大模型通常是在等代理任务上进行预训练的,而这些任务与视频时刻定位等下游任务之间可能存在很大的差异(gap)
现在的预训练模型参数量越来越大,为了一个特定的任务去 Fine Tuning 一个模型,然后部署于线上业务,也会造成部署资源的极大浪费
总结
通过将一些提示融合进自然语言特征,缩短了预训练大模型的代理任务与下游任务之间的差距,并且使用参数高效的微调方法对预训练大模型进行微调,从而能够很好地将预训练大模型的强大能力迁移到下游任务。
在无监督场景下,通过聚类等方法来产生候选的视频片段;
并且使用预训练的视频描述模型来生成伪自然语言特征;
从而能够在没有人工标注数据上进行训练;
提示学习的本质:
将所有下游任务统一成预训练任务;以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计就是挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务。
背景
随着 ChatGPT、GPT-4 掀起的新一轮 “AI 热”,新一轮的军备竞赛已悄然上演,例如 Mate AI 开源的 LLaMA 模型,参数量最大能达到 65 Billion;视觉领域也 “不甘落后”,Google Research 把 ViT (Vision Transformer) 的参数规模直接从十亿级别提升到了百亿级别,达到 22 Billion。
身处大模型时代下的我们,又该如何进行科研工作呢(特别是算力不够时)?

本文主要内容来自李沐大神和朱老师最近的一个视频 大模型时代下做科研的四个思路【论文精读·52】,里面谈到了四个可能的方向:
Efficient (Parameter-Efficient Fine Tuning,PEFT)
Existing stuff (pretrained model) and New direction
Plug-and-play(通用的、即插即用的模块)or data augmentation
Dataset, evaluation and survey
1、Parameter-Efficient Fine Tuning
1.1、前言
1) Adapter
Adapter 最早来自于 2019 年的论文《Parameter-Efficient Transfer Learning for NLP》
Parameter-Efficient Transfer Learning for NLP
URL:https://arxiv.org/abs/1902.00751
会议:ICML 2019
单位:Google Research
主页:http://proceedings.mlr.press/v97/houlsby19a.html
Official Code:https://github.com/google-research/adapter-bert

Adapter 其实就是一个 下采样的 FC 层 + 非线性激活 + FeedForward 上采样(FC)+ Residual Connection,反向传播过程中只需要计算 Adapter 以及 LN 的参数梯度。
其实 Adapter 就跟 CVPR 2018 的 SENET 中的 Channel Attention 很相似,也是一个 下采样 + 激活层 + 上采样。
具体的 Adapter 参数量:
假设模型的输入特征是 \(n\),输出特征是 \(m\),则:
上采样:\(n * m + m\)
下采样:\(m * n + n\)
LN:\(2 * m\)
因此,总的需要微调的参数共有 \(2nm + 3m + n\),并且 \(m \ll n\)。
Our strategy has three key properties:
(i) it attains good performance,
(ii) it permits training on tasks sequentially, that is, it does not require simultaneous access to all datasets, and
(iii) it adds only a small number of additional parameters per task.
Adapter modules have two main features:
a small number of parameters;
a near-identity initialization;
By initializing the adapters to a near-identity function, original network is unaffected when training starts.
We also observe that if the initialization deviates too far from the identity function, the model may fail to train.
# Official Code
def feedforward_adapter(input_tensor, hidden_size=64, init_scale=1e-3):
"""A feedforward adapter layer with a bottleneck.
Implements a bottleneck layer with a user-specified nonlinearity and an
identity residual connection. All variables created are added to the
"adapters" collection.
Args:
input_tensor: input Tensor of shape [batch size, hidden dimension]
hidden_size: dimension of the bottleneck layer.
init_scale: Scale of the initialization distribution used for weights.
Returns:
Tensor of the same shape as x.
