视频检索 视频片段检索:给定查询内容(通常是文本/自然语言、也可以是视频片段、图片、音频片段等)和一个未裁剪的长视频,视频片段检索任务需要在这个长视频中检索出一个片段,使得这一片段的语义信息能够与给定的查询内容相匹配/对应。
golden moment
与之相关的研究:
深度学习
多模态数据的表示
目标检测
文本图像匹配
时序动作检测:在一段未剪辑的视频中找到动作开始和结束的时间,并对动作进行分类
Text-Video Retrival
基于文本/自然语言查询的视频片段检索任务
相关术语:
-
时域语言定位(Temporally Language Grounding)
- 给定一句自然语言描述,模型需要在未剪裁的视频(Untrimmed Videos)中确定该描述的活动发生的时间片段(起始时间,终止时间)
-
时序动作定位 (Temporal Action Localization) 也称为时序动作检测 (Temporal Action Detection),是视频理解的另一个重要领域
- 时序动作定位不仅要预测视频中包含了什么动作,还要预测动作的起始和终止时刻
- 相比于动作识别,时序动作定位更接近现实场景
- Video Grounding
- text-to-clip retrieval
query-based moment retrieval
- Temporal Sentence Grounding
Natural Language Moment Retrieval
- temporal moment localization
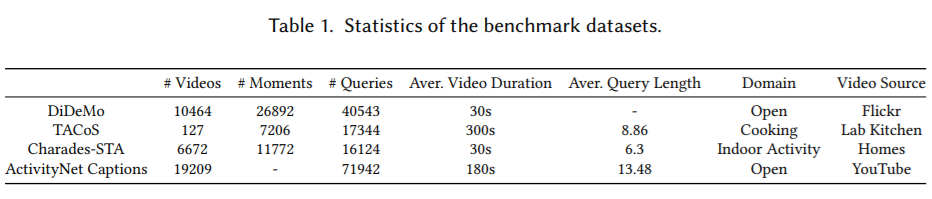
数据集
- TACoS
- 项目地址:https://www.coli.uni-saarland.de/projects/smile/page.php?id=software
-
Charades-STA
- https://github.com/jiyanggao/TALL
- https://prior.allenai.org/projects/charades

- DiDeMo
- paperwithcode:Natural Language Moment Retrieval on DiDeMo ==VLG-Net==
- github:https://github.com/LisaAnne/LocalizingMoments
- ActivityNet Captions
- 项目地址:https://cs.stanford.edu/people/ranjaykrishna/densevid/
- MAD(Movie Audio Descriptions)
- 项目地址:https://github.com/Soldelli/MAD
- MAD-v1:《MAD: A Scalable Dataset for Language Grounding in Videos From Movie Audio Descriptions》==CVPR 2022==
- URL:https://arxiv.org/abs/2112.00431
- MAD-v2:《AutoAD: Movie Description in Context》==CVPR 2023==
评估指标(metric)
R@n,IoU=m
排名前 n 个模型输出结果中,至少存在一个的 IoU 值超过 ground truth m 的比例
2017(2/2)
[!Info+年度关键词]
两条路
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| TALL: Temporal Activity Localization via Language Query |
CTRL 模型(Cross-modal Temporal Regression Localizer) | ICCV 2017 | TaCoS Charades-STA |
开山之作 |
| Localizing Moments in Video with Natural Language |
MCN 模型(Moment Context Network) | ICCV 2017 | DiDeMo |
TALL-CTRL 
《TALL: Temporal Activity Localization via Language Query》
- URL:http://arxiv.org/abs/1705.02101
- Code:https://github.com/jiyanggao/TALL ==TensorFlow==
- 会议:ICCV 2017
开山之作,点出该问题需要解决的两大困难:
- 作为跨模态任务,如何得到适当的文本和视频表示特征,以允许跨模态匹配操作和完成语言查询。
- 理论上可以生成无限粒度的视频片段,然后逐一比较。但时间消耗过大,那么如何能够从有限粒度的滑动窗口做到准确的具体帧定位。
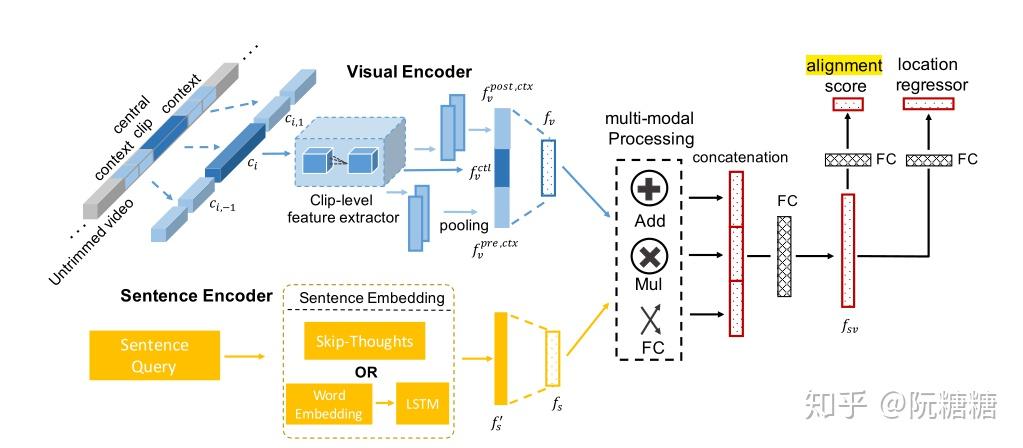
方法:
- 特征抽取:使用全局的 sentence2vec 和 C3D
- 模态交互:逐元素加、逐元素乘、FC、拼接
- 多任务:对齐分数 + 回归(Temporal Regression)
MCN
《Localizing Moments in Video with Natural Language》
- URL:https://arxiv.org/abs/1708.01641
- Code:https://github.com/LisaAnne/LocalizingMoments ==Official, Caffe2==
- DiDeMo 数据集:Google Driver & Google Driver
- 会议:ICCV 2017
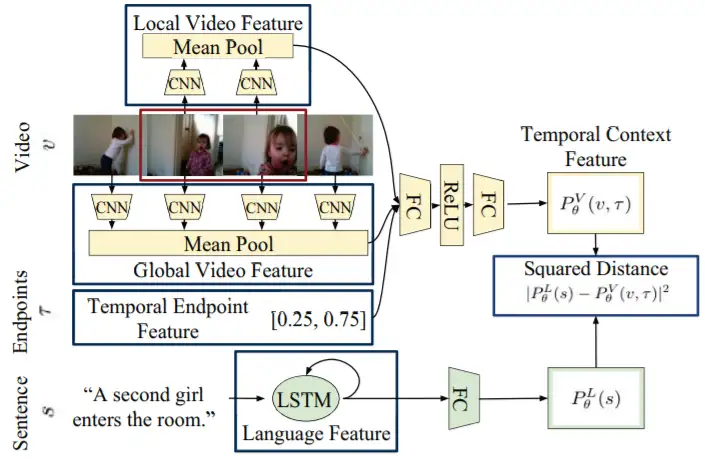
方法:
- 特征抽取:
- 使用全局的 LSTM;
- 使用全局与局部的 VGG;
- 提取 Temporal Endpoint Feature;
- 模态交互:无
- 多任务:模态间的均方差(而不是预测对齐分数),同时使用 RGB 和 optical flow(光流)
2018(2/5)
[!Info+年度关键词]
上下文(Context)
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| Cross-modal Moment Localization in Videos |
ROLE | MM 2018 | Charades-STA DiDeMo |
|
| Attentive Moment Retrieval in Videos |
ACRN | SIGIR 2018 | DiDeMo TACoS |
|
| Localizing Moments in Video with Temporal Language | EMNLP 2018 ==CCF-B== | |||
| Temporally Grounding Natural Sentence in Video | EMNLP 2018 | |||
| Multi-modal Circulant Fusion for Video-to-Language and Backward | IJCAI 2018 |
Cross-modal Moment Localization in Videos
《Cross-modal Moment Localization in Videos》
- URL:https://dl.acm.org/doi/10.1145/3240508.3240549
- Official Code:
- Google Driver:https://drive.google.com/drive/folders/1lVxcC4TDGcGtB_tTAp4z6i_WmZHpznc2
- https://github.com/Last-Malloc/ROLE
- 主页:https://acmmm18.wixsite.com/role
强调时间语态问题,即句子中的 “先”、“前” 往往被忽视,需要更细致的理解。
方法:尝试结合 上下文,用文本给视频加 Attention

Attentive Moment Retrieval in Videos
《Attentive Moment Retrieval in Videos》
- URL:https://dl.acm.org/doi/abs/10.1145/3209978.3210003
- 主页:https://sigir2018.wixsite.com/acrn
- ACRN’s Code:百度网盘
方法:尝试结合 上下文,用视频给文本加 Attention

Input: A set of moment candidates and the given query.
Output: A ranking model mapping each moment-query pair to a relevance score and estimating their location offsets of the golden moment.
As Figure illustrates, our proposed ACRN model comprises of the following components:
- The memory attention network leverages the weighting contexts to enhance the visual embedding of each moment;
The cross-modal fusion network explores the intra-modal and the inter-modal feature interactions to generate the moment-query representations;
- The regression network estimates the relevance scores and predicts the location o sets of the golden moments.
Localizing Moments in Video with Temporal Language
2019
[!Info+年度关键词]
文本和视频的细粒化;强化学习;候选框关系/生成;弱监督
RL-based、Candidate-based
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| Read, Watch, and Move Reinforcement Learning for Temporally Grounding Natural Language Descriptions in Videos |
AAAI 2019 | 强化学习(首次) | ||
| MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment |
MAN (Moment Alignment Network) |
CVPR 2019 | DiDeMo Charades-STA |
|
| Language-Driven Temporal Activity Localization A Semantic Matching Reinforcement Learning Model |
CVPR 2019 | 强化学习 | ||
|
Weakly Supervised Video Moment Retrieval From Text Queries |
TGA (Text Guided Attention) |
CVPR 2019 | DiDeMo Charades-STA |
弱监督 (首次) |
| Cross-Modal Video Moment Retrieval with Spatial and Language-Temporal Attention |
SLTA (Spatial and Language-Temporal Attention model) |
ICMR 2019 ==CCF-B== | TACoS Charades-STA DiDeMo |
|
除了 强化学习 方法在某种程度上可以直接做到定位,但大多数方法还是 基于候选集。
但是生成的候选集又太多了,所以也有几篇在候选集身上打主意的方法。
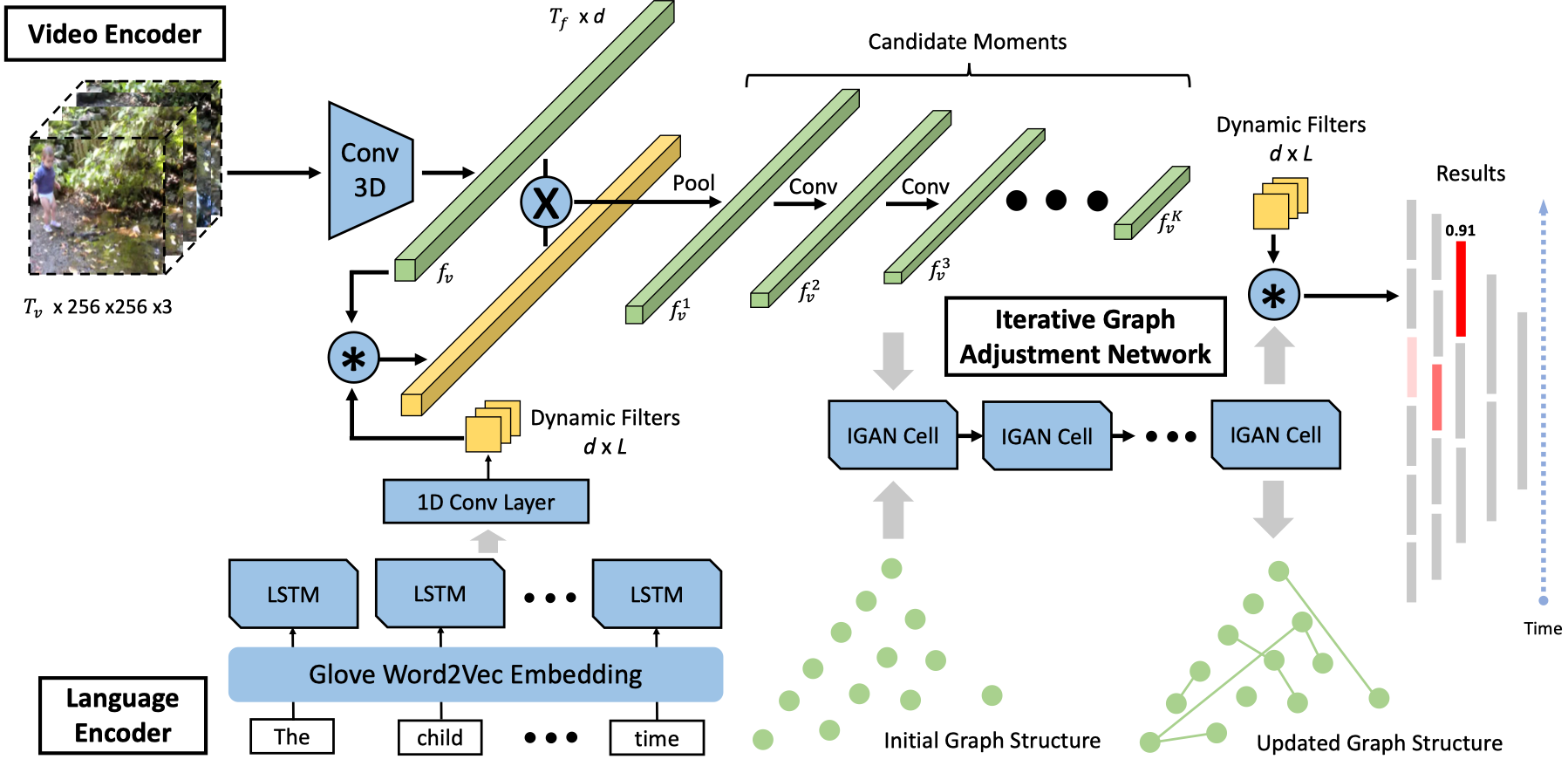
MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment
MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment
- URL:https://arxiv.org/abs/1812.00087
- Official Code:https://github.com/dazhang-cv/MAN ==TensorFlow==
- 解决问题:根据自然语言的一句话检索视频所对应的帧片段,并同时考虑到 语义错位(e.g. the second time)和 结构错位(候选集之间的处理是独立的,e.g. after)。
- 特征抽取:LSTM 和 I3D
- 创新点:Iterative graph adjustment network,即尝试对所生成的各个候选片段构图,并设计一个迭代图调整网络来 学习候选时刻之间的关系。
MAN 模型如下所示,主要包括三部分:
- a language encoder
- a video encoder
- IGAN (an iterative graph adjustment network)
Weakly Supervised Video Moment Retrieval From Text Queries
Weakly Supervised Video Moment Retrieval From Text Queries
- URL:https://arxiv.org/abs/1904.03282
- Official Code:https://github.com/niluthpol/weak_supervised_video_moment ==PyTorch==
- DeepAI:https://deepai.org/publication/weakly-supervised-video-moment-retrieval-from-text-queries
动机:标注句子边界太耗时,且在实践中不可扩展
-
方法:通过 弱监督 的方式,利用 Text Guided Attention(TGA) 来学习 隐式对齐 文本-视频对 中的文本与视频,而不是直接学习文本描述对应的时间边界(起始、终止时间)。
- 只使用视频级别的文本描述
- 减少了手动标注数据带来的问题,能够更容易的获取标注的数据。


