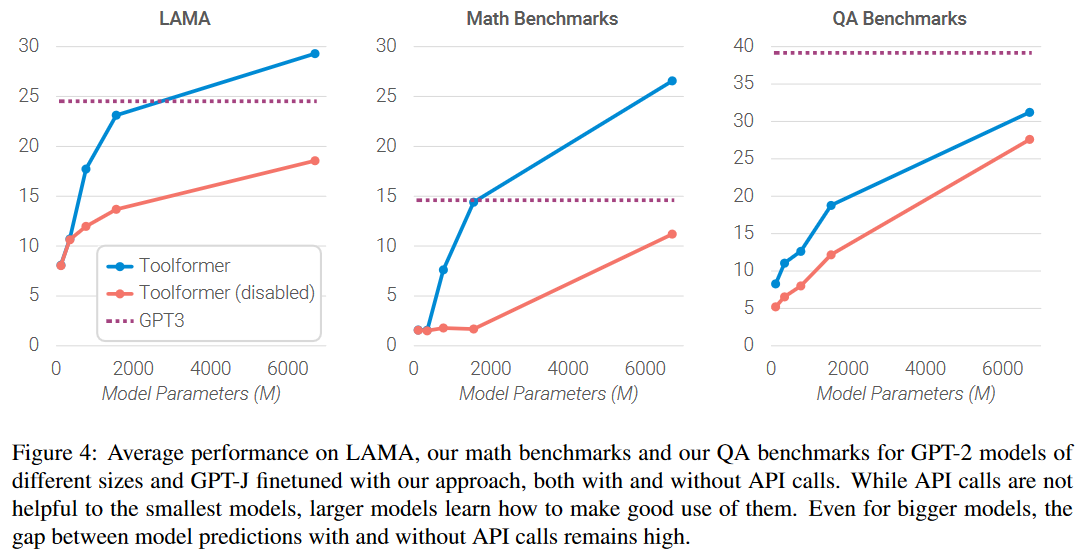
Toolformer considerably improves zero-shot performance of a 6.7B parameter GPT-J model, enabling it to even outperform a much larger GPT-3 model on a range of different downstream tasks.
While API calls are not helpful to the smallest models, larger models learn how to make good use of them. Even for bigger models, the gap between model predictions with and without API calls remains high. 调用 API 对于规模较小的模型帮助不大,而对于更大的模型,API 调用的作用就逐渐显现出来,如下图所示。
PyTorch 代码
Data Generation
# test.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from toolformer.data_generator import DataGenerator
from toolformer.api import CalculatorAPI, WolframeAPI
from toolformer.prompt import calculator_prompt, wolframe_prompt
from toolformer.utils import yaml2dict
config = yaml2dict('./toolformer/configs/default.yaml')
calculator_api = CalculatorAPI("Calculator", calculator_prompt)
# wolframe_api = WolframeAPI("Wolframe", wolframe_prompt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m")
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
text = "From this, we have 10 - 5 minutes = 5 minutes."
generator = DataGenerator(config, model, tokenizer, apis=[calculator_api])
print("generator: ", generator)
augumented_text = generator.generate(text)
print("augumented_text: ", augumented_text)
print(augumented_text.shape)
res_text = augumented_text.tolist()
print("res_text: ", res_text)
res = tokenizer.convert_ids_to_tokens(res_text)
print("res: ", res)
"""
generator: <toolformer.data_generator.DataGenerator object at 0x7f0b6c0fafa0>
2023-04-02 07:15:42.537305: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
augumented_text: tensor([[[ 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 3, 3, 3, 12620,
1119, 15, 1701, 1542, 1581, 647, 973, 17405,
564, 1111, 120009, 2623, 11, 1416, 647, 973,
12, 64, 973, 17405, 6149]]])
torch.Size([1, 1, 61])
res_text: [[[3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 12620, 1119, 15, 1701, 1542, 1581, 647, 973, 17405, 564, 1111, 120009, 2623, 11, 1416, 647, 973, 12, 64, 973, 17405, 6149]]]
res: ['<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', 'From', 'Ġthis', ',', 'Ġwe', 'Ġhave', 'Ġ10', 'Ġ-', 'Ġ5', 'Ġminutes', 'Ġ=', 'Ġ[', 'Calcul', 'ator', '(', '10', 'Ġ-', 'Ġ5', ')', ']', 'Ġ5', 'Ġminutes', '.ĊĊ']
"""
更多
How to sampling APIs call: YouTube Video
How to calculate the loss: YouTube Video
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/04/02/Toolformer/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)