"""
with tf.variable_scope("adapters"):
in_size = input_tensor.get_shape().as_list()[1]
w1 = tf.get_variable(
"weights1", [in_size, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=init_scale),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
b1 = tf.get_variable(
"biases1", [1, hidden_size],
initializer=tf.zeros_initializer(),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
net = tf.tensordot(input_tensor, w1, [[1], [0]]) + b1
net = gelu(net)
w2 = tf.get_variable(
"weights2", [hidden_size, in_size],
initializer=tf.truncated_normal_initializer(stddev=init_scale),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
b2 = tf.get_variable(
"biases2", [1, in_size],
initializer=tf.zeros_initializer(),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
net = tf.tensordot(net, w2, [[1], [0]]) + b2
return net + input_tensor
PyTorch 代码
参考:github
首先对 Adapter 进行定义:
# Unofficial Code(PyTorch)
import torch.nn as nn
import torch.nn.functional as F
# Adapter_dim = 64
ADAPTER_BOTTLENECK = 64
EPOCHS = 20
LEARNING_RATE = 3e-5
BATCH_SIZE = 32
class AdapterModule(nn.Module):
def __init__(
self,
in_feature
):
super().__init__()
# 下采样: in_feature -> ADAPTER_BOTTLENECK
self.proj_down = nn.Linear(in_features=in_feature, out_features=ADAPTER_BOTTLENECK)
# 上采样: ADAPTER_BOTTLENECK -> in_feature
self.proj_up = nn.Linear(in_features=ADAPTER_BOTTLENECK, out_features=in_feature)
def forward(self, x):
input = x.clone()
# 下采样
x = self.proj_down(x)
# 激活
x = F.relu(x)
# 上采样 + Skip Connection
return self.proj_up(x) + input # Skip Connection
然后接收 Self Attention 或者 Cross Attention 模块的输出,来进行前向传播:
# Input: Self Attention output
# Output: After Adapter and LayerNorm with residual connection
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.adapter = AdapterModule(768)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.adapter(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Input: Cross Attention output
# Output: After Adapter and LayerNorm with residual connection
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.adapter = AdapterModule(768)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.adapter(hidden_states) # Adapter