Cross-Modal Video Moment Retrieval with Spatial and Language-Temporal Attention
Cross-Modal Video Moment Retrieval with Spatial and Language-Temporal Attention
- URL:https://dl.acm.org/doi/10.1145/3323873.3325019
- Official Code:https://github.com/BonnieHuangxin/SLTA ==TensorFlow==
- 主页:https://icmr2019.wixsite.com/slta
- 知乎博客:https://zhuanlan.zhihu.com/p/64852440
识别关键字、最相关物体,并关注物体间的交互
- 动机:没有关注空间目标信息和文本的语义对齐,且需要结合视频的时空信息。
- 方法:
- 特征抽取:全局 + 局部,即全局用 C3D 和 BiLSTM;然后全局特征分别给局部(词和目标)加 attention 突出重点。
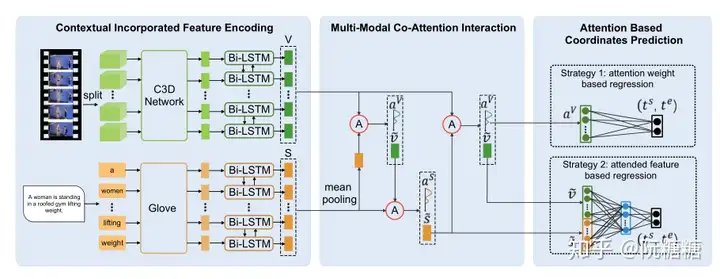
Spatial and Language-Temporal Attention model(SLTA)即 空间与语言-时序注意力。它包括 两个分支注意力网络,分别为 空间注意力、语言-时序注意力。
首先,我们提取视频帧 object-level 的局部特征,并通过 空间注意力 来关注与 query 最相关的局部特征(例如,局部特征 “girl”,“cup”),然后对连续帧上的局部特征序列进行 encoding,以捕获这些 object 之间的交互信息(例如,涉及这两个 object 的交互动作 “pour”)
同时,利用 语言-时序注意力网络 基于视频片段上下文信息来强调 query 中的关键词
因此,我们提出的 两个注意力子网络 可以 识别视频中最相关的物体 和 物体间的交互,同时 关注 query 中的关键字。

ABLR
《To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression》
- URL:https://arxiv.org/abs/1804.07014
- 单位:清华大学、京东 AI Research
- Code:https://github.com/yytzsy/ABLR_code
这一篇论文主要有两个亮点:
- 去掉了滑动窗口算法;
- 引入 attention 进行跨模态信息的交互;
ACL
《MAC: Mining Activity Concepts for Language-based Temporal Localization》
- URL:https://arxiv.org/abs/1811.08925
- Code:https://github.com/runzhouge/MAC
- 会议:
这篇文章的方法是建立在 CTRL 模型之上的。它的亮点在于强化了两个模态之间动作语义信息的对应,提出了 Activity Concepts based Localizer(ACL)模型,模型结构如下图所示:
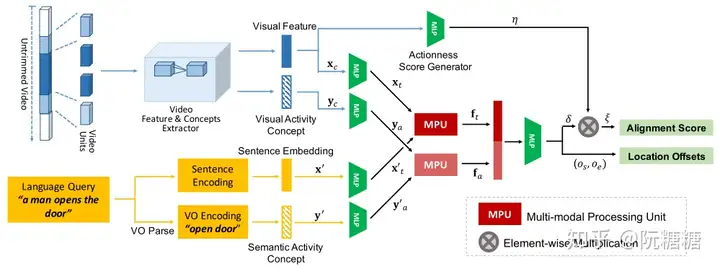
模型相比 CTRL 有了如下改变:
- video 不是直接滑窗生成候选片段,而是先以若干帧为单元得到单元级别的特征,再以连续单元得到候选片段的特征
- 视频单元特征的抽取针对不同数据集有使用 C3D 和I3D
引入 Activity Concept。作者提前准备一个列表,是视频描述中所有涉及的动名词组。候选片段特征和句子特征分别还有对应的动作语义特征(对应上图 Visual Activity Concept 和 Semantic Activity Concept)
句子描述和视频除了特征上的匹配,还加上了两者动作语义上的特征匹配。两个匹配信息融合,作为最后对齐 loss 和定位回归 loss 的输入
- 由于并不是所有视频段都存在动作语义概念,每个候选视频段还有一个 Actionness score 用来衡量该候选视频段是否存在动作
- 这个 score 有用(在求 loss 的时候)
2020(3/22)
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language |
2D-TAN | AAAI 2020 | Charades-STA TACoS ActivityNet Captions |
|
| Moment Retrieval via Cross-Modal Interaction Networks With Query Reconstruction |
TIP 2020 | |||
|
Adversarial Video Moment Retrieval by Jointly Modeling Ranking and Localization |
AVMR | MM 2020 | Charades-STA TACoS |
对抗训练 |
Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language
- URL:https://arxiv.org/abs/1912.03590
- Official Code:https://github.com/microsoft/VideoX/tree/master/2D-TAN
- Others Code:optimized implementation
参考博客:
出自 AAAI 2020,Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language,2019 ICCV HACS 动作定位挑战赛冠军方案。
- Motivation:以往模型一般单独考虑时间,忽视了时间的依赖性。(不能在当前时刻对其他时刻进行预测)
- Method:将 定位起始解耦,时间从一维变为二维,即变成二维矩阵,预测每一个位置的 score。这样做的好处是特征图中每个位置的视频特征都与文本特征融合,得到相似度特征图(图像中左侧的绿色立方体),而这个矩阵的大小可以直接通过切分视频的细粒度做到,然后将融合后的相似性特征映射通过一系列卷积层,并逐层建立各段与其周围段之间的关系,最后将考虑邻域关系的相似度特征输入到完全连通层中,得到最终的得分。
1)二维时间图
目前,定位视频中的某一片段大多采用以不同大小,交叠比的 sliding window 对于一个视频产生诸多的 proposals(候选者),再对这些 proposals 进行分类与回归。
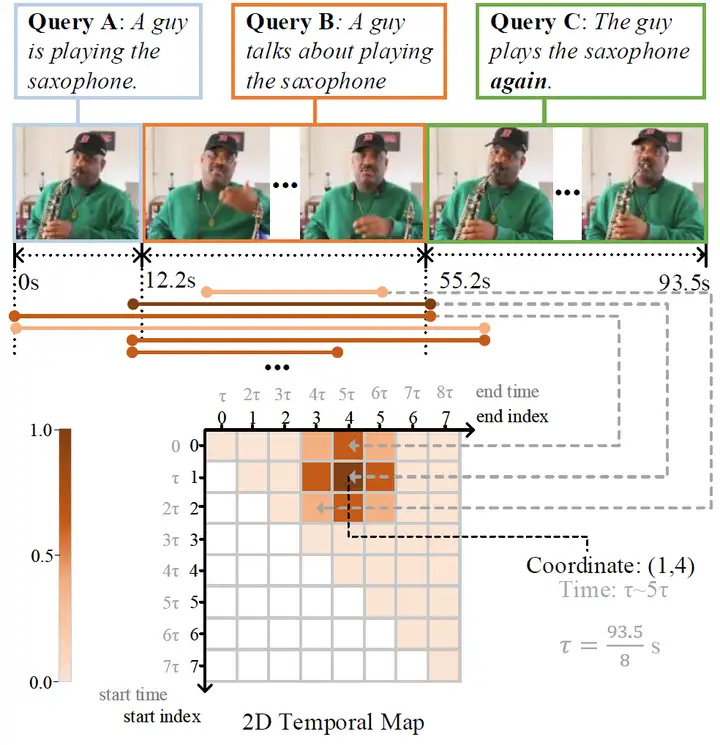
2D-TAN 中提出的二维时间图可以看成一种 “优雅的 sliding window”:如下图所示,以两个轴分别代表开始时间段和结束时间段,构建 $N\times N$ 的 2D map。
这里的一段 $\tau = duration / N$,$duration$ 是整个视频的时长,$N$ 为 2D map 的大小。
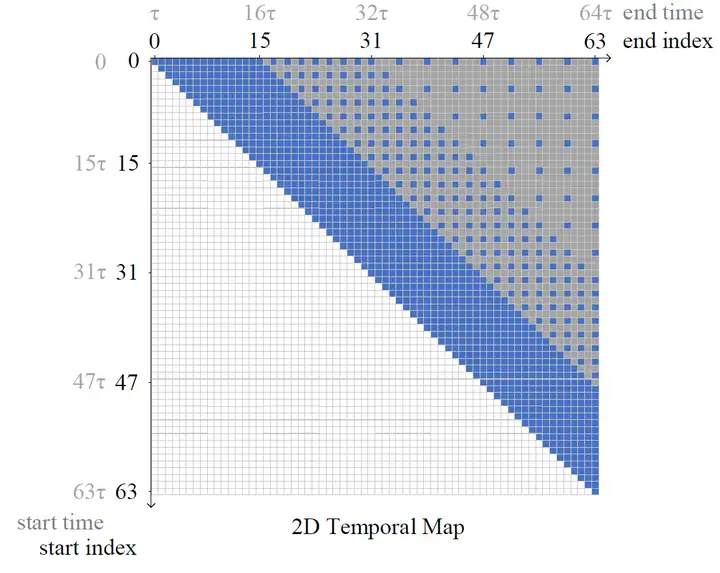
这张 2D map 里的 每一个 cell 都代表着一个时间片段,且只有 右上角半区 的时间片段为有效的(起始时间<结束时间)。
那么,我们只需要判断每个 cell 对应的时间与给定 query 的匹配度即可。为了降低计算量,作者设计了 采样机制,只对上方蓝色点的 cell 进行训练/推理。
2)视觉-语言特征融合
2D map 可以用来承载视频的视觉特征,每一个 cell 对应的 $d^V$ 维视频特征填入到 2D map 中,然后我们就可以得到 $N\times N\times d^V$ 的 2D feature map。
接着,将查询 query 中的每个文本单词转换成 Glove 词向量,再将词向量依次通过 LSTM 网络,使用其最后一层的输出作为文本语句的特征。
然后,将文本语句特征与 2D feature map 的每一个 cell 进行点乘(Hadamard Product),即可得到视觉-语言融合后的 2D feature map。
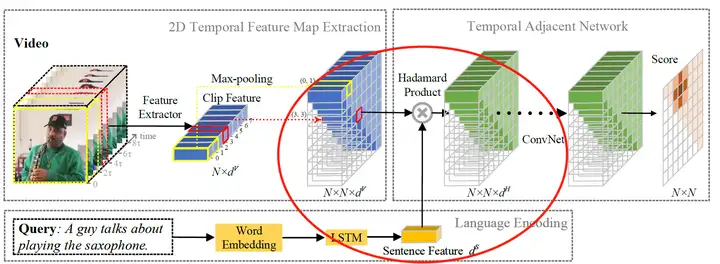
3)时间邻近卷积
这部分在上述结构图上未曾详细表现出来(只有一个简单的 ConvNet 字样),但是个人认为它才是文章的核心思想所在。
前人的工作都是 独立地匹配句子和一个片段,而忽略了其他片段对其影响。例如,当我们要定位 “这个人又吹起了萨克斯 The guy plays the saxophone again”,如果只看后面的视频而不看前面的,我们不可能在视频中定位到这个片段。
我们知道,卷积网络是具有感受野的,而 2D feature map 的形式由非常适用于卷积,因此作者在这里加入 多层卷积 再次得到 2D feature map,而 此时的每一个 cell 都将具有邻近 cell 的信息,而非单独考虑每个片段,可以学习更具有区分性的特征。
4)小问题
- 二维图上的点扩展到向量呢?
- 直觉来看,由点变成向量,反而没那么灵活了
- 穷举地更详尽了,为什么反而计算成本降低了呢?
- 因为每个片段都被降维了
- 这样能把关键信息展示出来吗?
- 是不是说最后的 检索误差就是 $\tau$ 呢?那么误差还挺大的。
- $\tau$ 是怎么得到的呢?每个视频所对应的 $\tau$ 是否一样?
5)更多:MS-2D-TAN(新的改进)
作者对于 2D-TAN 的改进:MS-2D-TAN

Moment Retrieval via Cross-Modal Interaction Networks With Query Reconstruction
Moment Retrieval via Cross-Modal Interaction Networks With Query Reconstruction
- URL:https://ieeexplore.ieee.org/abstract/document/8962274
- Code:



Adversarial Video Moment Retrieval by Jointly Modeling Ranking and Localization
Adversarial Video Moment Retrieval by Jointly Modeling Ranking and Localization
- URL:https://dl.acm.org/doi/abs/10.1145/3394171.3413841
- Official Code:https://github.com/yawenzeng/AVMR ==PyTorch==
- 动机:强化学习定位不稳定,检索任务候选框效率低。
- 方法:用对抗学习联合建模,即用强化学习定位来生成候选,进而在生成候选集上进行检索。
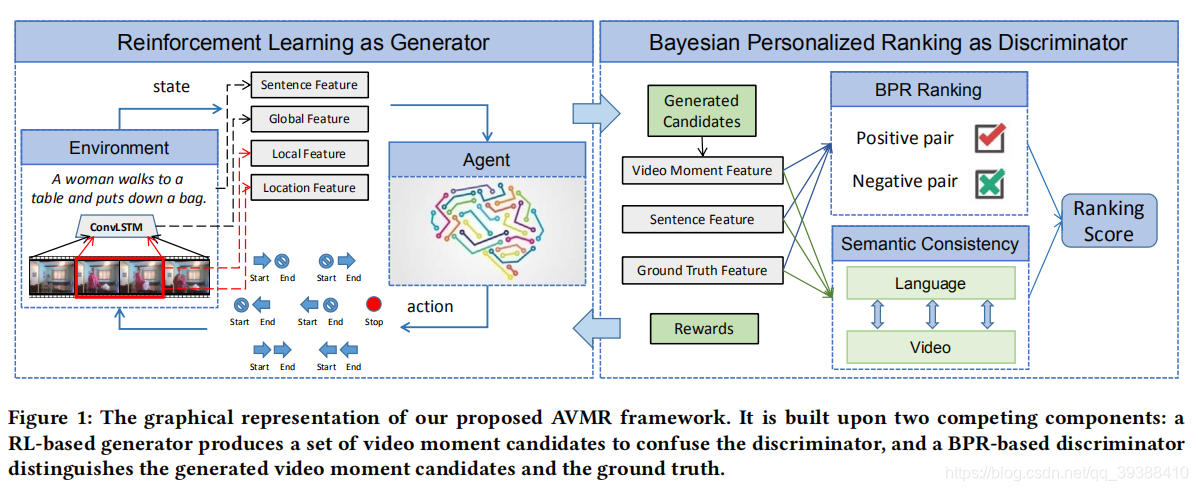
该作者的扩展论文也整理了一些相关 RL-based 定位方法和 Candidate-based 检索方法的表格:
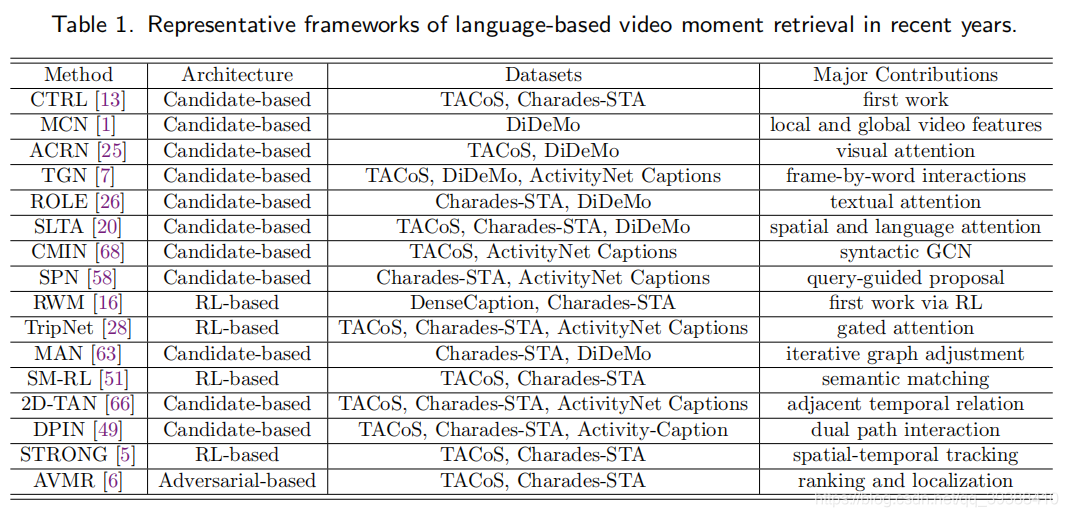
图片来源:[TOMM2021] Moment is Important: Language-Based Video Moment Retrieval via Adversarial Learning
2021(2/11)
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| Multi-Modal Relational Graph for Cross-Modal Video Moment Retrieval |
CVPR 2021 | |||
| A Closer Look at Temporal Sentence Grounding in Videos_ Datasets and Metrics |
||||
| Zero-shot Natural Language Video Localization | PSVL | ICCV 2021 | Charades-STA ActivityNet-Captions |
Zero-shot |
Multi-Modal Relational Graph for Cross-Modal Video Moment Retrieval
Multi-Modal Relational Graph for Cross-Modal Video Moment Retrieval
A Closer Look at Temporal Sentence Grounding in Videos_ Datasets and Metrics
A Closer Look at Temporal Sentence Grounding in Videos_ Datasets and Metrics
Zero-shot Natural Language Video Localization 
Zero-shot Natural Language Video Localization
- URL:
- Code:https://github.com/gistvision/PSVL ==代码中并没有包括 候选 Temporal 生成、Simplified Sentence 的生成==
- 部分代码参考 LGI repo
- 作者:(韩国)

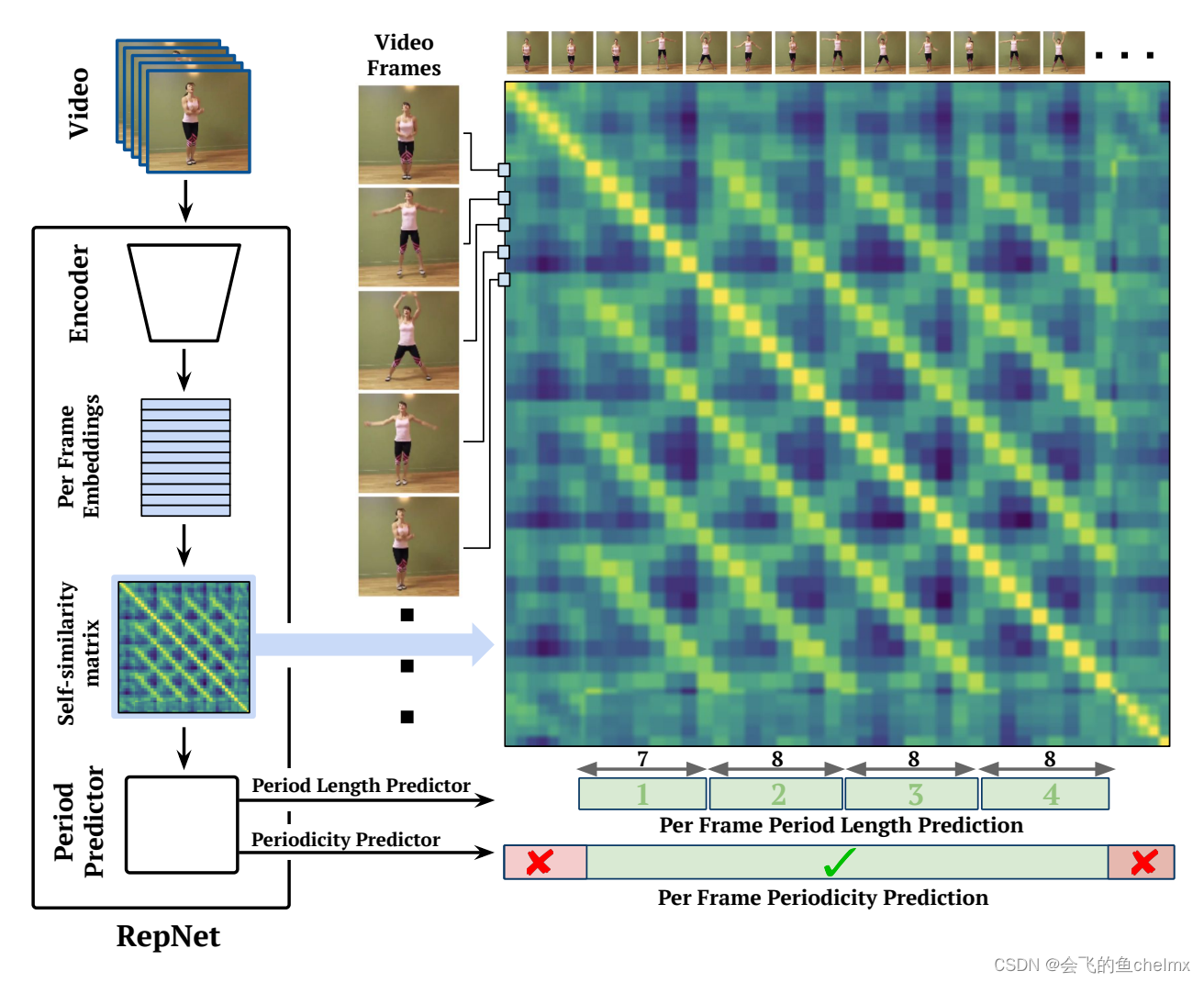
1)Temporal Event Proposal(TEP,时间事件提案) find event boundaries 找出 meaningful temporal segments(也是难点,如何定义?) 计算 frame features 的 self-similarity matrix,然后使用 k-means 进行聚类;由于 video 可以存在多个与 query 相关的片段,所以使用 uniform sample 一些 segments
使用 self-similarity matrix 的想法借鉴 《Counting Out Time: Class Agnostic Video Repetition Counting in the Wild》的 Temporal Self-similarity Matrix (TSM)
在得到每帧 $v_i$ 的 hidden embedding $x_i$ 后,通过计算所有 $x_i$ 和 $x_j$ 对之间的相似性 $S_{ij} = f(x_i, x_j)$,从而构造自相似矩阵 $S$,其中 $f(\cdot)$ 是自相似性函数。
这里使用 平方欧氏距离的负数 作为相似性函数,即 $f(a, b) = - a-b ^2$,然后逐行进行 softmax 操作。
《Counting Out Time: Class Agnostic Video Repetition Counting in the Wild》
- URL:https://arxiv.org/abs/2006.15418
- 项目主页:https://sites.google.com/view/repnet
- 单位:Google Research and DeepMind
- Unofficial Code:https://github.com/benjaminjellis/RepNetPyTorch
- CSDN:《Counting Out Time: Class Agnostic Video Repetition Counting in the Wild》论文笔记

问题:如果一段视频中包含的全是重复的动作片段,那么,理想情况是模型能给出所有的答案,而不是一个结果,这就涉及到了一段视频中存在多个目标答案的问题。
如下所示,当我们的 query 是 “一个女孩在运动”,那么将有多个片段符合。
2)Pseudo-Query Generation(生成伪查询,PQ)
对于每个发现的时间区域 (TEP),我们生成相应的自然语言查询
3)NLVL Model
包括三个部分:
- Contextual Feature Encoding
- Multi-modal Cross Attention
- WVA(Word guide Attention)
- VWA(Video guide Attention)
- MCA(Multi-modal Cross Attention)
- Temporal Regression
不足:
train:simplified sentences 不够 natural(尽管作者的实验表明,simplified sentences 的效果不差) 使用 object detector,可能出现不曾出现的object,同时也可能识别不太相关的 object(尽管使用 k-mean 选择前 K 个)
inference:由于是 trained 使用 simplified sentences,导致 inference 时需要使用额外的词性标注器,将 query 转换成 simplified sentences(扩展性不够)
# (num_frames, hidden_dim)
vid: E8468 feats shape: (91, 1024)
vid: E8468 feats shape: (91, 1024)
vid: MZOPX feats shape: (109, 1024)
vid: MZOPX feats shape: (109, 1024)
vid: DZNYK feats shape: (84, 1024)
vid: DZNYK feats shape: (84, 1024)
vid: DZNYK feats shape: (84, 1024)
vid: DZNYK feats shape: (84, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: DM2HW feats shape: (62, 1024)
vid: JPUUF feats shape: (99, 1024)
vid: O0R1A feats shape: (92, 1024)
vid: O0R1A feats shape: (92, 1024)
# Training from scratch
python train.py --model CrossModalityTwostageAttention --config "YOUR CONFIG PATH"
# Evaluation
python inference.py --model CrossModalityTwostageAttention --config "YOUR CONFIG PATH"
CUDA_VISIBLE_DEVICES=2 nohup python -u train.py > train.log 2>&1 &
-> 8246
tacos
timestamps: [158, 200] 单位: clip/frame
fps: 29.4 单位 clip/frame
num_frames: 视频的总 frames 数
duration:单位 s = num_frames / fps
》真实的 timestamp:timestamp / fps
charades / activitynet caption
timestamps:[0.5, 1.3] 单位 s
durantion: 单位 s
获取 start end timestamp 对应到第几个 clip(index)
data num_segments: 128
video feats num_segements: nfeats
- 如果 nfeats 小于等于设定的 num_segments 值,则 stride = 1(正常去所有clip的特征)
- 如果 nfeats 大于 num_segments,stride = nfeats*1.0 / num_segments(跳着选取 clip 特征)
"vids": vid,
"qids": idx,
"timestamps": GT [s, e] (second)
"duration": duration (second)
"query_lengths":
"query_labels": long tensor [1, L_q_max]
"query_masks": [1, L_q_max] 用于 query padding
"grounding_start_pos: torch.FloatTensor([start_pos]), # [1]; normalized
"grounding_end_pos": torch.FloatTensor([end_pos]), # [1]; normalized
"nfeats": float tensor
"video_feats": float tensor
"video_masks": byte tensor 用于 video segment padding
"attention_masks": tensor 用于保证仅 [start_index, end_index] 区间的 feature 参与计算
Boundary-sensitive Pre-training for Temporal Localization in Videos
《Boundary-sensitive Pre-training for Temporal Localization in Videos》
- URL:https://arxiv.org/abs/2011.10830
- Official Code:https://github.com/frostinassiky/bsp ==里面没有代码==
- 单位:Samsung AI Centre Cambridge
- 会议:ICCV 2021
BSP 通过设计 边界敏感(Boundary-sensitive)代理任务 并收集具有时间边界的 合成数据集,提出了 TSGV 的预训练范式
根据 类别和动作速度 的不同提出了 三种合成新视频的方式,使用已经存在的动作分类数据集去合成一个新的带有起止时间的数据集,此方法 不需要额外的人工标注。
三种视频合成方法
作者使用已有视频动作分类数据集(如 Kinetics),通过四种方式合成新的数据集,它们分别是:
- 不同类别边界(Diff-class)
- 相同类别边界(Same-calss)
- 不同速度边界(Diff-speed)
- 相同速度边界(Same-speed)
- 为了概念的完整性而提出
- 从原始数据集中直接取得的视频

