nn.Parameter()
分析
首先可以把 nn.Parameter() 这个函数理解为 类型转换函数,将一个不可训练的类型 Tensor 转换成可以训练的类型 parameter,并将这个 parameter 绑定到这个 module 里面(net.parameter() 中就有这个绑定的 parameter,因此在参数优化的时候可以进行优化的),所以经过类型转换这个参数就变成了模型的一部分,成为了模型中根据训练可以改动的参数了。
使用这个函数的目的是:想让某些变量在学习的过程中不断的修改其值,以达到最优化。
将某些变量变成可训练的参数!
nn.Parameter() 在 ViT 中的实验
看过这个分析后,我们再看一下 Vision Transformer 中的用法:
......
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
......
我们知道:在 ViT 中,positonal embedding 和 class token 是两个需要随着网络训练学习的参数,但是它们又不属于 FC、MLP、MSA(Multi-head Self Attention)等运算的参数,在这时,就可以用 nn.Parameter() 来 将这个随机初始化的 Tensor 注册为可学习的参数 Parameter。
为了确定这两个参数确实是被添加到了 net.Parameters() 内,笔者稍微改动源码,显式地指定这两个参数的初始数值为 0.98,并打印迭代器 net.Parameters():
......
self.pos_embedding = nn.Parameter(torch.ones(1, num_patches+1, dim) * 0.98)
self.cls_token = nn.Parameter(torch.ones(1, 1, dim) * 0.98)
......
实例化一个ViT模型并打印 net.Parameters():
net_vit = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
for para in net_vit.parameters():
print(para.data)
输出结果中可以看到,最前两行就是我们显式指定为 0.98 的两个参数 pos_embedding 和 cls_token:
# Position Embedding
tensor([[[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800],
[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800],
[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800],
...,
[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800],
[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800],
[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800]]])
# Class Token
tensor([[[0.9800, 0.9800, 0.9800, ..., 0.9800, 0.9800, 0.9800]]])
#
tensor([[-0.0026, -0.0064, 0.0111, ..., 0.0091, -0.0041, -0.0060],
[ 0.0003, 0.0115, 0.0059, ..., -0.0052, -0.0056, 0.0010],
[ 0.0079, 0.0016, -0.0094, ..., 0.0174, 0.0065, 0.0001],
...,
[-0.0110, -0.0137, 0.0102, ..., 0.0145, -0.0105, -0.0167],
[-0.0116, -0.0147, 0.0030, ..., 0.0087, 0.0022, 0.0108],
[-0.0079, 0.0033, -0.0087, ..., -0.0174, 0.0103, 0.0021]])
...
...
这就可以确定 nn.Parameter() 添加的参数 pos_embedding 和 cls_token 确实是被添加到了 Parameters 列表中,然后会被送入优化器中随训练一起学习更新:
from torch.optim import Adam
opt = Adam(net_vit.parameters(), learning_rate=0.001)
nn.Embedding()
在 RNN 模型的训练过程中,需要用到词嵌入,而 torch.nn.Embedding() 就提供了这样的功能。我们只需要初始化 torch.nn.Embedding(n, m),其中 n 是单词数,m 就是词向量的维度。
构建一个包含
n个词的词嵌入表格
一开始 embedding 是 随机 的,在训练的时候会 自动更新(默认情况下 requires_grad 为 True)。
举个简单的例子:
