《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》
URL:https://arxiv.org/abs/2106.10199
Official Code:https://github.com/benzakenelad/BitFit
会议:ACL 2022
前言
We propose BitFit, a novel method for localized, fast fine-tuning of pre-trained transformers for endtasks. The method focuses the finetuning on a specific fraction of the model parameters (the biases) and maintains good performance in all GLUE tasks we evaluated on.
只微调 Language Model 的 bias,方法简单,实现也简单。因此,不过多进行详细的描述~
BitFit (Bias-terms Fine-tuning)
这是一种 稀疏 的 fine-tune 方法,它 只在训练时更新 bias 的参数(或者部分 bias 参数)。

对于 transformer 模型而言,冻结大部分模型参数,只训练更新 bias 参数跟特定任务的分类层参数。涉及到的 bias 参数有:attention 模块中计算 query、key、value 跟合并多个 attention 结果的 bias ,MLP 层中的 bias,Layer-Normalization 层的 bias。

像 Bert base 跟 Bert large 这种模型里的 bias 参数 占模型全部参数量的 0.08%~0.09%。
实验
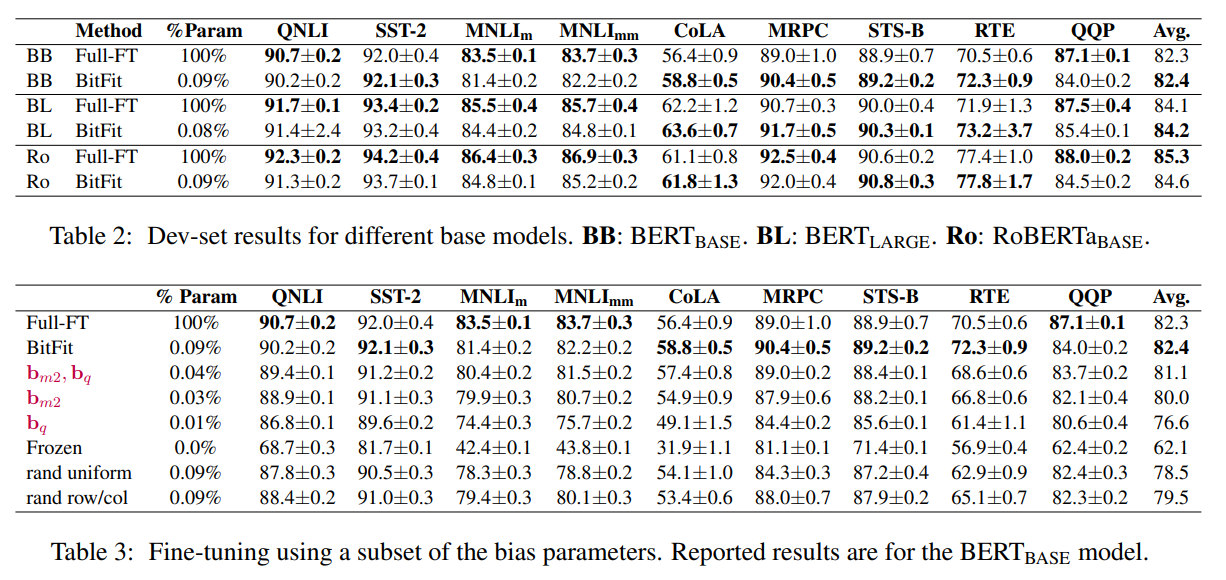
与之前的 Parameter-Efficient Tuning 方法进行对比
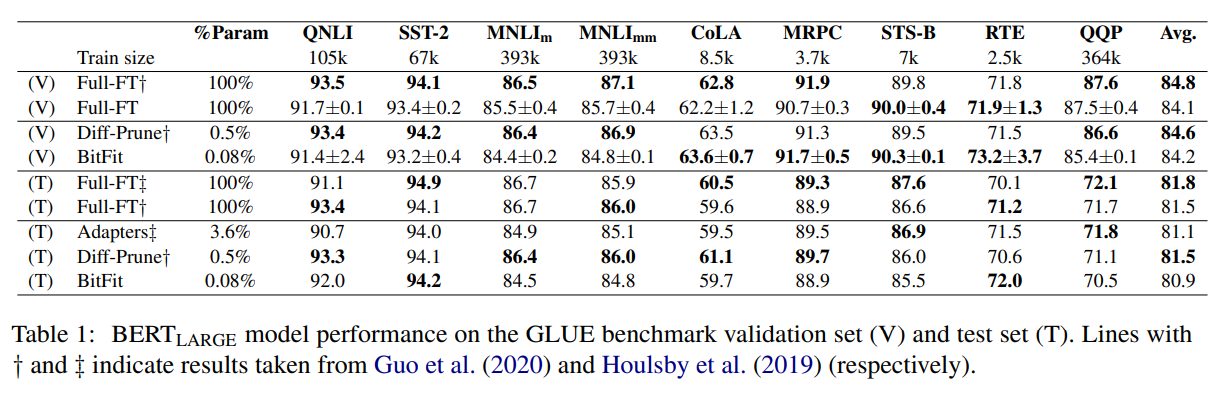
与 Full Fine-Tuning 进行对比
PyTorch 代码
代码来源于:OFA 的
train.py论文:Prompt Tuning for Generative Multimodal Pretrained Models
# bitfit
if cfg.model.bitfit:
for name, param in model.named_parameters():
if ("layer_norm" in name and "bias" in name) or ("fc" in name and "bias" in name):
param.requires_grad = True
else:
param.requires_grad = False
小结
BitFit 方法是在 Adapter 之后提出的。
Adapter 需要在原始 Language Model 的基础上加入 额外的模块(Adapter)
虽然减少了 训练 时的训练成本和存储资源
但是在 推理 时,不可避免的 引入了额外的计算,从而增加了推理的时间
BitFit 在 推理 时,能与原始 Language Model 的 结构保持一致,没有引入额外的计算
参考
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/03/17/BitFit/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)