预训练方法
作者提出两种可行的方式使用合成数据集进行预训练的方法:
- 分类
- 每一种合成视频视为独立的一类
- 使用合成数据的四种类别标签进行训练,输出合成视频 属于每种类别的概率
- 使用交叉熵损失函数(cross entropy)
- 回归
- 将时间 ground truth 转换成一维高斯热度图(1D Gaussian heatmap)来保证稳定训练
- 使用 smooth L1 Loss
与基于动作分类的预训练模型结合
为了将文中提出的预训练模型与现有的预训练模型相结合,作者提出了三种结合的方式,分别是:
- two stream
- two head
- feature distillation
可参考下图理解。
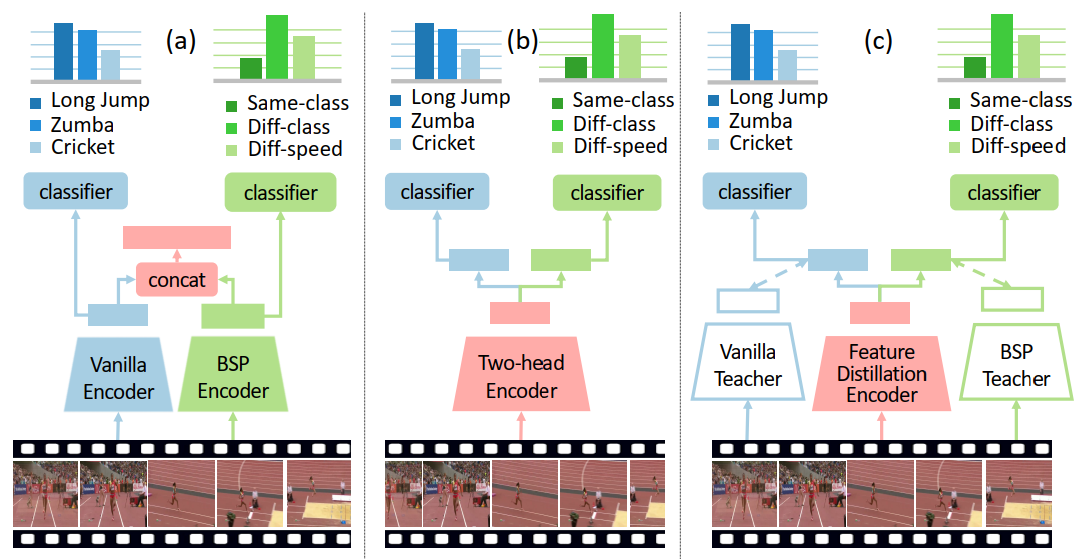
实验
参考:
Learning Video Moment Retrieval Without a Single Annotated Video
《Learning Video Moment Retrieval Without a Single Annotated Video》
- URL:
- 单位:中国科学院
- 会议:TCSVT
On Pursuit of Designing Multi-modal Transformer for Video Grounding
《On Pursuit of Designing Multi-modal Transformer for Video Grounding》
- URL:https://arxiv.org/abs/2109.06085
- 单位:北京大学、鹏城实验室
- 会议:EMNLP 2021 ==CCF-B==
GTR builds an end-to-end framework to learn TSGV from raw videos directly.
Video grounding aims to localize the temporal segment corresponding to a sentence query from an untrimmed video.
Almost all existing video grounding methods fall into two frameworks: 1) Top-down model: It predefines a set of segment candidates and then conducts segment classification and regression. 2) Bottom-up model: It directly predicts frame-wise probabilities of the referential segment boundaries.
However, all these methods are not end-to-end, i.e., they always rely on some time-consuming post-processing steps to refine predictions.
To this end, we reformulate video grounding as a set prediction task and propose a novel end-to-end multi-modal Transformer model, dubbed as GTR. Specifically, GTR has two encoders for video and language encoding, and a cross-modal decoder for grounding prediction.
To facilitate the end-to-end training, we use a Cubic Embedding layer to transform the raw videos into a set of visual tokens. To better fuse these two modalities in the decoder, we design a new Multi-head Cross-Modal Attention. The whole GTR is optimized via a Many-to-One matching loss.
2022
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
| A Survey on Temporal Sentence Grounding in Videos |
综述 | |||
| The Elements of Temporal Sentence Grounding in Videos: A Survey and Future Directions |
综述 | |||
| Unsupervised Temporal Video Grounding with Deep Semantic Clustering |
AAAI 2022 | 无监督学习 | ||
| Point Prompt Tuning for Temporally Language Grounding |
SIGIR 2022 | Prompt-Learning (首次) |
||
| Language-free Training for Zero-shot Video Grounding | WACV 2023 ==CCF-B== | Charades-STA ActivityNet-Captions |
Zero-shot、Language-free Training | |
A Survey on Temporal Sentence Grounding in Videos
The Elements of Temporal Sentence Grounding in Videos: A Survey and Future Directions
Unsupervised Temporal Video Grounding with Deep Semantic Clustering ==无监督==
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
- URL:
- Code:
- 会议:AAAI 2022
- 单位:华中科技大学,微软
本文是 第一个 尝试在 无监督环境 中解决 TVG 问题的工作
深度语义聚类网络 DSCNet(Deep Semantic Clustering Network)
Point Prompt Tuning for Temporally Language Grounding ==监督,prompt==
Point Prompt Tuning for Temporally Language Grounding
- URL:
- Code:
Video Moment Retrieval from Text Queries via Single Frame Annotation ==无监督==
Video Moment Retrieval from Text Queries via Single Frame Annotation
- URL:https://arxiv.org/abs/2204.09409
- Code:https://github.com/r-cui/ViGA
- 会议:SIGIR 2022
通过 单帧注释 从文本查询中检索视频时刻 ==一瞥==
Language-free Training for Zero-shot Video Grounding ==无监督==
Language-free Training for Zero-shot Video Grounding
- URL:http://arxiv.org/abs/2210.12977
- Official Code:暂未开源
- Unofficial Code:https://github.com/aniki-ly/Language-free-Video-Moment-Retrieval
- Zero-Shot setting
在《Zero-shot natural language video localization》这篇的基础上,直接将视觉特征视为文本特征,然后使用 CLIP,从视觉特征来生成文本特征。
Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval ==无监督==
《Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval》
- URL:https://arxiv.org/abs/2210.12617
- 会议:EMNLP 2022 ==CCF-B==
- 单位:Seoul National University(首尔国立大学)
针对 narrative videos(叙事视频) 上的 Video corpus moment retrieval(VCMR)任务,首次提出了一个无监督的框架——Modal-specific Pseudo Query Generation Network (MPGN)。
具体来说,由于在 narrative videos 中,视觉和字幕(文本)能够提供一段对话的不同视角。因此,通过同时生成 Visual Pseudo Query 和 Textual Pseudo Query,能够更好的帮助模型完成 VCMR 任务,而无需人工标注的 annotations。
Visual Pesudo Query Generation
受视觉语言任务中提示工程的成功启发,我们采用视觉相关提示模块(visual-related prompt module)来生成视觉伪查询。
具体来说,借助 Image Caption 任务来生成相关的 Caption Text(作者使用的是预训练的 BLIP 模型)
Video-Language Model
为了有效地利用特定模态的伪查询,我们 交替地 在伪查询上训练模型。
At each training step, we randomly (uniformly) select one of the modal-specific pseudo queries.
我们的训练策略可以作为 数据增强,帮助模型 更鲁棒 地学习多模态信息。
为了公平比较,在模型的推理阶段,我们直接使用带注释的查询语句,而不是 visual-related prompt module。
具体实现
Pretrained RoBERTa model
局限性
Our framework requires the subtitles to include the name of the speaker. Therefore, it is not directly applicable to videos where the speaker is not specified (e.g., YouTube videos). ==视频中需要指定人名==
Also, as our framework utilizes verbal conversation between characters, it cannot guarantee performance in videos which do not include dialog (e.g., videos of cooking, sports, etc.) ==视频中必须包含对话==
Phrase-level Prediction for Video Temporal Localization
《Phrase-level Prediction for Video Temporal Localization》
- PDF:https://web.archive.org/web/20220628060407id_/https://dl.acm.org/doi/pdf/10.1145/3512527.3531382
- 会议:ICMR 2022 ==CCF-B==
- 单位:北京大学
- Official Code:https://github.com/sizhelee/PLPNet
出发点:
Although existing approaches gain a reasonable performance on sentence localization, the performance of phrase localization is far from satisfactory.
尽管现有方法在句子定位方面取得了合理的性能,但短语定位的性能却不尽如人意,如下图所示:

Explore-And-Match: Bridging Proposal-Based and Proposal-Free With Transformer for Sentence Grounding in Videos
《Explore-And-Match: Bridging Proposal-Based and Proposal-Free With Transformer for Sentence Grounding in Videos》
- URL:https://arxiv.org/abs/2201.10168
- 单位:韩国
- Official Code:https://github.com/sangminwoo/Explore-And-Match
将 Proposal-based 与 Proposal-free 两大类方法进行结合,从而在速度和准确率都得到了提升,如下图所示:
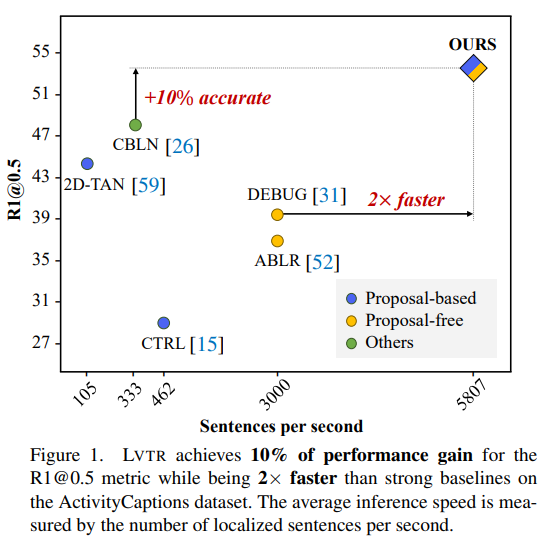
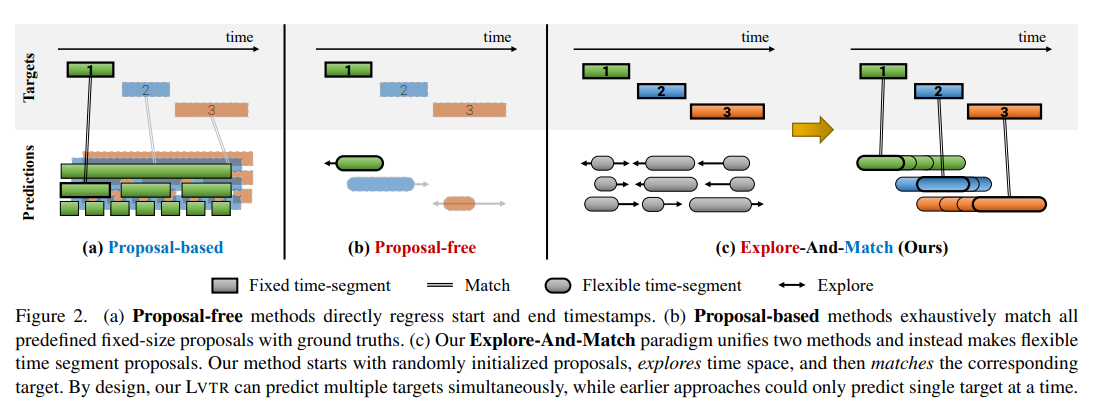
提出了端到端的、基于 Transformer 的 Language Video Transformer(LVTR)模型,如下所示:
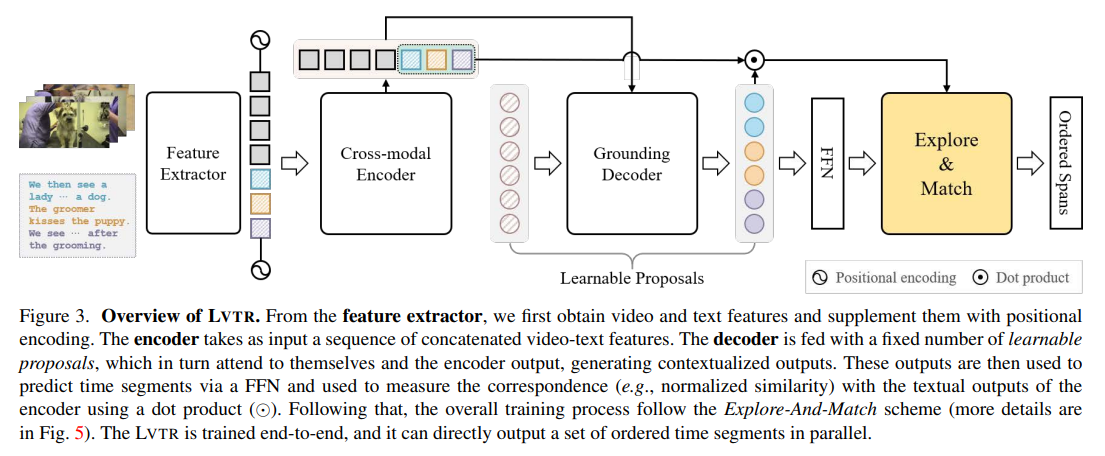
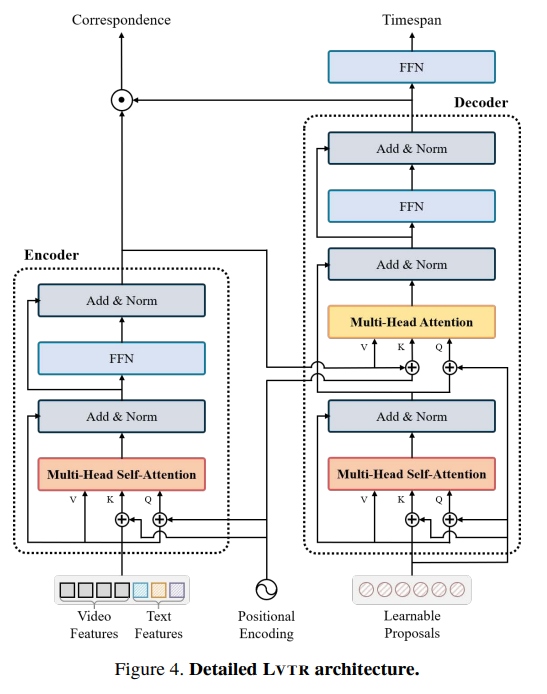
实验结果:
UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection
《UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection》
- URL:https://arxiv.org/abs/2203.12745
- code:https://github.com/TencentARC/UMT
- 会议:CVPR 2022
使用一个 统一的多模态模型 UMT,能够 兼容 Video Moment Retrieval 和 Highlight Detection 这两个任务。并且对于 Video Moment Retrieval 这一任务而言,能够同时 给出多个答案(如果有)。
将 Video Moment Retrieval 定义为一个 keypoint detection 问题。

Text-Based Temporal Localization of Novel Events
《Text-Based Temporal Localization of Novel Events》
- URL:https://link.springer.com/chapter/10.1007/978-3-031-19781-9_33
- Code:
- 会议:ECCV 2022
探究了 没见过的 queries 或者事件 的视频时刻定位问题,考虑模型的 泛化能力。
重组了Charades-STA 和 ActivityNet Captions 这两个基准数据集,得到 Charades-STA Unseen 和 ActivityNet Captions Unseen
最近关于基于文本的矩定位的工作在几个基准数据集上显示出高精度。然而,这些方法的训练和评估依赖于定位系统在 测试期间只会遇到训练集中可用的事件(即,看到的事件)的假设。
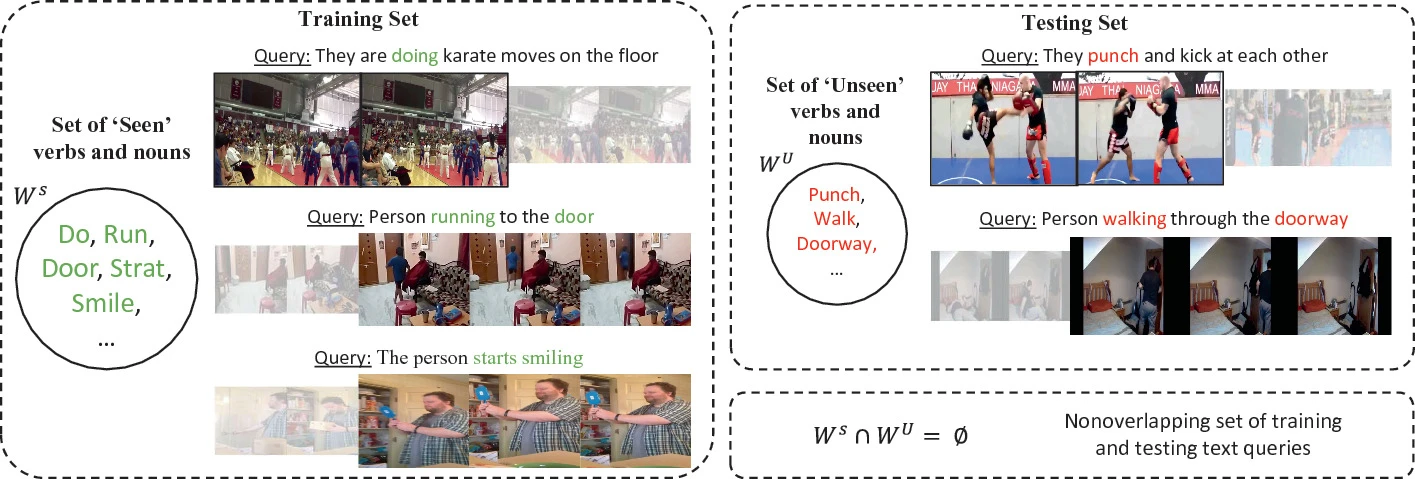
-
Partially Relevant Video Retrieval CCF-A
- ACM MM 2022 oral
- github
- paper’s url
- 参考:CSDN:ACM MM 2022 Oral | PRVR:全新的文本到视频跨模态检索子任务
- a
2023
Text-Visual Prompting for Efficient 2D Temporal Video Grounding
《Text-Visual Prompting for Efficient 2D Temporal Video Grounding》
- URL:
- Code:==暂未开源==
- 会议:CVPR 2023
出发点:
使用 Dense 3D CNN 来提取视频特征很花时间。
为了降低时间,作者尝试使用 2D CNN 来提取视频特征,使用 Prompts 来进行有效的训练,并提出了 text-visual prompting (TVP) 框架。
Last but not least, extensive experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement in Charades-STA and 30.77% improvement in ActivityNet Captions) and achieves 5x inference acceleration over TVG of using 3D visual features.
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
《Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training》
- URL:https://arxiv.org/abs/2303.00040
- Code:==暂未开源==
- 会议:CVPR 2023
通向 通用视频时刻检索
Video-Video Retrival
基于视频/图片查询的视频片段检索任务
2018
Video Re-localization
《Video Re-localization》
- URL:http://arxiv.org/abs/1808.01575
- 会议:ECCV 2018
单位:Tencent AI Lab、University of Rochester(罗切斯特大学)
- Official Code:https://github.com/fengyang0317/video_reloc
主要贡献:
- 首次提出了 Video Re-localization 任务
- 提出了一个基于 ActivityNet 的数据集,可直接用于 Video Re-localization 任务
- 现有的视频数据集都是用于 classification、temporal localization、captioning、video summarization
- 没有能够直接用于 Video Re-localization 任务
- 共有 200 classes,其中 160 classes 用于训练;20 classes 用于验证;20 classes 用于测试
-
提出了一个 cross gated bilinear matching model(基于注意力机制)
- 将 video re-localization 任务建模为一个 分类问题
每个时间帧都可以被预测四类:starting point、ending point、inside the segment、outside the segment
- 包含三个部分:
video feature aggregation(聚合):使用 LSTM 分别对 query 和 reference video 进行聚合
cross gated bilinear matching:基于注意力机制,对 query 和 reference video feature 进行交互;然后使用 LSTM 对聚合后的 feature 进行处理
localization:使用 LSTM 接一个 softmax,输出一个四维的向量,分别对应四个类别