word1 和 word2 是两个长度为 3 的句子,保存的是单词所对应的词向量的索引号。
随机生成 (4,5) 维度大小的 embedding,可以通过 embedding.weight 查看 embedding 的内容。输入 word1 时,embedding 会输出第 0、1、2 行词向量的内容,word2 同理。
import torch
word1 = torch.LongTensor([0, 1, 2])
word2 = torch.LongTensor([3, 1, 2])
embedding = torch.nn.Embedding(4, 5)
print(embedding.weight)
print('word1:')
print(embedding(word1))
print('word2:')
print(embedding(word2))
输出结果如下所示:
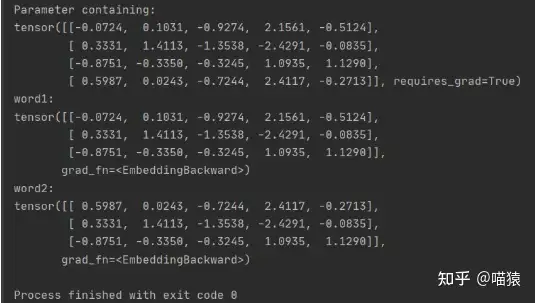
除此之外,我们也可以导入已经训练好的词向量,但是需要设置训练过程中不更新。
如下所示,emb 是已经训练得到的词向量,先初始化等同大小的 embedding,然后将 emb 的数据复制过来,最后一定要设置 weight.requires_grad 为 False。
self.embedding = torch.nn.Embedding(emb.size(0), emb.size(1))
self.embedding.weight = torch.nn.Parameter(emb)
# 固定embedding
self.embedding.weight.requires_grad = False
综合使用:Soft Prompt Tuning
代码来源:https://github.com/mkshing/Prompt-Tuning
初始化 soft prompt token:
def initialize_soft_prompt(
self,
n_tokens: int = 20, # prompt length
initialize_from_vocab: bool = True,
random_range: float = 0.5,
) -> None:
self.n_tokens = n_tokens
if initialize_from_vocab: # 使用 vocab 进行初始化
init_prompt_value = self.transformer.wte.weight[:n_tokens].clone().detach()
else: # 随机初始化
init_prompt_value = torch.FloatTensor(2, 10).uniform_(
-random_range, random_range
)
# nn.Embedding:构建 Prompt Token 字典
self.soft_prompt = nn.Embedding(n_tokens, self.config.n_embd)
# Initialize weight
# nn.Parameter: 可训练的 Prompt Token
self.soft_prompt.weight = nn.parameter.Parameter(init_prompt_value)

图片来源:https://github.com/kipgparker/soft-prompt-tuning

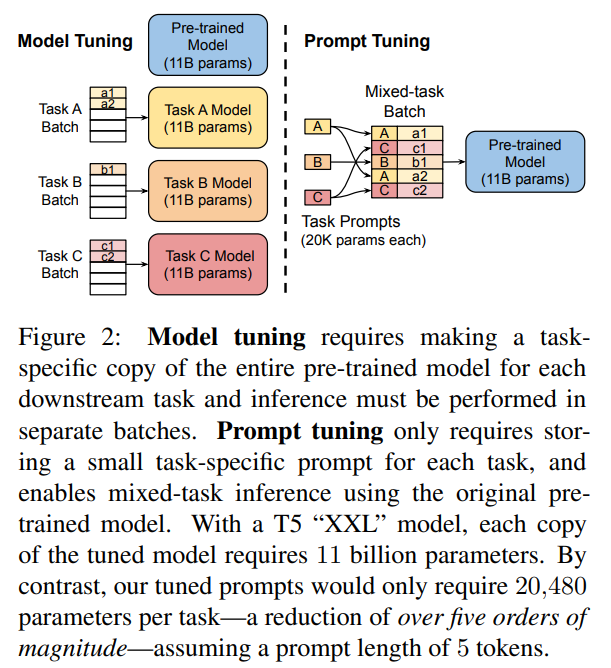
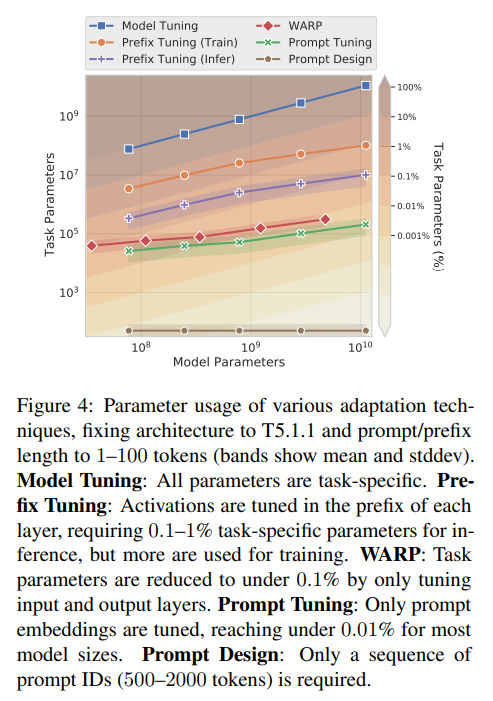
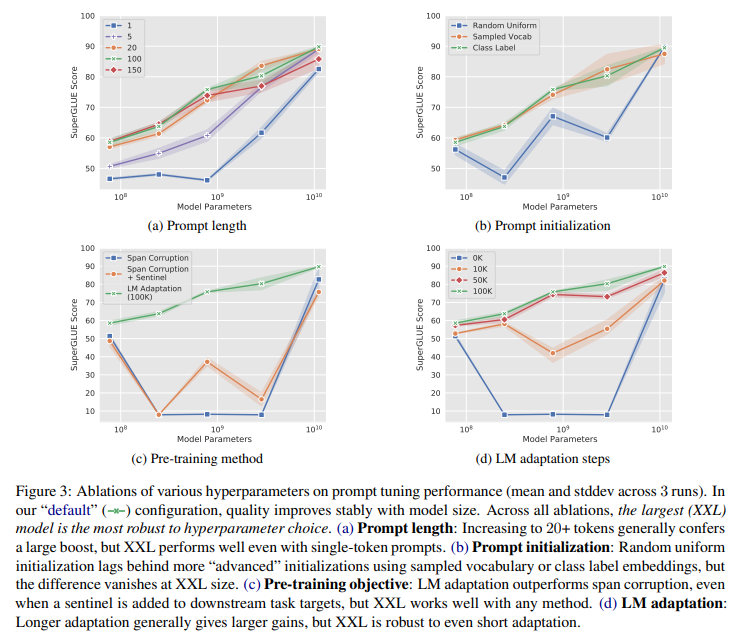
结论:
离散的 Prompt Tuning(Prompt Design)基本不能达到 fine-tuning 的效果;
Soft Prompt Tuning 在模型增大时可以达到接近 fine-tuning 的效果,并且有进一步超越 fine-tuning 的趋势;
Prompt Tuning 往往比 Fine-Tuning 提供更强的零样本性能;
如果比的是 Parameter Efficiency 性能,那几乎没有什么能与 Prompt Tuning 比,我们也知道 Prompt Design 甚至不需要任何参数。
参考
nn.Parameter()nn.Embedding()- 知乎:Torch.nn.Embedding的用法
- PyTorch 文档:torch.nn.Embedding
综合使用
github repo:https://github.com/mkshing/Prompt-Tuning
github repo:https://github.com/kipgparker/soft-prompt-tuning
知乎:Prompt Tuning里程碑作品:The Power of Scale for Parameter-Efficient Prompt Tuning
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/03/27/Embedding-Parameter-in-PyTorch/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)