hidden_states = self.LayerNorm(hidden_states + input_tensor) # LN + Res
return hidden_states
在训练的时候,需要对 Adapter 以及 LayerNorm 的参数 进行微调,而冻住 BERT 的其他参数:
from transformers import (
BertTokenizer,
AdamW,
get_linear_schedule_with_warmup
)
def configure_optimizers(self):
# 支队 Adapter 以及 LN 的参数进行微调
layers = ["adapter", "LayerNorm"]
params = [p for n, p in self.model.named_parameters() \
if any([(nd in n) for nd in layers])]
self.optimizer = AdamW(params, lr=LEARNING_RATE)
self.scheduler = get_linear_schedule_with_warmup(
self.optimizer,
num_warmup_steps = int(0.1 * len(self.train_dataset)) * EPOCHS
)
2) LoRA:Stable Diffusion Model 的插件
LoRA 的全称是 Low-Rank Adaptation of Large Language Models,这是微软的研究人员为了解决 大语言模型微调 而开发的一项技术。
LoRA: Low-Rank Adaptation of Large Language Models
URL:https://arxiv.org/abs/2106.09685
单位:微软
Official Code:https://github.com/microsoft/LoRA
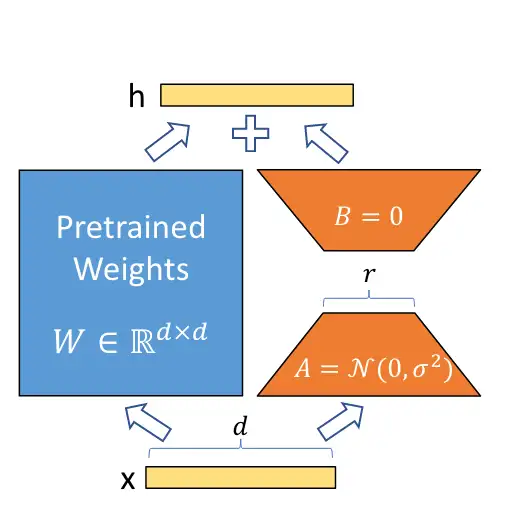
LoRA 最初是用来微调大语言模型的,但把它用在 Cross-Attention Layers(交叉注意力层)也能影响 用文本生成图片 的效果。正是如此,LoRA 现在被广泛于各种 Stable Diffusion Model 中。
最早的 Stable Diffusion Model 其实不支持 LoRA 的,后来才加入了对 LoRA 的支持。据说,Simo Ryu 是第一个让 Stable Diffusion Model 支持 LoRA 的人,感兴趣的话,去大佬的 GitHub 上看看这个项目。
同时,还可以参见 HuggingFace 的 Blog:Using LoRA for Efficient Stable Diffusion Fine-Tuning
LoCon:LoRA 的改进
LoCon 的全称:LoRA for Convolution Network
- LoCon in Stable Diffusion 文档:LoCon LyCORIS 超越LoRA的
3) Prompt Tuning
CoOp、CoCoOp -> 这里的 Prompt 还是在文本端(看起来还是更像一个 NLP 的工作)
纯视觉的工作:Visual Prompt Tuning(VPT,2022 年)
4) 各种 Attention 的近似
除了这些 Parameter-Efficient Fine Tuning 方法之外,能够提高模型运行速度的方法还包括对 Attention 的各种近似,例如最近的 Flash Attention。
5) 小结
这些 Adapter、Prompt Tuning 的共通性:当有一个已经预训练好的大模型后,希望这个模型是锁住不动的,不仅有利于做训练,而且还有利于做部署、做下游任务的 transfer。性能还不降(很多时候性能不降反升)。
(In-Context Learning、RLHF 都会很快被卷到 CV Community 中,♂↑+♂)
综述:《Towards a Unified View of Parameter-Efficient Transfer Learning》
Towards a Unified View of Parameter-Efficient Transfer Learning
URL:https://arxiv.org/abs/2110.04366
会议:ICLR 2022
Official Code:https://github.com/jxhe/unify-parameter-efficient-tuning

1.2、AIM
AIM: Adapting Image Models for Efficient Video Action Recognition
调整图像模型 以实现 高效的视频动作识别
URL:https://arxiv.org/abs/2302.03024