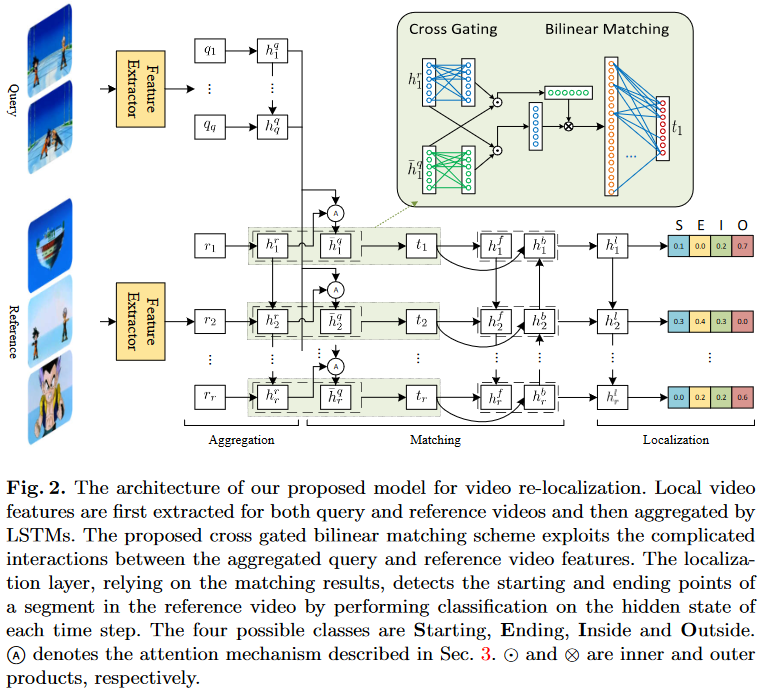

2019
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
2020
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
Weakly-Supervised Video Re-Localization with Multiscale Attention Model
《Weakly-Supervised Video Re-Localization with Multiscale Attention Model》
URL:https://doi.org/10.1609/aaai.v34i07.6763
会议:AAAI 2020
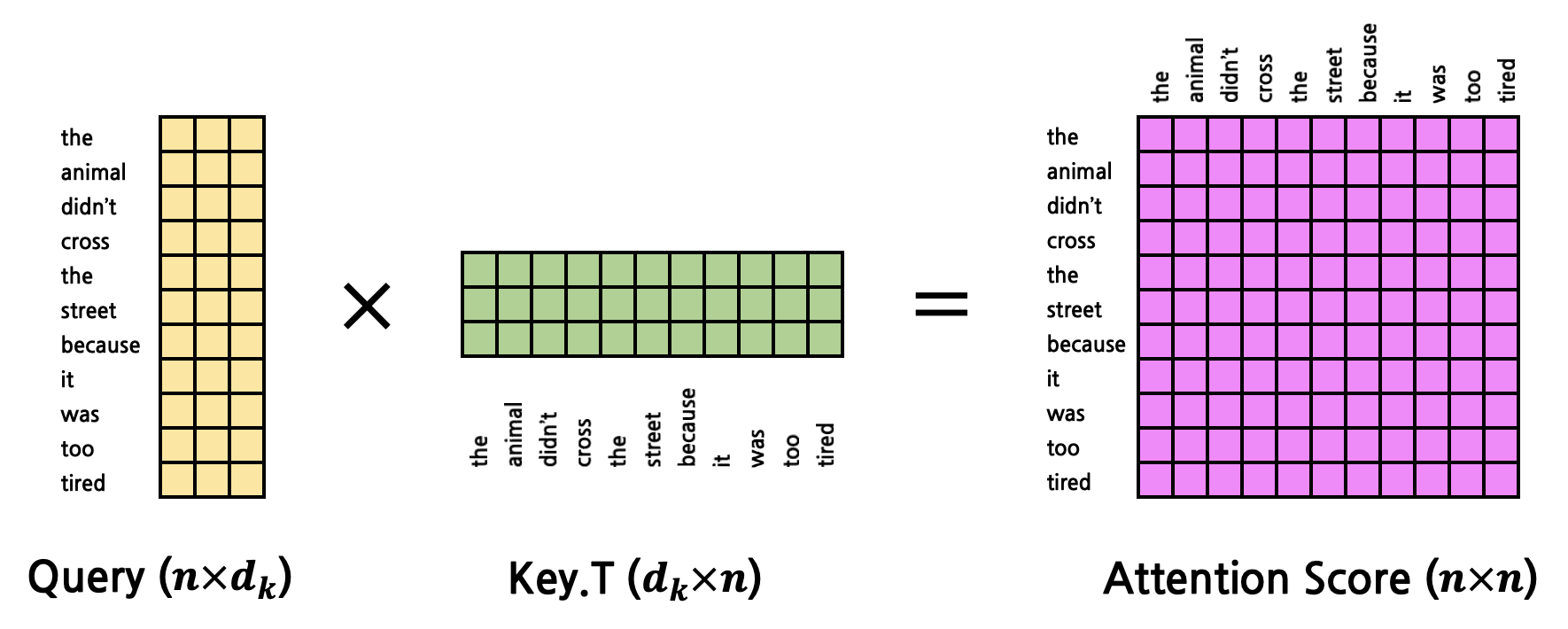
- query(15,3)
- key (18,3)
- value (18,3)
key 和 value 的 shape 必须是一致的,同时是同一个;而 query 则是其他不同的来源
Attention Score:(15,3)*(3,18)=(15,18)
-
output = attention * value=(15,18)*(18,3)=(15,3)
- 相当于使 query 看到了 key/value,注入 key/value 携带的信息到 query 中
多尺度注意力模块(multiscale attention module)
将 reference video 视为 attention 中的 “query”,而将 query video 视为 attention 中的 “key” 和 “value”。
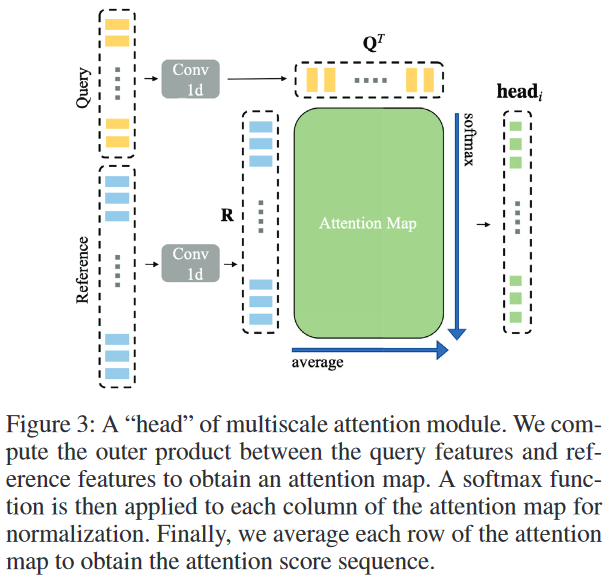
注意:
在计算 attention score 时,是在 “key”、”value” 的方向上进行 softmax ==竖着==
接着在水平方向上,对每一个 frame 对应的 attention score 进行 average(平均),作为最终的 “attention score” 赋值给 reference video 的每一个 frame
多尺度的体现
朴素的注意力机制使用 $W^Q、W^K、W^V$ 来对输入的 $Q、K、V$ 进行映射,即 \(\text{head}_i = \text{Attention}({\color{Red}QW_i^Q}, {\color{Red}KW_i^K}, {\color{Red}VW_i^V})\) 与朴素的注意力机制不同,这里使用 Conv 1d(一维卷积)来编码周围窗口的时间结构信息,即 \(\text{head}_i = \text{Attention}({\color{Green}f_i^{conv-1d}(Q)}, {\color{Green}f_i^{conv-1d}(K)}, {\color{Green}f_i^{conv-1d}(V)})\) 由于 $K$ 和 $V$ 是同一来源,可以共享同一个 Conv 1d。因此,需要使用两个不同(参数不共享)的 Conv 1d。
考虑到动作长度的巨大变化,我们在每个头部(attention head)使用 不同的内核大小和扩张率 ==多尺度的来源==
Localization Predictor(定位预测器)
与论文《Video Re-localization》思路一致,也将 Localizaiton 视为 classification 问题,并且也是四分类:
- starting point
- ending point
- action region
- background region (out of action region)
然后通过 后处理推断出确切的动作边界。
模型总览
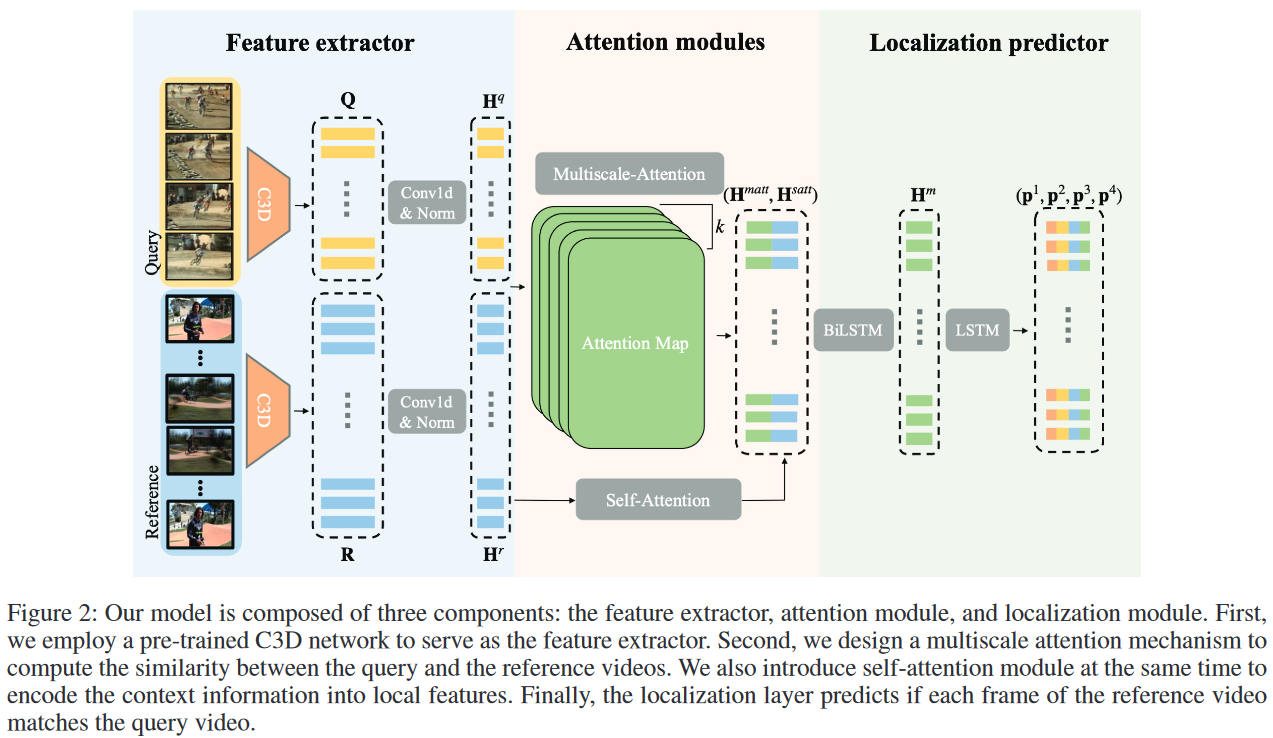
其中,$H^{matt}$ 表示 multiscale attention;$H^{satt}$ 表示 self-attention
2021
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
Clip4clip
2022
| 标题 | 方法名 | 会议 | 数据集 | 备注 |
|---|---|---|---|---|
一维卷积
一些理论
在初次接触的时候,以为是一个一维的卷积核在一条线上做卷积,但是这种理解是错的,一维卷积不代表卷积核只有一维,也不代表被卷积的 feature 也是一维。
一维的意思是说 卷积的方向是一维的。 ==至上而下==
下边首先看一个简单的一维卷积的例子(batch size是 1,也只有一个 kernel):
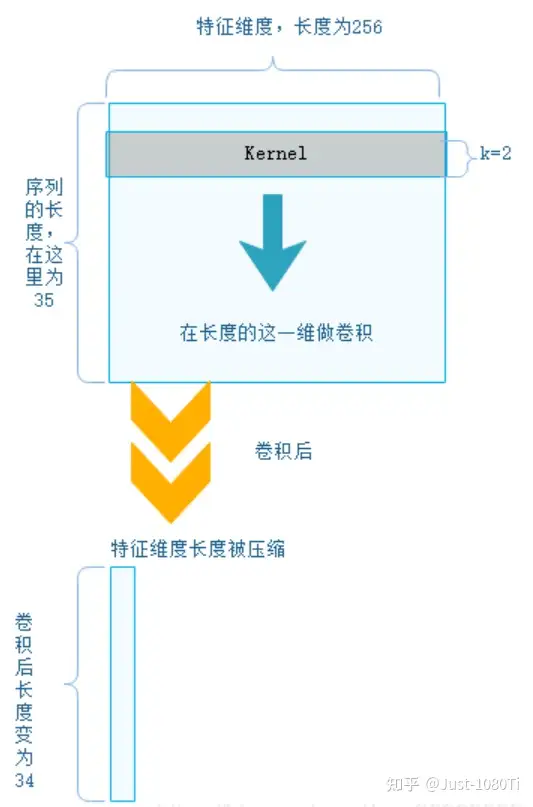
接下来我们来看一个更加具体的例子,如下图所示。

