FLAN:Finetuned Language Models Are Zero-Shot Learners
《Finetuned Language Models Are Zero-Shot Learners》
Code:https://github.com/google-research/flan
单位:Google Research
会议:ICLR 2022

FLAN 在标题上与 GPT-3 非常像:
《Finetuned Language Models Are Zero-Shot Learners》
《Language Models are Few-Shot Learners》
以为是蹭热度,结果点进去就没再出来过。
前言
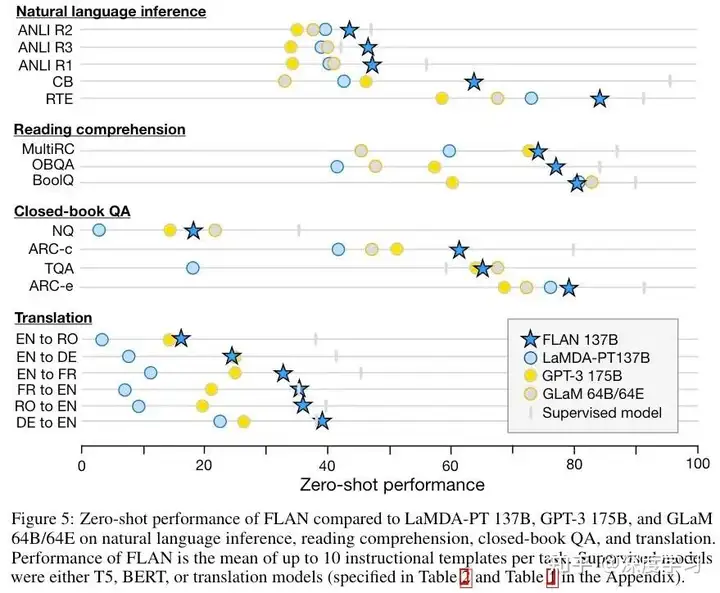
文章提出了 Instruction Tuning 的概念,用这种方式 微调大模型 之后可以 显著提升 大模型在自然语言推理(NLI)和阅读理解的表现,如下图所示。

更重要的是!Open AI 居然不谋而合,虽然没发论文,但也在官网放出了 类似模型的 Beta 版本:

从 OpenAI 官网给的几个例子,可以看到 Instruct 版本的模型相比于 GPT-3 可以更好的完成问答、分类和生成任务,是 更符合实际应用需求的模型。
什么是 Instruction Tuning
让我们先抛开脑子里的一切概念,把自己当成一个模型。我给你两个任务:
带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了!
判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A = 好,B = 一般,C = 差
你觉得哪个任务简单?做判别是不是比做生成要容易?Prompt 就是第一种模式,Instruction 就是第二种。
Instruction Tuning 和 Prompt 的核心一样,就是去发掘语言模型本身具备的知识。
而他们的不同点就在于:
- Prompt 是去激发语言模型的 补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做 language model 任务,它的模版是这样的:

- 而 Instruction Tuning 则是激发语言模型的 理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的 action。比如 NLI / 分类任务:

还有一个不同点,就是 Prompt 在没精调的模型上也能有一定效果,而 Instruction Tuning 则必须对模型精调,让模型知道这种指令模式。
但是,Prompt 也有精调呀,经过 Prompt tuning 之后,模型也就学习到了这个 Prompt 模式,精调之后跟 Instruction Tuning 有啥区别呢?
这就是 Instruction Tuning 巧妙的地方了。
Prompt tuning 都是针对一个任务的,比如做个情感分析任务的 prompt tuning,精调完的模型只能用于情感分析任务;
而经过 Instruction Tuning 多任务精调 后,可以用于其他任务的 zero-shot!
Fine-tuning:先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,如 BERT、T5;
Prompt-tuning:先选择某个通用的大规模预训练模型,然后为具体的任务生成一个 prompt 模板以适应大模型进行微调,如 GPT-3;
Instruction-tuning:仍然在预训练语言模型的基础上,先在多个已知任务上进行微调(通过自然语言的形式),然后再推理某个新任务上进行 zero-shot;
怎么做 Instruction Tuning
作者把 62 个 NLP 任务分成了 12 个类,训练时在 11 个上面精调,在 1 个上面测试 zero-shot 效果,这样可以保证模型真的没见过那类任务,看模型是不是真的能理解「指令」:

与 Prompt 一样,作者也会为每个任务设计 10 个指令模版,测试时看 平均 和 最好 的表现:

实验结果
作者们使用了 T5-11B 和 GPT-3 作为基线模型。对于 FLAN 方法,作者同时给出了在目标任务上选择 随机指令(no prompt engineering) 和在目标任务验证集上 最优指令(best dev template)。
指令微调阶段的任务数量
作者还研究了增加指令微调阶段 任务的数量 对 FLAN 模型效果的影响。结果表明,随着指令微调任务数目的增加,模型在各种任务上都能够取得更好的表现。

模型大小的影响
作者同时研究了 模型大小对 FLAN 模型效果的影响,一个有趣的现象是,当模型的大小较小时,指令微调反而会让模型的表现变差。作者认为的原因是,当模型较小时,在大量的任务上做指令微调会 “填满” 模型的容量,损害模型的泛化能力,使得模型在新任务上表现较差。

小结
熟悉 NLP 相关领域的同行们,也许会认为这篇文章又是一篇 “A+B” 的工作(A = Prompt-tuning, B = Multi-task Learning)。
基于 Prompt 的工作正值大热的时期,而通过在不同种类的微调任务上多任务学习提升性能也并不新颖, 例如早期 Microsoft 的工作 MT-DNN,Facebook 的工作 MUPPET。
不过,笔者认为,这样的 A+B,或许是未来 通用自然语言处理模型 的一个可能的解决方案。
首先通过大量的无标记语料训练千亿参数级别的大规模自回归预训练模型,第二步,通过设计指令(Instruction Tuning)的方式让这样的模型能够对理解和生成任务进行微调。
在微调的过程中可以采用类似于 课程学习 的方式,先学习底层的任务(如命名实体识别,序列语义标注),再学习上层的任务(如逻辑推理,问答);先学习资源丰富的任务(如英语/大数据任务),再学习资源较少的任务(如小语种、少数据任务),并利用 适配器(Adapter) 保留模型中任务专用的部分。最后,给出指令让模型面对新数据、新任务进行推理。
Prompt、Instruction,从 GPT-2 开始就有了吧。然而仔细想,却发现之前研究主要是 针对单任务的少样本情况,并没有研究这种 多任务的 Prompt、指令泛化。
这个研究的应用潜力显然更大,而且谷歌和 OpenAI 居然不谋而合都在做,同时在应用时使用者还可以对任务进行一定的精调:

再往深想,Instruction 和 Prompt 一样存在 手工设计模版 的问题,怎样把 模版参数化、或者 自动挖掘大量模版 从而提升指令精调的效果,也是一个方向。
在介绍 InstructGPT 和 ChatGPT 之前,还有两份比较重要的前置工作,即 Reinforcement Learning from Human Feedback(RLHF),如何从用户的明确需求中学习。
Fine-Tuning Language Models from Human Preferences
《Fine-Tuning Language Models from Human Preferences》
URL:https://arxiv.org/abs/1909.08593
Code:https://github.com/openai/lm-human-preferences
单位:OpenAI
OpenAI‘s blog:Fine-tuning GPT-2 from human preferences
Learning to Summarize with Human Feedback
《Learning to Summarize with Human Feedback》
URL:
Code:
InstructGPT
《》
URL:
Code:
单位:
InstructGPT 从模型结构上与上一篇文章几乎一摸一样,但它通向了 更为宽广的领域。通过 收集 带有 更多 人类 Instruction 的自然语言文本句子,使其可以完成各种 NLP 任务,正式进化为一个 全能模型。
一句话:更大规模、更全面的数据(包含 Instruction)【大力出奇迹】
整体框架

###
ChatGPT
按照李沐在讲解 InstructGPT 论文视频中的说法:OpenAI 估计会在 ChatGPT 面世后的几个月后,应该就会出论文了(经典的先发布、再写论文)。
因此,截至目前(2023-03-12)还是没有 ChatGPT 的论文。
更多
相关论文
参考
FLAN
OpenAI Playground:davinci-instruct-beta
InstructGPT
CSDN:一文带你了解爆火的Chat GPT
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/03/12/Instruction-tuning/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)