会议:ICLR 2023
主页:https://adapt-image-models.github.io/
Official Code:https://github.com/taoyang1122/adapt-image-models
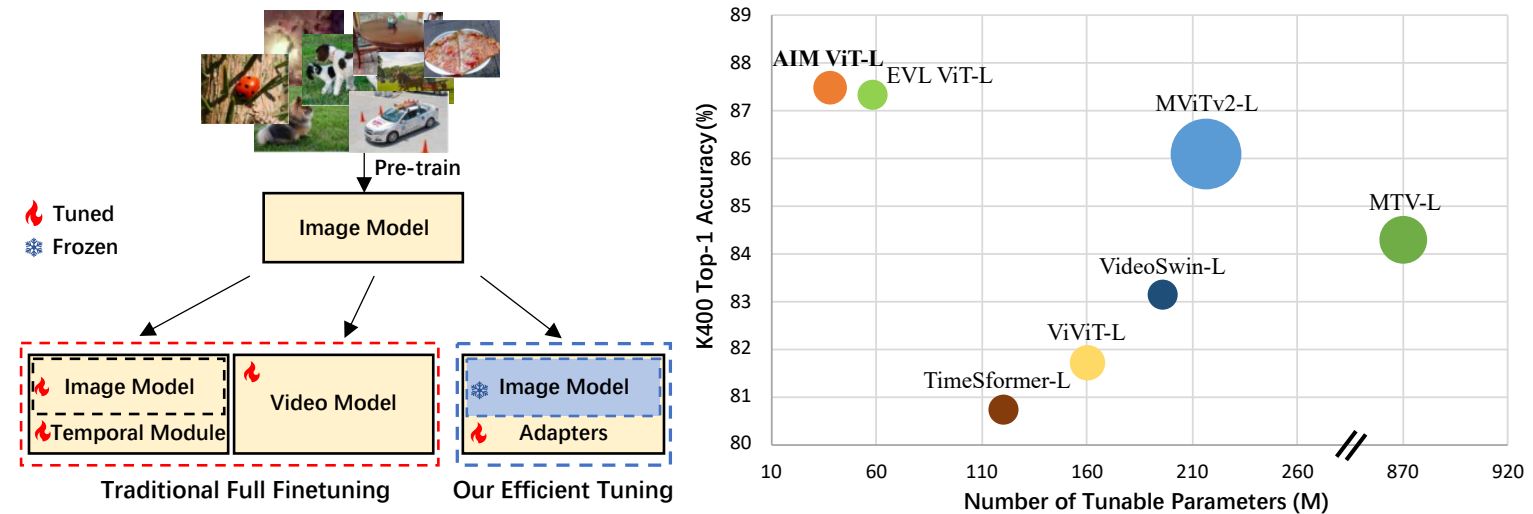
主流的使用预训练图像模型来做视频任务的方法大致有三种,包括:
1)Image Model + Temporal Module (Full Fine Tuning)
- 例如:TSM、TimeSformer
2)Video Model (Full Fine Tuning)
- 3D-CNN、Video Swin(将 2D Shift Windows 变成 3D Shift Windows)
3)Image Model + Adapters (Ours)

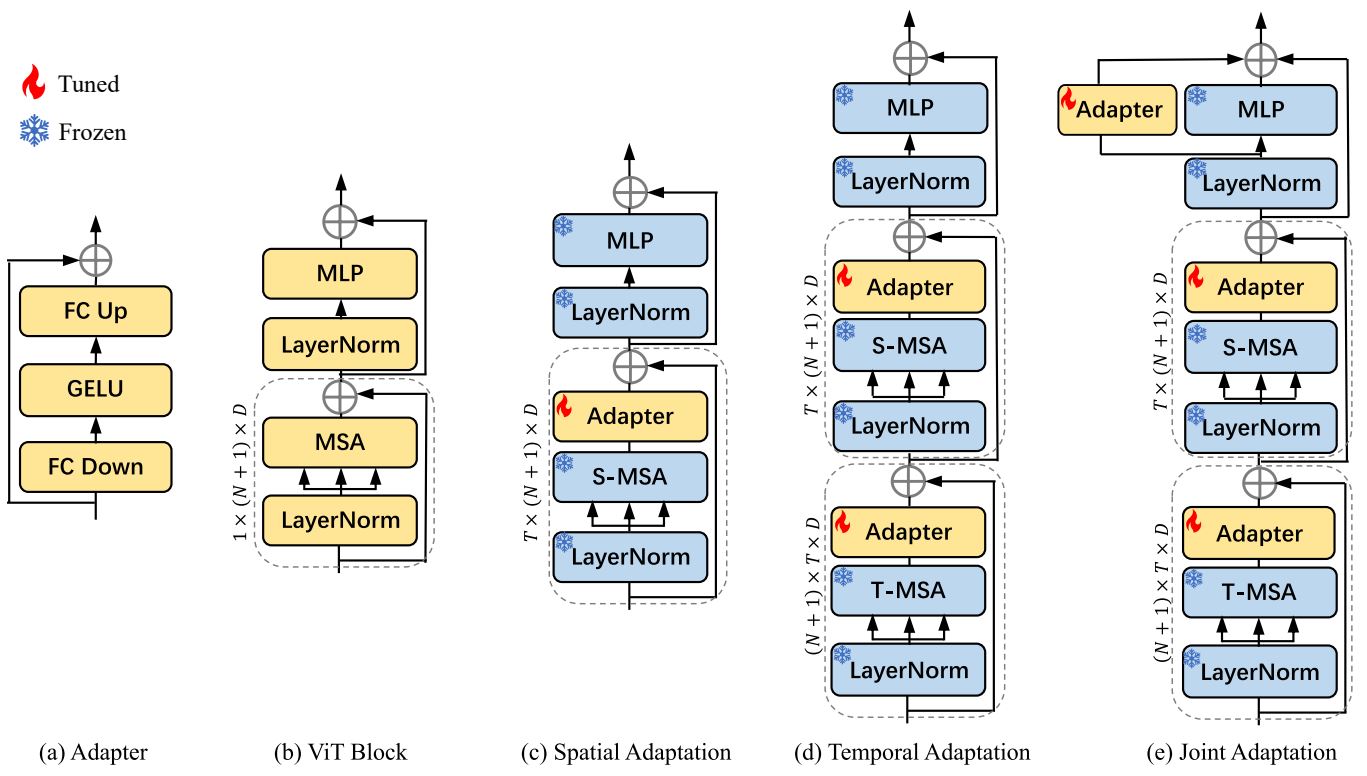
如下图所示,AIM (Adapt pre-trained Image Models) 模型就是在图 b 的 ViT 模型中加入图 a 的 Adapter,共有图 c、d、e 三种方式:
Spatial Adaptation:只在 S-MSA 层后面加入 Adapter,即不增加视频理解能力,只加一些学习的参数。
\[\begin{align} S = \begin{cases} z_l^\prime &= z_{l-1} + \text{MSA}(\text{LN}(z_{l-1})) \\ z_l^{\prime\prime} &= \color{red}{z_l^\prime + \text{FC}_{up}(\text{Act}(\text{FC}_{down}(z_l^\prime)))} \\ z_l &= z_l^{\prime\prime} + \text{MLP}(\text{LN}(z_l^{\prime\prime})) \\ \end{cases} \end{align}\]Temporal Adaptation:复用一个 MSA 层,在两个 MSA 层后面都加入 Adapter,即让模型从 Spatial 和 Temporal 两个方向上进行学习,从而有时序建模的能力。
- 注意:Temporal Adapter Without Skip-Connection (在训练最开始将 Adapter 置为 0 时,能够与预训练模型的结构保持一致)
Joint Adaptation:在 Temporal Adaptation 的基础上,在 MLP 边上也加入 Adapter,即让三个 Adapter 各司其职,使得优化问题更简单一些。
- 注意:Joint Adapter Without Skip-Connection (在训练最开始将 Adapter 置为 0 时,能够与预训练模型的结构保持一致)
注:
MSA (MultiHead Self-Attention) 是多头自注意力,S-MSA 和 T-MSA 共享权重,但维度不同。
具体的实验结果如下图所示,只用 14 M 参数的 AIM 模型效果已经高过之前 121 M 的模型:

PyTorch 伪代码
class TransformerBlock():
def __init__(self, dim, num_head, mlp_ratio, scale):
## Layers in the original ViT block
self.attn = MultiheadAttention(dim, num_head)
self.norm1 = LayerNorm(dim)
self.mlp = MLP(dim, mlp_ratio)
self.norm2 = LayerNorm(dim)
## Adapters
self.s_adapter = Adapter(dim)
self.t_adapter = Adapter(dim)
self.mlp_adapter = Adapter(dim)
self.scale = scale
def forward(x):
## x in shape [N + 1, BT, D]
## temporal adaptation
xt = rearrange(x, 'n (b t) d -> t (b n) d', t = num_frames)
xt = self.t_adapter(self.attn(self.norm1(x)))
xt = rearrange(x, 't (b n) d -> n (b t) d', n = num_patches)
x = x + xt
## spatial adaptation
x = x + self.s_adapter(self.attn(self.norm1(x)))
## joint adaptation
x_norm = self.norm2(x)
x = x + self.mlp(x_norm) + self.scale * self.mlp_adapter(x_norm)