图中输入的词向量维度为 $5$,输入大小为 $7\times 5$,一维卷积核的大小 $k$ 分别是 $2、3、4$,每种卷积都有两个,总共 $6$ 个输出特征(卷积)。
对于 $k=4$,见图中红色的大矩阵,卷积核大小为 $4\times 5$,步长为 $1$。这里是针对输入 从上到下 扫一遍,输出的向量大小为 $((7-4)/1+1)\times 1=4\times 1$,最后经过一个卷积核大小为 $4$ 的 max_pooling,变成 $1$ 个值。
最后获得 $6$个值,进行拼接,在经过一个全连接层,输出 $2$ 个类别的概率。
PyTorch 原型
torch.nn.Conv1d(
in_channels,
out_channels,
kernel_size, # 卷积核的尺寸,卷积核的大小为 (k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为 kernel_size * in_channels
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros',
device=None,
dtype=None
)
kernel_size表示卷积核的尺寸。卷积核的大小为 \((k,)\),第二个维度是由 in_channels 来决定的,所以实际上 卷积核的大小为 kernel_size * in_channels
input:\((N, C_{in}, L)\),其中 \(N\) 是 batch size;\(C_{in}\) 是特征的输入维度/通道;\(L\) 是一维输入序列的长度
output:\((N, C_{out}, L_{out})\),\(C_{in}\) 是特征的输出维度/通道(卷积核个数);\(L_{out}\) 是一维输出序列的长度
注意:s
由于输出是 \((N, C_{out}, L_{out})\),这与通常使用的形式 \((N, L_{out}, C_{out})\) 不同,可以使用
permute(0, 2, 1)进行维度变换。
一个简单例子:
import torch
import torch.nn as nn
# 定义一维卷积
# (dim_in, dim_out, kernel_size, stride)
m = nn.Conv1d(16, 33, 3, stride=2)
# (bs, dim_in, L_in)
input = torch.randn(20, 16, 50)
output = m(input)
# [20, 33, 24]
# (bs, dim_out, L_out)
print(output.shape)
用途
- 不改变特征图尺寸的前提下去改变通道数(升维降维)
- 增强了 网络局部模块 的抽象表达能力(即构造更复杂的卷积核进行卷积)
参考
Pytorch 文档:torch.nn.Conv1d
CSDN:pytorch之nn.Conv1d详解
知乎问题:一维卷积应该怎么理解?
知乎问题:1维卷积核有什么作用?
Non-Local
《Non-local Neural Networks》
- URL:https://arxiv.org/abs/1711.07971
- official code:https://github.com/facebookresearch/video-nonlocal-net ==Caffe2==
- Unofficial code:https://github.com/AlexHex7/Non-local_pytorch ==PyTorch==
- 会议:CVPR 2018
- 单位:Fackbook Research(何凯明)
使用 non-local operaions 具有以下几点优点:
- 相比于 CNN 和 RNN 的逐步计算的劣势, non-local 操作 可以直接从任意两点中获取到 long-range dependencies.
- 根据实验结果可知, non-local operations 是十分高效的, 并且即使在只有几层网络层时, 也能取得很好的效果.
- 最后, 本文的 nocal operaions 会维持输入变量的尺寸大小, 并且可以很容易的与现有的其他 operations 结合使用.
- 作者用 video classification 任务来展示 non-local 的有效性. 在视频数据中, long-range interactions 不仅出现在 空间位置上的 distant pixels, 还会出现在时间维度上的 distant pixels. 通过一个单一的 non-local block (basic unit), 便可以捕获到这些 spacetime dependencies, 如果将多个 non-local block 组合起来形成 non-local neural networks, 便可以提高 video classification 任务的准确度(不加任何tricks).
- 另外, non-local 网络要比 3D 卷积网络的计算性价比更高. 为了说明 non-local 的一般性, 作者还在 COCO 数据集上进行了目标检测/分割, 姿态识别等任务的实验, 在基于 MaskRCNN 的网络基础上, 作者的 non-local blocks 可以用较少的计算开销进一步提升模型的精度.

公式描述
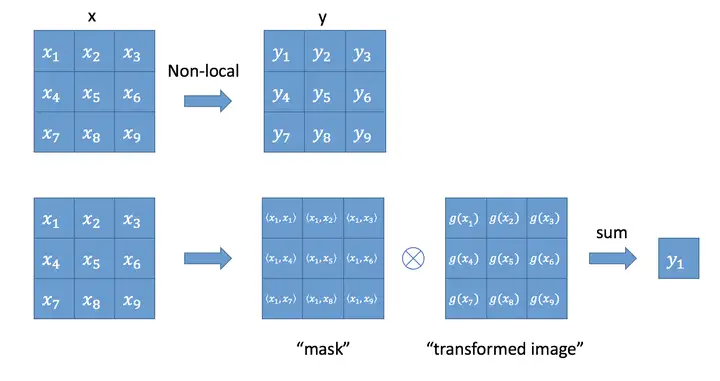
根据 non-local mean operation, 作者可以在深度卷积网络中定义如下的一般化的 non-local operation: \(\mathbf{y}_i=\dfrac{1}{\mathcal{C}(\mathbf{x})}\sum_{\forall j}f(\mathbf{x}_i,\mathbf{x}_j)g(\mathbf{x}_j)\) 其中,
- $i、j$ 分别表示位置 $i$ 和 $j$;
- $x_i$ 是第 $i$ 个位置的输入信号(一般是 feature map);
- $y_i$ 表示第 $i$ 个位置的输出(大小与 $x_i$ 一致);
- $f(\cdot)$ 会返回一个标量($x_i$ 与 $x_j$ 之间的相关性);
- $g(x_j)$ 会返回一个与 $x_j$ 大小一致的向量;
- $C(\mathbf{x})$ 用于归一化;
该公式的 non-local 特性主要体现在考虑了所有可能的 position ($∀j$), 而卷积网络只会考虑 output position 周围位置的像素点.
Non-Local Block
作者将上面介绍的公式 (non-local operation)包装进一个 non-local block 中, 使其可以整合到许多现有的网络结构当中。作者将 non-local 定义成如下格式: \(z_i = W_Zy_i + x_i\) 其中,$y_i$ 即是 non-local operation 的输出结果;$+x_i$ 表示残差连接。
文中有谈及多种实现方式,在这里简单介绍一下在 DL 框架中最好实现的 Matmul 方式(如下图所示):
- 首先对输入的 feature map $X$ 进行线性映射(说白了就是 $1\times 1\times 1$ 卷积,来压缩通道数),然后得到 $θ,φ,g$ 特征;
- 通过 reshape 操作,强行合并上述的三个特征除通道数外的维度,然后对 $θ$ 和 $φ$ 进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系);
- 然后对自相关特征进行 Softmax 操作,得到 0~1 的 weights,这里就是我们需要的 Self-attention 系数;
- 最后将 attention 系数,对应乘回特征矩阵 $g$ 中,然后再上扩展 channel 数($1\times 1$ 卷积),与原输入 feature map $X$ 做残差运算,获得 non-local block 的输出。
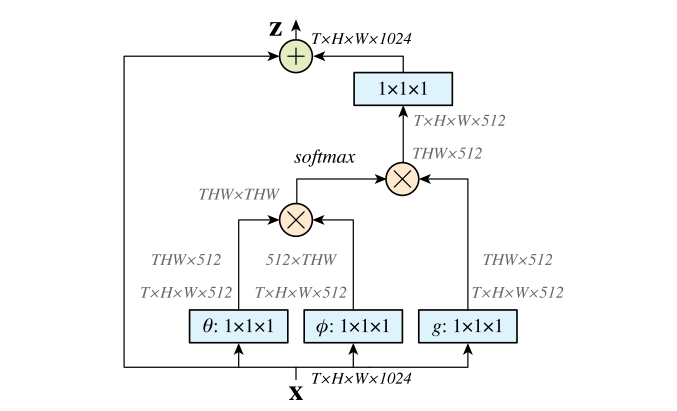
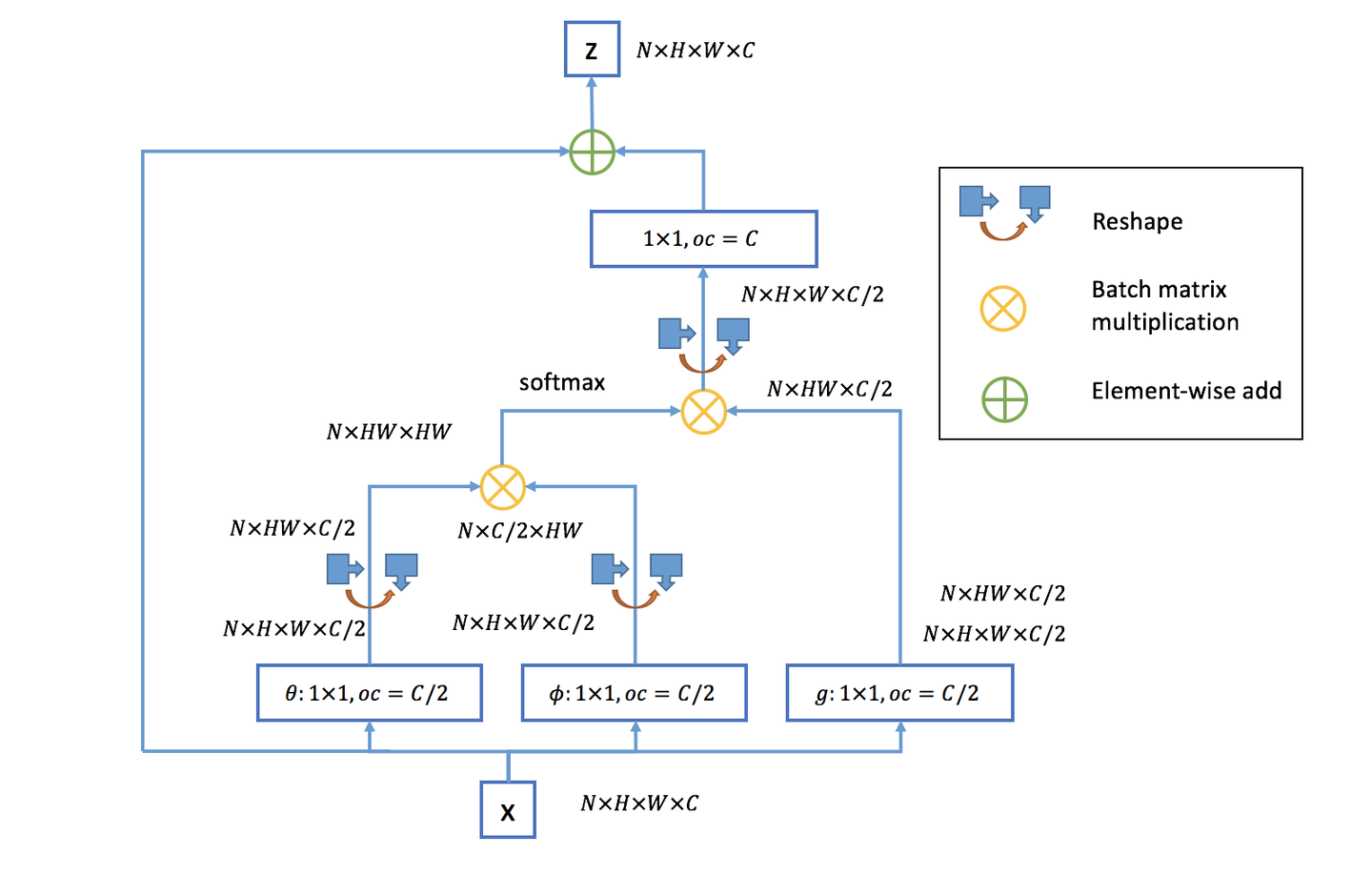
与全连接层的联系
我们知道,non-local block 利用两个点的相似性对每个位置的特征做加权,而全连接层则是利用 position-related 的 weight 对每个位置做加权。于是,全连接层可以看成 non-local block 的一个特例:
- 任意两点的相似性仅跟两点的位置有关,而与两点的具体坐标无关,即 $f(x_i, x_j) = w_{ij}$
- $g$是 identity 函数,$g(x_i) = x_i$
- 归一化系数为 $1$。归一化系数跟输入无关,全连接层不能处理任意尺寸的输入。
与机器翻译 Self Attention 的比较
Non-Local Operation: \(\mathbf{y}_i=\dfrac{1}{\mathcal{C}(\mathbf{x})}\sum_{\forall j}f(\mathbf{x}_i,\mathbf{x}_j)g(\mathbf{x}_j)\) Self Attention Operation: \(\text{Attention}(Q, K, V) = \text{softmax}(\frac{AK^T}{\sqrt{d_k}})V\) 对两个进行对比,可以发现:当 $f(\cdot)$ 函数具体化为 $\text{softmax}$,$C(x)$ 操作赋值为 $x_j$ 维度的开根号时,两个公式是等价的。此时可以看出,$f(\cdot)$ 函数中的 $x_i$ 变量等价于 Self Attention 中的 $Q$,$x_j$ 等价于 $K$,$g(\cdot)$ 函数中的 $x_j$ 等价于变量 $V$。
应用到 Video Moment Localization
在《Zero-shot Natural Language Video Localization》论文中,作者使用了 Non-Local block:
“Then, we apply Non-Local block (NL-Block) to encode the global contextual information obtained from the cross-attention module.”
我们使用 Non-Local 块(NL-Block)对从交叉注意模块获得的全局上下文信息进行编码
PyTorch 代码
借助 LGI 的代码实现,将 Non-Local 扩展为 Multi-head 版本
但是流程还是基本一致的。
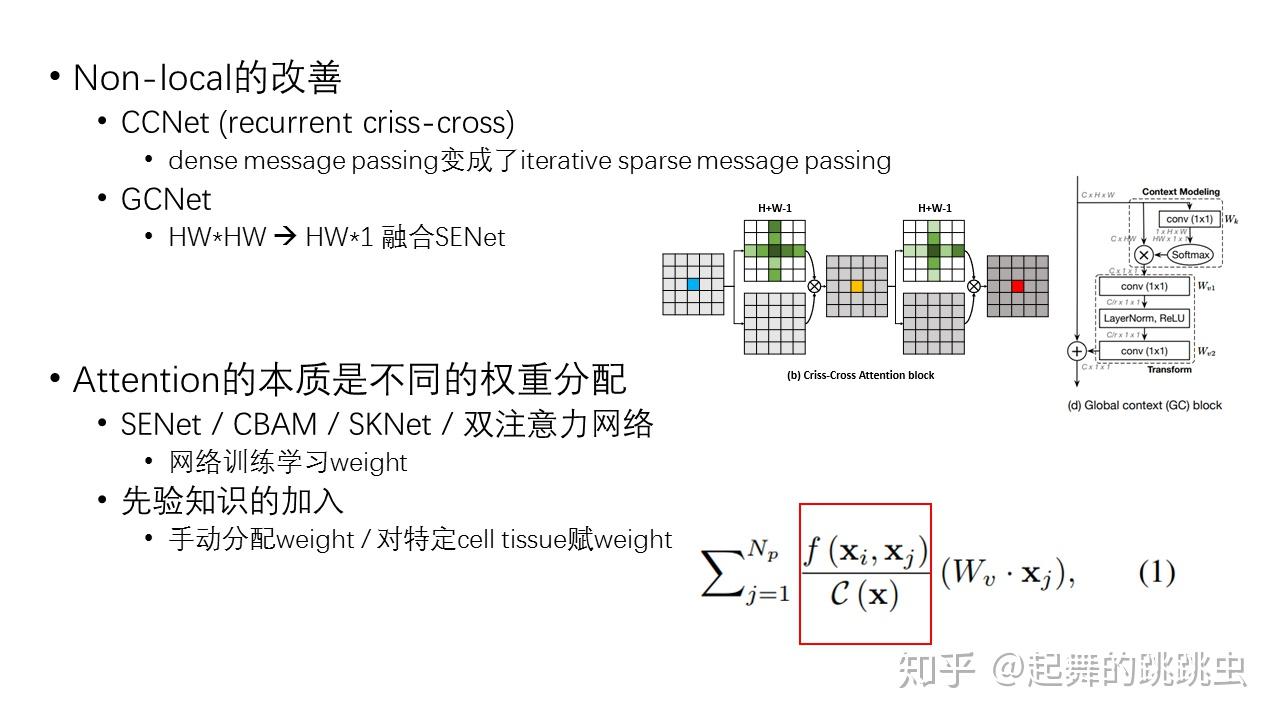
参考
Loss Function
Regression Loss(Localization Loss)
给定 predicted timestamp $(\hat{t^s}, \hat{t^e})$,ground-truth timestamp $(t^s, t^e)$ \(L_\text{Reg} = \text{Huber}(\hat{t^s} - t^s) + \text{Huber}(\hat{t^e} - t^e)\)
使用 Huber Loss(也称为 SmoothL1Loss)。
PyTorch 代码
在 PyTorch 调用 nn.SmoothL1Loss() 函数即可。
Temporal Attention Guide Loss
\(\begin{align} L_\text{att} &=-\frac{\sum_{i=1}^T \mathbb{1}_{\{t_{start}\leq i\leq t_{end}\}}\log(\mathbf{o}_i)}{\sum_{i=1}^T \mathbb{1}_{\{t_{start}\leq i\leq t_{end}\}}} \end{align}\) 其中,
- $\mathbb{1}$ 是指示函数,当 time segment 在 GT 范围内时值为 $1$,反之为 $0$;
- $\mathbf{o}_i$ 是每个时间段(time segment)的时间注意力权重
$L_\text{att}$ 鼓励模型 关注目标内的时间分段区域
该损失函数由 ABLR 首次提出的。
PyTorch 代码
Triplet Loss
关于三元损失,出自论文 FaceNet: A Unified Embedding for Face Recognition and Clustering
- 训练集中随机选取一个样本:Anchor(a)
- 再随机选取一个和Anchor属于同一类的样本:Positive(p)
- 再随机选取一个和Anchor属于不同类的样本:Negative(n)
这样 <a, p, n> 就构成了一个三元组。
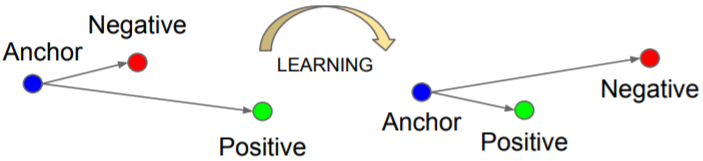
学习目标是让 Positive 和 Anchor 之间的距离 $D(a,p)$ 尽可能的小,Negative 和 Anchor 之间的距离 $D(a,n)$ 尽可能的大。
优化的目标: \(L = \max(D(a,p)-D(a,n)+\alpha, 0)\) 关于三元组,可以分为:
easy triplets:$L = 0$ 的情况(不产生 loss),$D(a, p)+\alpha<D(a, n)$,类内距离小,类间距离大,显然无需优化。
hard triplets:$D(a, n)<D(a, p)$,类间距离比类内距离还要小,较难优化,是重点照顾对象。
semi-hard triplets:$D(a, p)<D(a, n)<D(a, p) + \alpha$,类内距离和类间距离很接近,但是存在一个 margin α,比较容易优化。

Triplet Hard Loss(PyTorch 代码)
这儿介绍实际采用的 online 方法:通过在一个 mini-batch 中选择 hard positive/negative 样本来实现
from __future__ import absolute_import
import torch
from torch import nn
from torch.autograd import Variable
class TripletLoss(nn.Module):
"""Triplet loss with hard positive/negative mining.
Reference:
Hermans et al. In Defense of the Triplet Loss for Person Re-Identification. arXiv:1703.07737.
Imported from `<https://github.com/Cysu/open-reid/blob/master/reid/loss/triplet.py>`_.
Args:
margin (float, optional): margin for triplet. Default is 0.3.
"""
def __init__(self, margin=0):
super(TripletLoss, self).__init__()
self.margin = margin
# 计算两个张量之间的相似度,两张量之间的距离 > margin,loss 为正,否则loss 为 0
self.ranking_loss = nn.MarginRankingLoss(margin=margin)
def forward(self, inputs, targets):
n = inputs.size(0)
# Compute pairwise distance, replace by the official when merged
dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)
dist = dist + dist.t()
dist.addmm_(1, -2, inputs, inputs.t())
dist = dist.clamp(min=1e-12).sqrt() # for numerical stability
# For each anchor, find the hardest positive and negative
mask = targets.expand(n, n).eq(targets.expand(n, n).t())
dist_ap, dist_an = [], []
for i in range(n):
dist_ap.append(dist[i][mask[i]].max())
dist_an.append(dist[i][mask[i] == 0].min())
dist_ap = torch.cat(dist_ap)
dist_an = torch.cat(dist_an)
# Compute ranking hinge loss
y = torch.ones_like(dist_an)
loss = self.ranking_loss(dist_an, dist_ap, y)
return loss
例子:
# 假设前面一半样本是一个类别(1)
# 后面一半样本是另一个类别(2)
targets_1 = [1 for i in range(16)]
targets_2 = [2 for i in range(16)]
targets1 = torch.Tensor(targets_1).long()
targets2 = torch.Tensor(targets_2).long()
targets = torch.cat([targets1, targets2])
print(targets)
"""
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2])
"""
# (BS, hidden_dim)
inputs = torch.randint(1, 100, (32, 128)).long()
loss_fn = TripletLoss()
total_loss = loss_fn(inputs, targets)
print(total_loss.item())
"""
80.501220703125
"""
参考
- github:https://github.com/Cysu/open-reid/blob/master/reid/loss/triplet.py ==代码==
- CSDN:PyTorch TripletMarginLoss(三元损失)
CSDN:PyTorch triphard 代码理解 ==代码解释==
- PyTorch 的 Triplet-Loss 接口:torch.nn.TripletMarginLoss()
生成 Video Temporal Proposal 的方式
Random
使用 随机选择 的事件区域进行训练
Sliding window
根据以下步骤来生成 window:
将视频分成四个等长的片段
然后从一组连续片段的组合中随机选择一个进行组合
ActionByte
通过论文《ActionBytes: Learning from Trimmed Videos to Localize Actions》训练的模型来获得候选视频片段
论文的作者通过计算视频每个相邻帧之间的(3D CNN)特征差异来获取事件。这是基于视频帧之间的 3D CNN 特征在事件的边界处会发生突变的假设。
Frame Feature
Frame feature uses a method that cluster the similar CNN frame features to generate event proposals.
直接将提取的视频帧特征进行聚类,而没有 Contextualized Feature 的各种处理。
Contextualized Feature
步骤:
- 生成原子事件
- 合并原子事件
生成原子事件
首先加载从预训练好的 3D-CNN 提取的逐帧视频特征(frame-wise 3D CNN features),其中:
- Charades-STA:I3D features,1024 dim
- Activity-Captions:C3D features,500 dim
然后从逐帧视频特征中平均采样出 128 个帧视频特征;
利用这 128 个帧视频特征,构建一个相似矩阵(使用余弦相似度);
将与 帧索引(标量) 对应的 相似矩阵 的每个 列向量 定义为每一帧的 上下文特征(contextual feature);
使用 k-means 算法对上下文特征进行聚类,以得到最终的原子事件;
后处理:将任何长度短于 11 帧的帧序列集合合并到它的邻居,以删除太短的帧序列集合
合并原子事件
一旦我们有了原子事件,我们就可以通过填充连续事件的所有组合来生成 复合事件,然后按照 均匀分布 对一些事件进行采样。
具体来说,这里考虑三种评分函数来合并连续的原子事件:
- 原子事件的紧凑性(atomic event’s compactness)
- 对于某个选定的视频片段,首先计算该候选视频片段的平均特征值,然后利用这一平均特征值与其他视频片段特征值的差异(均值),这一差异值就是最终的得分。选择 top-k 个视频片段进行合并。
- 原子事件的多样性(atomic event’s diversity)
- 与紧凑性相似,只是选择的是 bottom-k 个视频片段进行合并
- 均匀随机采样(uniform random sampling)
- 连续原子事件的组合中 随机采样
- 效果最好!
- 作者的解释:它包含紧凑和多样化的事件组合,能够更好地覆盖数据集地分布
- 均匀采样 128 个 frame features
- 然后计算这 128 个 features 的 similarity matrix
- 然后再聚类
Prompt
Prompt Learning 的本质:
将所有下游任务统一成预训练任务;以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。
本质上就是 设计一个比较契合上游预训练任务的模板,通过模板的设计就是 挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,包括 3 个关键步骤:
- 设计预训练语言模型的任务
设计输入模板样式(Prompt Engineering)
- 设计 label 样式 及模型的输出映射到 label 的方式(Answer Engineering)
提示模板的 作用 就在于:
- 将训练数据转成自然语言的形式,并在合适的位置上 MASK,以 激发 预训练模型的能力。
来源:
- 知乎:https://www.zhihu.com/question/504324484/answer/2857106275
NLP
硬模板方法:
PET(Pattern Exploiting Training)==开篇之作==
LM-BFF
硬模板的缺陷:
硬模板产生依赖两种方式:根据经验的人工设计 & 自动化搜索。
但是,人工设计的不一定比自动搜索的好,自动搜索的可读性和可解释性也不强。
软模板方法:
为了解决手工设计模板的缺点,许多研究开始探究如何自动学习到合适的模板。自动学习的模板又可以分为 离散(Discrete Prompts)和连续(Continuous Prompts)两大类。
离散的主要包括:
- Prompt Mining
- Prompt Paraphrasing
- Gradient-based Search
- Prompt Generation
- Prompt Scoring
连续的则主要包括:
- Prefix Tuning
- Tuning Initialized with Discrete Prompts
- Hard-Soft Prompt Hybrid Tuning
——来源:知乎




Visual
Visual Prompt Tuning(VPT)
《Visual Prompt Tuning》
- URL:https://arxiv.org/abs/2203.12119
- official code:https://github.com/KMnP/vpt
- Unofficial code:https://github.com/sagizty/VPT(国内大佬的复现)
- 单位:康奈尔大学、Meta AI
- 会议:ECCV 2022