return x
1.3、工具包:huggingface-peft
PEFT:State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods
HuggingFace 最近开放了一个专门用来做 PEFT 的工具包,可以直接在 github 上找到。
刚起步,目前是 v0.2.0 版本。
1.4、工具包:adapter-transformers
![]()
2、Existing stuff (pretrained model) and new direction
尽量不要去碰预训练(pre-training),算力、数据规模都太大;而是使用预训练好的模型
尽量去做一些比较新、比较超前的 topic
数据集没有很大
没有很多已有的工作
用一篇 ICLR 2023 的论文《Unsupervised semantic segmentation with self-supervised objec-centric representations》来讲一下这两点是如何做的
Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
URL:https://arxiv.org/abs/2207.05027
会议:ICLR 2023

3、Plug and play(通用、即插即用的模块)
尽量做一些 通用的、即插即用的 模块:
既可以是模型上的模块,例如 Non-Local Module;
也可以是一个目标函数,例如把正常的 Loss 换成 Focal Loss;
还可以是输入层面的,也就是数据增强;
下面以 MixGen 这篇论文为例,做的是一个 多模态的数据增强。
MixGen: A New Multi-Modal Data Augmentation
URL:https://arxiv.org/abs/2206.08358
会议:WACV 2023
Official Code:https://github.com/amazon-science/mix-generation

既然 self-attention 能够参数共享(微软的 VLMo),那么为什么不能使用一个大的 Language Model 来蒸馏一个小的视觉模型,或者更进一步,能不能拿视觉的模型去蒸馏一个文本模型?
之前的很多工作都没有用 Data Augmentation,或者说仅使用了很简单的 Data Augmentation。例如,CLIP 仅使用了 Random Resized Crop
思考的第一个问题:为什么之前大家不在多模态里用 Data Augmentation?
原因可能就是:在做了 Data Argumentation 之后,原来的图像文本对可能就不再是一对了(例如做 Color Jitter,原来是蓝色的物体变成了白色的物体,但是句子中的表达仍然是 “Blue Object”)。也就是说在做了 Data Argumentation 之后,有些信息就被改变(丢失)了。
那么,如何才能使得这些信息不被丢失,最大程度上把这些信息保留下来?
可以先一个模态一个模态的想:
图像领域:天然的选择就是 Mixup(两张图片线性插值,叠加成一张图片)
文本领域:虽然文本也有 Mixup,但是如果是要最大程度的保留信息,最简单的方式就是直接将两个句子拼接在一起(这样什么信息都不会丢失)
这样虽然可能图片不是一张 “正常” 的图像,拼接起来的句子读起来可能不连贯,甚至是两个完全不沾边的句子,但是这最大程度的保留了原始的信息量,从而保证新生成的、增强之后的图像文本对尽可能的还是一个 matched pair。
MixGen(Mixed Generation)第一次投 NeurIPS 的时候没有中,审稿人觉得方法太简单~



4、Dataset, evaluation and survey
四种方法中使用计算资源最少的
《BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training》
一个非常大的目标检测数据集
评测(evaluation)为主的论文:《A Comprehensive Study of Deep Video Action Recognition》
参考
整体内容
Bilibili:
Parameter-Efficient Fine Tuning(PEFT)
Existing stuff (pretrained model) and New direction
Plug and play
Dataset, evaluation and survey
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/03/29/Four-Things-Can-Do-After-GPT-4/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)