目前调整预训练模型的方法是 full fine-tuning,即完全微调。本文介绍 Visual Prompt Tuning(VPT)作为一种有效的用于大规模 Transformer 的视觉微调。它只需要在输入空间引入少量(不到 $1\%$ 的模型参数)的可训练参数,同时冻结 backbone。会发现在很多情况下,优于完全微调。
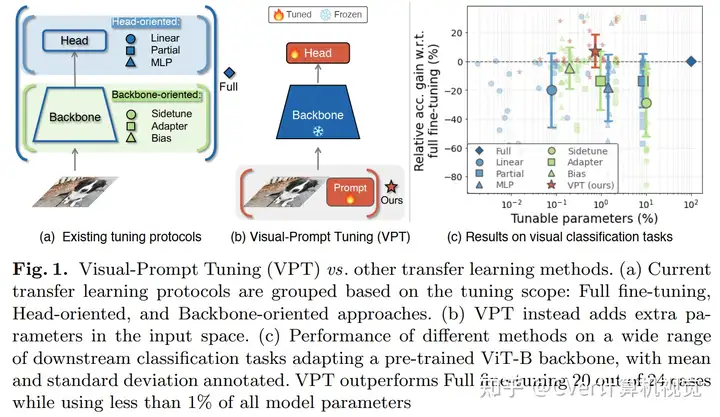
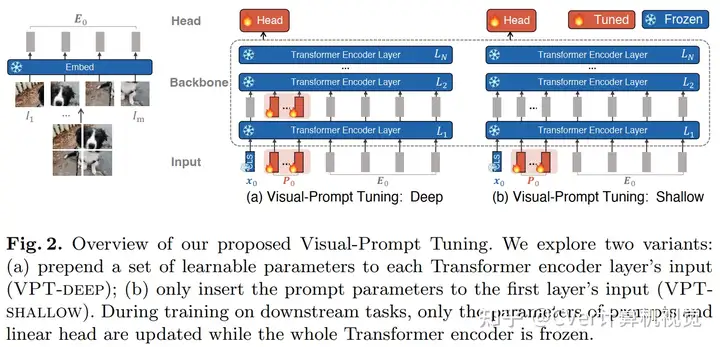
VPT-Shallow Prompt 仅插入第一层,每一个 prompt token 都是一个可学习的 $d$ 维向量,所有的 prompt tokens 集合表示如下:
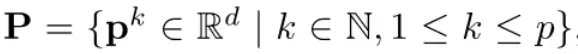
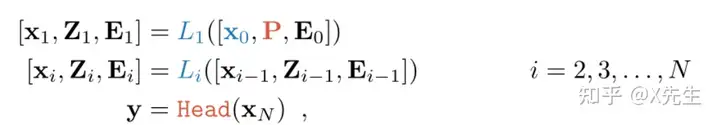
VPT-Deep Prompt 被插入到每一层的输入中:
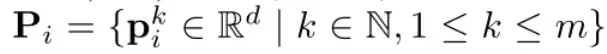
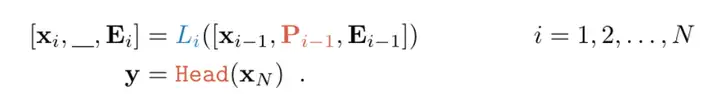
VPT 对于多个下游任务都是有帮助的,只需要为每个任务存储学习到的 prompt 和分类头,重新使用预训练的 Transformer,从而显著降低存储成本。
参考:
Multimodal
CoOp
《Learning to Prompt for Vision-Language Models》
- Official Code:https://github.com/kaiyangzhou/coop
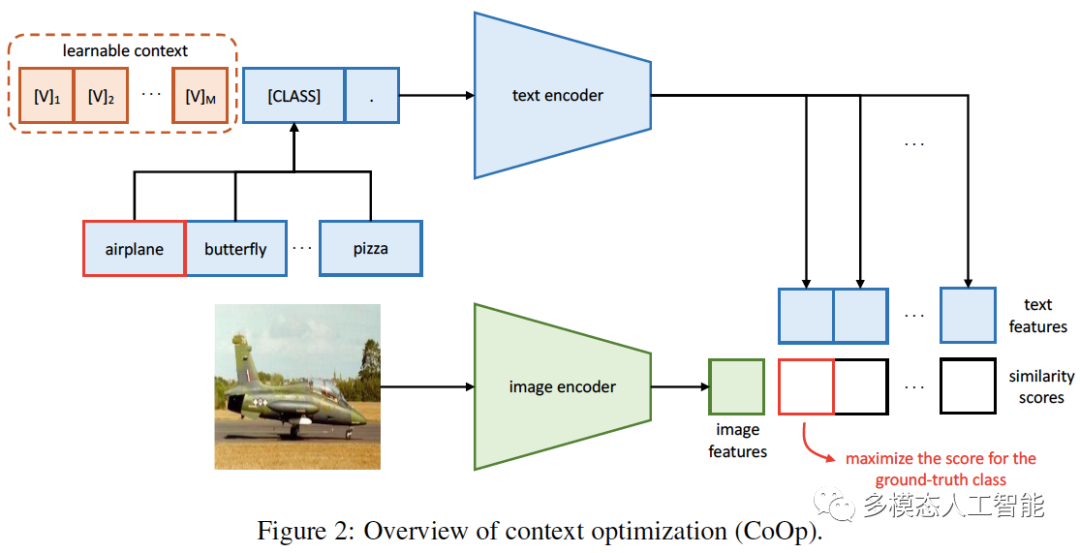
代码
在 CLIP 中,使用 nn.Embedding() 来表示词典:
# ./clip/model.py
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
生成可学习的 Prompts:
# coop.py -> PromptLearner
# random initialization
if cfg.TRAINER.COOP.CSC:
print("Initializing class-specific contexts")
ctx_vectors = torch.empty(n_cls, n_ctx, ctx_dim, dtype=dtype)
else:
print("Initializing a generic context")
ctx_vectors = torch.empty(n_ctx, ctx_dim, dtype=dtype)
nn.init.normal_(ctx_vectors, std=0.02)
prompt_prefix = " ".join(["X"] * n_ctx)
# Learnable
self.ctx = nn.Parameter(ctx_vectors) # to be optimized
CoCoOp
《CoCoOp: Conditional Prompt Learning for Vision-Language Models》
- URL:https://arxiv.org/abs/2203.05557
- Official Code:
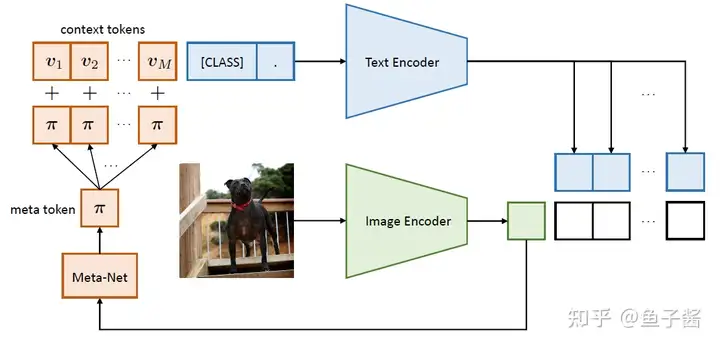
相比于 CoOp,CoCoOp 增加了一个 轻量级网络(Meta-Net)$h_{\theta}(\cdot)$,Meta-Net 的输入是 image feature � ,输出则是一个 instance-conditional token $\pi$,然后再在每个 context token $v_m$ 上加上 $\pi$: $$ \begin{align} v_m(x) &= v_m + \pi \
\pi &= h_{\theta}(x) \ \ m\in {1,2,…,M}
\end{align} \(于是,text encoder 的 input 就变成:\) t_i(x) = {v_1(x), v_2(x), …, v_M(x), c_i} $$
MaPLe: Multi-modal Prompt Learning
《MaPLe: Multi-modal Prompt Learning》
- Official Code:https://github.com/muzairkhattak/multimodal-prompt-learning

Modular and Parameter-Efficient Multimodal Fusion with Prompting
《Modular and Parameter-Efficient Multimodal Fusion with Prompting》
- URL:https://arxiv.org/abs/2203.08055
- 单位:慕尼黑大学(德国)
- 会议:ACL 2022
- 主页:https://aclanthology.org/2022.findings-acl.234/
- Code:https://aclanthology.org/attachments/2022.findings-acl.234.software.zip
写的非常的清晰易懂、简洁又很详细!对初学者很友好!
Prompt 的两大优势:
- 高度模块化(high modularity)
- 让 Visual Encoder 专注于 Visual Representation 工作
- 让 Learnable Prompt Vectors 承担 模态对齐 任务
- 参数效率(parameter efficiency)
- 只需微调很少的参数,就能在 Few-Shot 场景下达到很高的性能
前言
Recent research has made impressive progress in large-scale multimodal pre-training. In the context of the rapid growth of model size, it is necessary to seek efficient and flexible methods other than finetuning. In this paper, we propose to use prompt vectors to align the modalities. Our method achieves comparable performance to several other multimodal fusion methods in low-resource settings (Few-Shot or even Zero-Shot settings). We further show that our method is modular and parameter-efficient for processing tasks involving two or more data modalities.
整体结构
实验
作者在两种模态(text、image)的 VQAv2 数据集和三种模态(text、video、audio)的 MUStARD 数据集上进行实验。
We apply the Integrated Gradients(积分梯度) method, which measures the attribution of features to the neural network outputs.
In practice, we use the Captum package in our implementation.
Domain Adaptation via Prompt Learning(域适应)
Domain Adaptation via Prompt Learning
- URL:https://arxiv.org/abs/2202.06687
用 prompt 来标识 domain 的信息!

通过对比学习解耦 representation 中的 class 和 domain 的表示
Prompt Tuning

P-tuning
Prefix-tuning
Prompt-tuning
P-tuning v2
PPT
CPT:Cross-modal Prompt Tuning
《CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models》
- URL:https://arxiv.org/abs/2109.11797
Prompt Tuning for Generative Multimodal Pretrained Models
Prompt Tuning for Generative Multimodal Pretrained Models
- URL:https://arxiv.org/abs/2208.02532
- Code:https://github.com/OFA-Sys/OFA/blob/main/prompt_tuning.md
- 单位:阿里达摩院
前言
In this work, we explore prompt tuning for generative multimodal pretrained models. Through extensive experiments, we demonstrate that the light-weight prompt tuning can achieve comparable performance with finetuning with much fewer parameters to tune (e.g., 1%), and it can surpass other light-weight tuning methods, e.g., Adapter and BitFit.
Through our analysis, we figure out a significant advantage of prompt tuning about its robustness against adversarial attack. Furthermore, we provide a comprehensive analysis about the influence of prompt tuning setups, including the prompt length, prompt depth, and reparameterization. Potentially prompt tuning can be an alternative to finetuning, but still, there are some salient limitations in this method, e.g., slow convergence and training instabilities. We hope that future studies in this field can alleviate the aforementioned problems and thus promote the application of prompt tuning.
整体结构
The cross-attention is essentially multi-head attention, where the keys $$K$$ and values $$V$$ are the transformation of the encoder output states, instead of the inputs.
这里默认使用的是 prefix-tuning 的方式,将 prompt 插入到 prefix。其他的插入方式 middle、end 效果差不多,因此,作者这里就直接使用了 prefix-tuning。
实验
1)与 Finetuning 进行比较
2)与其他 efficient tuning methods 进行比较
3)鲁棒性分析
4)消融实验
Prompt Length 的影响
使用了 \(\{10, 16, 30, 64, 100, 120\}\) 这几种不长度的 prompt 序列。
论文默认使用的 Prompt Length = 64(最佳性能)
Prompt Depth 的影响
将 Prompt 插入到三个不同的位置,包括:Encoder-Only、Decoder-Only 以及 Encoder-Decoder。
Reparameterization 的影响
根据经验,直接更新可训练嵌入 会导致 不稳定的训练 和 性能的轻微下降。之前的工作通常利用编码器(例如 MLP)来重新参数化可训练的嵌入。
讨论
尽管 Prompt Tuning 有很多的优点,但是仍然无法完全替代 Fine-Tuning。主要的局限性包括:
- 收敛速度慢(slow convergence)
- 需要 更多的 epochs,才能达到 Fine-Tuning 同等的性能
- 虽然 Prompt-Tuning 的训练效率高,但是 更多的训练 epochs 也可能导致更多的计算成本
- 这也表明:除了达到与 Fine-Tuning 相当甚至改进的性能外,能够快速、稳定收敛的方法也很重要(速度与稳定之间的 trade-off)
- 难以找到合适的超参数设置(suitable hyperparameter setup)
Despite the aforementioned limitations, prompt tuning demonstrates significantly better robustness against adversarial attack.
尽管存在上述局限性,prompt tuning 能够更好的防御对抗攻击,提高模型的鲁棒性。
参考
- HNU 的 yawenzeng 程序媛(Tencent Inc.)
部分 SOT 方法的代码:Temporally-language-grounding
- Awesome:Temporal Language Grounding
text-video retrival:
video-video retrival:有两种想法
- 直接法:query video -> video
- 间接法:query video -> query caption/text -> video
- query video 相比于 video,长度短很多(不是一个数量级),可以使用更轻量化/更窄的模型来提取特征
特征提取: 文本:采用基于预训练好的 Transformer 的模型(BERT、RoBERTa) 视频:看数据集,一般使用 3D Conv 进行提取
多尺度的双流 Transformer 模态交互 不仅句子可以调节、选择视频;视频也可以反向选择和调节查询句子; 通常情况下,视频包含时序性、表现型、光流性、声音等比自然语言更加丰富的信息,所以仅靠一次交互很难捕捉到想要的内容; 多尺度视频级别 Features(类似 MS-2D-TAN);片段级别 Features; Video-Query Attention Query-VIdeo Attention
结果预测:![]() 同时结合 Prompt-Learning 和 Query-Reconstruction(Recaption)来进行视频时刻定位 通过模型预测的 既能够同时使用有监督、弱监督的数据集,同时又能够保留(maintain)现有的有监督数据集提供的准确性(尽管数据集中存在偏差/误差)
同时结合 Prompt-Learning 和 Query-Reconstruction(Recaption)来进行视频时刻定位 通过模型预测的 既能够同时使用有监督、弱监督的数据集,同时又能够保留(maintain)现有的有监督数据集提供的准确性(尽管数据集中存在偏差/误差)
如何使用目前预训练好的多模态大模型的能力?
Proposal-based: Sliding Windows(SW) Proposa Generated(PG)
第 40 个 Epoch,出现梯度消失(在 s_fusor)
–>name: s_fusor.layers.0.attention.in_proj_weight –>grad_requirs: True –weight tensor(-1.1556e-09, device=’cuda:0’) –>grad_value: tensor(0., device=’cuda:0’)
–>name: non_locals_layer.0.v_lin.weight –>grad_requirs: True –weight tensor(-1.6835e-09, device=’cuda:0’) –>grad_value: tensor(0., device=’cuda:0’) 【将 torch.tanh() 修改为 ReLU(),修改完上述问题消失】
但是出现了新的问题: –>name: s_fusor.layers.1.convbnrelu.module.1.weight –>grad_requirs: True –weight tensor(0.8309, device=’cuda:0’) –>grad_value: tensor(0., device=’cuda:0’) 【不再使用 FusionConvBNReLU,而是使用 FusionresBlock,将配置文件的 use_resblock 改为 True】
2023.03.05
Pytorch 线性层采取的默认初始化方式是 Kaiming 初始化,这是由我国计算机视觉领域专家何恺明提出的。
梯度裁剪
1)对于有标注的数据集,使用 prompt learning 将现有的预训练大模型强大的能力迁移到 TVG 下游任务上。(有监督的方式 + prompt tuning)
设计更好的自动生成的 prompt;预训练大模型;多模态;loss 设计
2)无监督的方式:生成伪监督信号
- 伪视频时刻信号:视频时刻片段生成!
- 伪查询语句:通过 Video Captioning 任务来生成!逆向通过 Video Captioning 来辅助 TVG 任务
之前的工作借助 CLIP 在 visual 和 text 上很强的对齐能力;Video Captioning 能够更好的对齐 Video 和 text(可解释性更强?);
尝试在更大的模型上进行预训练(之前的工作并没有进行尝试)
BSP 通过设计边界敏感前置任务并收集具有时间边界的合成数据集,提出了 TSGV 的预训练范式。
GTR 构建了一个端到端的框架来直接从原始视频中学习 TSGV GTR builds an end-to-end framework to learn TSGV from raw videos directly.
2023.03.06
[CLS] the text of [Q], starts at frame [S] and ens at frame [E]. [SEP] 其中 [S] 和 [E] 是 [MASK] 因为这里只有一个输入句子,所以不需要 [SEP] 也可!
效果最好的模型:使用人工设计的提示模板,PPT 变体:PPT-PS,使用 [Q], start [S] end [E] 模板 作者探索的变体:PPT-P,使用 [Q][S][E] 的提示模板 作者也探索了变体:PPT-PC [C][Q][C][S][C][E]的提示模板,其中 [C] 是一个 learnable token(可以被自动生成,无需人工设计) 但是,
- 作者并没有在模板中添加关于视觉的条件, (借鉴 CoCoOp,针对每一个不同的输入,得到不一致的 Prompt 模板)
- 改进做法:使用预训练的 CLIP Image Encoder/ViT 对 Video frame Feature 序列进行交互,然后将输出的 Video Pooled Feature 作为条件送入一个函数转换器,将特征进行编码,然后添加到需要学习的 Learnable Token ==仿照 CoCoOp 的做法==
- 作者也没有对预训练的模型进行微调 (借鉴 Visual Prompt Tuning,VPT、Prefix-Tuning 等轻量化微调方法)
如果要做大规模数据集的预训练,需要预先提取视频特征,目标数据集:HowTo100M
2023.03.08
使用 HowTo100M 来预训练很难,视频数据集很大(一百万个视频,估计得有至少两三百万个候选片段)
-> 模型的深度、宽度要增加 -> 训练/炼丹技巧用上
如果成功进行预训练,可以将其用到基于 prompt 的方法中
2023.03.16
长截图插件:Full Page Screen Capture 下载地址:https://chrome.google.com/webstore/detail/gofullpage-full-page-scre/fdpohaocaechififmbbbbbknoalclacl
划词翻译: 下载地址:https://chrome.google.com/webstore/detail/%E5%88%92%E8%AF%8D%E7%BF%BB%E8%AF%91/ikhdkkncnoglghljlkmcimlnlhkeamad/ 文档:https://hcfy.app/docs/guides/welcome
参考:
文档信息
- 本文作者:Bookstall
- 本文链接:https://bookstall.github.io/2023/02/08/video-retrival-paper/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)